XYZ“三原色”,助力AI决策类人化( 二 )
【XYZ“三原色”,助力AI决策类人化】在第二阶段 , 我们对预训练的模型进行了微调 , 以教会这个模型如何组成句子 。 这个自动图像描述功能目前已经集成到了 Office 365、LinkedIn 等广受欢迎的微软产品中 , 欢迎大家使用 。 此外 , 还有一款名为 Seeing AI 的手机应用 , 正在为视力受损或丧失的人群提供服务 。 在 Office 365中 , 当你将一张图像粘贴到 PowerPoint、Word 或 Outlook 中时 , 都会看到“替代文本”这个选项 。 这在易用性方面也大有裨益 , 因为图像所附的替代文本可以通过屏幕阅读器朗读出来 。
Z 代码:利用迁移学习和语言的共同特性Z 代码也可称为多语言 , 其灵感来自于我们希望为全社会消除语言障碍的愿景 。 Z 代码通过为一系列语言启用基于文本的多语言神经网络翻译 , 来扩展单语言的 X 代码 。 由于进行了迁移学习 , 而且相似语言之间存在共同的语素 , 所以我们显著地改善了质量 , 降低了成本 , 并提高了 Azure 认知服务中机器翻译功能的效率(更多详细信息 , 见图4) 。
借助 Z 代码 , 我们正在利用迁移学习的能力 , 提高低资源语言的质量 。 低资源语言是指训练数据中所含语句数量少于100万的语言 。 我们旨在覆盖大约1,500个低资源语言 。 随着语言覆盖范围的扩大 , 这些语言可用训练数据的缺乏所带来的限制与日俱增 。 为了克服这个难题 , 我们通过多语言合并以及使用 BERT 式的掩码语言模型开发出了多语言神经网络翻译 。
在 Z 代码中 , 我们把 BERT 视为将掩码语言翻译成初始语言的另一项翻译任务 。 由于进行了迁移学习以及相似语言之间的共享 , 因此我们可以用更少的数据极大地提升翻译质量 , 降低成本 , 并提高效率 。 现在 , 我们可以使用 Z 代码来改进翻译和一般自然语言理解任务 , 例如多语言命名的实体抽取等 。 无论人们使用何种语言 , Z 代码都可以帮助我们提供嵌入其中的通用语言 。 Z 代码可谓“天生就是多语言的” 。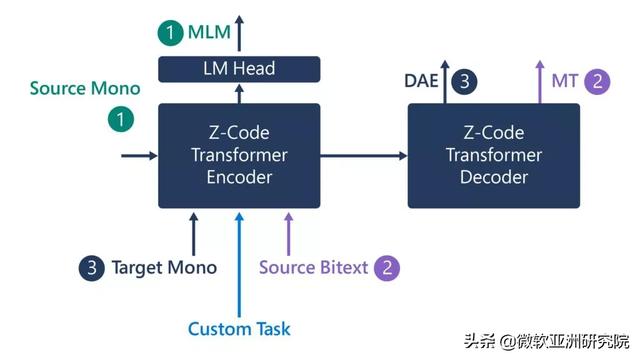 文章插图
文章插图
图4:Z代码架构图 。
Z代码以两种方式使用迁移学习 。 首先 , 该模型使用多语言训练 , 这样知识可以在多个语言之间实现迁移 。 其次 , 我们使用多任务训练 , 让知识在不同任务之间迁移 。 例如 , 机器翻译任务(MT)可以为自然语言理解任务提供帮助 , 而掩码LM任务(MLM)或去噪自动编码器任务(DAE)可以为机器翻译任务提供帮助 , 以此类推 。
现实挑战 , 激发 AI 创新多语言语音识别或翻译是应用 XYZ 代码的实际情境之一 , 无论这涉及到的是简单的电梯多语言语音控制 , 还是向欧盟议会提供支持(其成员使用24种欧洲官方语言) 。 我们通过开发基于 AI 的工具 , 努力克服语言障碍 , 实现了对欧洲议会辩论的自动实时转录和翻译 , 并且能够从人工的校对和编辑中进行学习 。
在15世纪中期 , 德国发明家约翰内斯·古腾堡(Johannes Gutenberg)造出了第一台印刷机 。 古腾堡印刷机通过把金属质地的活字模组合成单词 , 从而使大规模印刷书面材料成为了可能 。 这一进步让人类能够广泛地传播和分享知识 。 我们的团队正是从古腾堡身上汲取了灵感 , XYZ 代码的研发工作将 AI 功能分解成了细小的“积木” , 以独特的方式进行组合 , 让集成 AI 变得更加有效 。
作为历史上最重要的发明之一 , 古腾堡印刷机极大地改变了社会的演进方式 。 我相信 , 我们正处于与之相似的 AI 功能“复兴”过程之中 。 在当今的数字化时代 , 我们的雄心壮志是开发出可以像人类一样学习和推理的技术 , 也就是说 , 让技术能够更像人类在做出决策时那样 , 对情境和意图进行推断 。
尽管我们志存高远 , 但对 XYZ 代码的研究仍需脚踏实地 , 向着既定目标迈进 。 正如古腾堡印刷机彻底变革了人类信息传播的过程一样 , 我们希望研发出能够更好地与人类能力相匹配的 AI , 并不断推动 AI 向前发展 。
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 产业|前瞻生鲜电商产业全球周报第67期:发力社区团购!京东内部筹划“京东优选”
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 面临|“熟悉的陌生人”不该被边缘化
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限