从神经机器翻译器到引导移动GUI的实现( 四 )
4. 构建 ANDROID UI 数据集要训练我们的神经机器翻译器 , 我们需要从现有的移动应用中获取大量的 UI 图像和 GUI 框架对 。 这要求我们浏览应用程序的 GUI , 获取 UI 屏幕截图 , 获取运行时 GUI 组件层次结构 , 并将屏幕截图与组件层次结构相关联 。 尽管某些工具(例如 Apktool , UI Automator)可以协助完成这些任务 , 但它们都无法自动化整个数据收集 。 受自动化 GUI 测试技术的启发 , 我们开发了一种称为 Stoat 的自动化技术来探索 GUI 。 在探索期间 , 将自动转储 UI 屏幕截图及其相应的运行时 GUI 组件层次结构 。 转储的 UI 图像和相应的 GUI 组件层次结构类似于图 2 中的示例 。
Stoat 使用 Android 模拟器(已配置为流行的 KitKat 版本 , SDK 4.4.2 , 屏幕尺寸为 768×1280)来运行 Android 应用 。 它使用 Android UI Automator 转储成对的 UI 图像和相应的运行时 GUI 组件层次结构 。 Soot 和 Dexpler 用于静态分析 。Stoat 在具有 32 个 Intel Xeon CPU 和 189G 内存的 64 位 Ubuntu 16.04 服务器上运行 , 并行控制 16 个仿真器来收集数据(每个应用程序运行 45 分钟) 。
我们从 Google Play 抓取了具有最高安装数量的 6000 个 Android 应用 。Stoat 成功运行了 5043 个应用 , 它们属于 25 个类别 。 图 4(a)显示了每个类别中的应用程序数量 。 其他 957 个应用程序需要额外的硬件支持或第三方库 , 而模拟器中没有这些库 。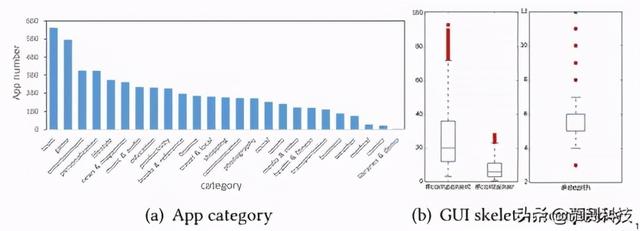 文章插图
文章插图
图 4:Android UI 数据集统计
Stoat 总共收集了 185,277 对 UI 图像和 GUI 框架(每个应用平均约 36.7 对) 。 这个 UI 数据集用于训练和测试我们的神经机器翻译器(请参阅第 6 节) 。 收集的 GUI 框架使用 291 个独特的 Android GUI 组件 , 包括 Android 的本机布局和小部件以及来自第三方库的组件 。 图 4(b)中的方框图显示了收集到的 GUI 框架的复杂性 , 差异很大 。
GUI 框架平均具有 24.73 个 GUI 组件 , 7.43 个容器(非叶组件)和 5.43 层(从根到叶组件的最长路径) 。
5. 评估我们从以下三个方面评估我们的神经机器翻译器:准确性 , 通用性和有用性 。
5.1 准确性评估我们使用随机选择的约 7%的 Android UI 数据集(10804 对 UI 图像和 GUI 框架)作为精度评估的测试数据 。 测试数据均未出现在模型训练数据中 。
