XYZ“三原色”,助力AI决策类人化
编者按:人类认知的三大属性包括:单语言文本(X) , 音频或视觉感官信号(Y)和多语言文本(Z) 。 微软通过研究 X、Y、Z 三个领域的交汇处 , 发现了实现 AI 能力又一次飞跃的可能——以更接近人类的学习和理解方式进行多感知和多语言学习 。 本文编译自微软技术院士、微软 Azure 认知服务首席技术官黄学东发表在微软研究院博客的署名文章“A holistic representation toward integrative AI” 。
在微软 , 我们一直在寻求通过更全面、以人为本的方法去解决机器的学习和理解问题 , 以超越现有技术的限制 , 推进 AI 发展 。 作为微软 Azure 认知服务首席技术官 , 我一直与一支由顶尖的科学家和工程师组成的团队通力合作 , 力争实现这一目标 。
由于工作角色的关系 , 我能够以独特的视角观察人类认知三大属性之间的关系:单语言文本(X) , 音频或视觉感官信号(Y)和多语言文本(Z) 。 在这三者的交汇处 , 存在着一种魔力 , 我们称之为 XYZ 代码 , 如图1所示 。 这种联合描述将能够创造更强大的 AI , 可以更好地表达、倾听、观察和理解人类 。 我们相信 , XYZ 代码将有助于我们实现长期的人工智能愿景:跨领域、跨模式和跨语言的迁移学习 。 我们的目标在于研发出共同学习表征的预训练模型 , 进而为广泛的下游 AI 任务提供支持 , 而这与人类今天的工作方式非常相似 。
过去五年间 , 我们在对话式语音识别、机器翻译、对话式问答、机器阅读理解和图像描述等基准测试中都取得了能够与人类媲美的成绩 。 这五项技术突破让我们更加满怀信心地渴望实现 AI 能力的又一次飞跃——以更接近人类学习和理解的方式进行多感知和多语言学习 。 我相信 , 如果有下游 AI 任务中的外部知识作为支撑 , XYZ 代码将成为实现这个愿望的基本要素 。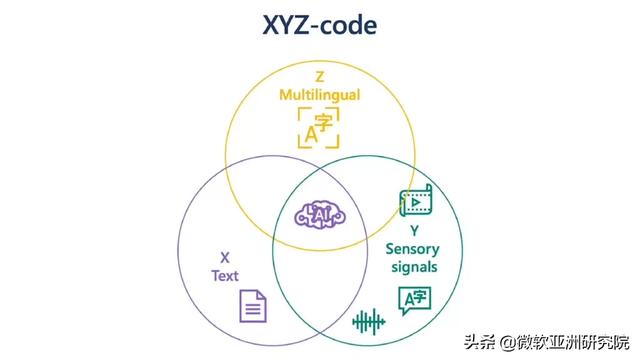 文章插图
文章插图
图1:旨在实现 AI 功能飞跃的 XYZ 代码 。 我们可以通过 X、Y、Z 三个领域的交叉获得更强大的表示形式 。
X 代码:基于大数据的文本表示X 代码旨在实现单语言文本通用表示 。 早在2013年 , 我们就通过语义嵌入最大化必应搜索查询词和与之相关的文档的互信息 , 其得到的文本表示即为 X 代码 。 X 代码很快就转化至微软必应搜索服务推向了市场 , 但当时其架构(如图2所示)并未公布 。 近1-2年来 , 在基于 Transformer 的神经模型(例如 BERT、图灵和 GPT-3)的加持下 , X 代码对基于文本的单语言预训练起到了显著的提升作用 。
X 代码将查询词(字)和文档映射到高维意图空间中 。 我们以500亿个无重复的查询-文档对作为训练数据 , 对这些表示的互信息加以最大化 , X 代码成功学会了大规模查询与文档之间的语义关系 , 并且在搜索排名、广告点击预测、查询之间相似度以及文档分组等各种自然语言处理任务中展现出了优越的性能 。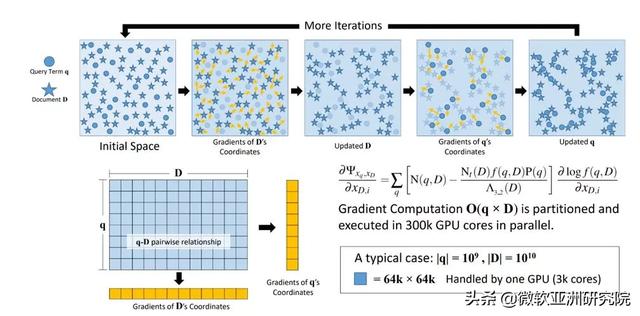 文章插图
文章插图
图2:早在2013年 , X 代码通过互信息的最大化以改善大规模语义文本的表示学习 。
我们通过查询及 URL 表示的联合优化 , 利用搜索引擎点击日志对其进行训练 。 在嵌入空间 , X 代码捕获到其中单词和 Web 文档的相似性 , 进而用于各种自然语言处理任务 。 图示来自2013年的原始架构 。
Y 代码:加入视觉和听觉信号的力量我们对感知 AI 的探索及努力全都囊括在了 Y 代码之中 。 我们用 Y 指代音频或视觉信号 。 对 X 和 Y 属性的联合优化有助于图像描述以及语音、表格或 OCR 识别 。 通过 XY 联合代码或单纯的 Y 代码 , 我们旨在对文本、音频或视觉信号进行共同优化 。
在最近的 NOCAPS 基准测试中 , 通过我们的努力 , Y 代码在图像描述上的表现超越了人类 , 其架构如图3所示 。 通过该架构 , 我们能够从视觉信息中确定新物体 , 并增加一个语言理解层组成描述它们之间关系的句子 。 在很多情况下 , 这比人类写的描述更加准确 。 NOCAPS 上的突破表明 , X 和 Y 属性之间的交集可以极大地帮助我们在下游 AI 任务取得额外的提升 。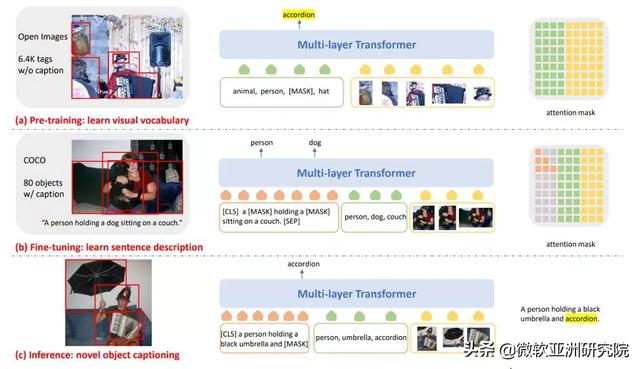 文章插图
文章插图
图3:应用于图像描述的 Y 代码架构(2020年) 。
为了实现 NOCAPS 上的突破 , 我们预训练了一个大型 AI 模型 , 用于文本和视觉模式的语义对齐 。 训练使用的数据集由带文字标签的图像进行增强 , 而不仅仅是完整的图片描述 , 因为它们更易于构建 , 而且学习的视觉词汇量也更加丰富 。 这就像教孩子们读书一样 , 向他们解读一本图画书时 , 将苹果的图片与 “苹果”这个单词关联起来 。
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 产业|前瞻生鲜电商产业全球周报第67期:发力社区团购!京东内部筹划“京东优选”
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 面临|“熟悉的陌生人”不该被边缘化
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限