如图 5 所示 , 在所有 10804 个测试 UI 图像中 , 为 6513(60.28%)UI 图像生成的 GUI 框架与真实 GUI 框架完全匹配 , 并且在所有测试 UI 图像上的平均 BLEU 得分为 79.09 。 Beam 宽度为 1(即贪婪搜索) 。 此外 , 对于所有测试 UI 图像中只有 9 个 , 我们的模型无法生成封闭的方括号 。 该结果表明 , 我们的模型成功捕获了容器组件的成分信息 。 当 Beam 宽度增加到 5 时 , 精确匹配率和平均 BLEU 得分分别增加到 63.5%和 86.94% 。 但是 , 在 Beam 宽度= 2 之后的增加很小 。 因此 , 在下面的实验中 , 考虑到计算成本和准确性之间的平衡 , 我们使用 beam-width = 2 。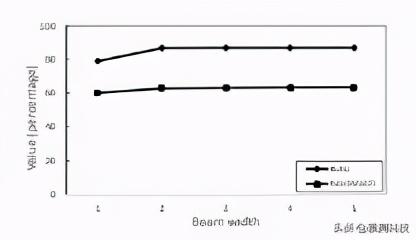 文章插图
文章插图
图 5:Beam 宽度的影响
5.2 通用性评估为了进一步确认翻译器的通用性 , 我们随机选择了 UI 数据集中未包含的另外 20 个应用 。 为了确保测试数据的数量 , 我们选择的应用程序至少安装了 1 毫米的安装程序(流行的应用程序通常具有内容丰富的 GUI) 。 在这些应用程序中 , 我们随机选择了 20 个应用程序 , 我们的数据收集器为其收集了 20 多个 UI 图像 。 这 20 个应用程序属于 10 个类别 。 我们总共收集了 1208 个 UI 图像(每个应用平均 60.4 个) 。 我们将 Beam 宽度设置为 2 以生成 GUI 框架 。
表 1:20 个完全看不见的应用程序的准确性结果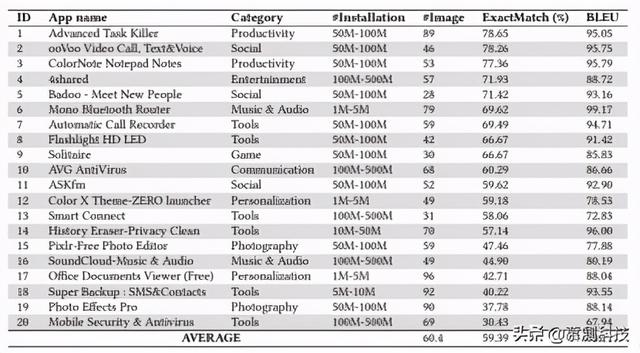 文章插图
文章插图
表 1 总结了所选 20 个应用程序的信息以及这些应用程序的 UI 图像上生成的 GUI 框架的准确性结果(按精确匹配率降序排列) 。 平均完全匹配率为 59.47%(略低于 Android UI 测试数据的平均完全匹配率(63.5%)) , 平均 BLEU 得分为 88.11(略高于 Android UI 测试的平均 BLEU 得分(86.94)数据) 。 这些结果证明了我们翻译的一般性 。
我们手动检查准确匹配率(<50%)或 BLEU 分数(<80)低的应用程序 。 我们观察到产生错误的原因与 6.3.4 节中讨论的原因相似 。 例如 , 个性化和摄影应用程序具有用户界面 , 供用户上载和操作文档或图像 。 类似于图 12(c)和图 12(d)中的地图和网页示例 , 我们的翻译人员可能会将 UI 中显示的某些内容误认为是要生成的 UI 的一部分 , 从而导致较低的精确匹配率或 BLEU 得分这些应用 。 但是 , 尽管对于某些此类应用程序(例如 17-Office Document Viewer , 19-Photo Effects Pro) , 精确匹配率较低 , 但 BLEU 得分较高 , 这表明生成的 GUI 框架仍在很大程度上与实际情况相匹配 。
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 走向|电商,从货架陈列走向内容驱动
- 权属|从数据悖论到权属确认,数据共享进路所在
- 高配版|从4599元跌至3699元,256GB+65W,12GB旗舰加速退场
- 科技|联咏科技将从明年下半年开始为iPad提供LCD驱动芯片
- 不确定性|从虾米看文娱,如何从内容不确定性寻找确定性?
- 换头像|从不换“头像”的人,多半都是这几张原因,你是哪一种?
- 添加|手机:小米手机如何添加门禁卡?
- 这场|这场顶级盛会,15位全球设计行业组织主席@烟台:中国创新经验从这里影响世界