从神经机器翻译器到引导移动GUI的实现( 三 )
图 3:用于 UI 图像到 GUI 框架生成的神经机器翻译器的架构
3.1 视觉 CNN 提取特征CNN 是一系列序列 , 可将原始图像在空间上转换为紧凑的特征表示形式(称为特征图) 。 在我们的 CNN 架构中 , 我们使用两种主要类型的层:卷积层(Conv)和池化层(Pool) , 遵循模式 Conv→Pool 。 我们堆叠几个 Conv→Pool 层以创建一个深层的 CNN , 因为深层的 CNN 可以提取输入图像的更强大功能 。 我们不使用完全连接的图层 , 因为我们要保留 CNN 要素的局部性以便以后对其空间布局信息进行编码 。
3.2 通过 RNN 编码器进行空间布局编码我们的神经机器翻译器仅将原始 UI 图像作为输入 , 不需要视觉元素的结构和位置的详细注释 。 因此 , 给定视觉 CNN 输出的特征图 , 对于有效生成适当的 GUI 组件及其组成 , 重要的是在输入图像中定位视觉特征的相对位置 。 为了对 CNN 特征的空间布局信息进行编码 , 我们在视觉 CNN 输出的特征图的每个特征向量上运行递归神经网络(RNN)编码器 。
RNN 递归地将输入向量 xt 和隐藏状态 h{t-1}映射到新的隐藏状态 ht:h_t = f(h{t-1} , x_t)其中 f 是非线性激活函数(例如 , 下面讨论的 LSTM 单位) 。 读取输入的结尾后 , RNN 编码器的隐藏状态是向量 C , 该向量总结了整个输入特征图的空间布局信息 。 对 CNN 功能之间的远程依赖关系进行建模对于我们的任务至关重要 。 例如 , 我们需要捕获基于图像的序列中视觉元素的右下角和左上角特征之间的依赖性 。 因此 , 我们采用长短期记忆(LSTM) 。LSTM 由一个存储单元和三个门组成 , 分别是输入 , 输出和忘记门 。 从概念上讲 , 存储单元存储了过去的上下文 , 而输入和输出门则允许该单元长时间存储上下文 。 同时 , 通过忘记门可以清除某些上下文 。 这种特殊的设计使 LSTM 可以捕获长期依赖关系 , 这种依赖关系通常发生在基于图像的序列中 。
3.3 通过 RNN 解码器生成 GUI 框架然后 , 根据 RNN 编码器的输出摘要矢量 C , 由解码器生成 GUI 框架语言的目标标记(即 GUI 组件的名称以及特殊标记{和}) 。如图 2 所示 , 可以通过深度优先遍历(DFT)将 GUI 框架的令牌序列表示形式转换为组件层次结构 。 由于生成的令牌序列的长度针对不同的 UI 图像而有所不同 , 因此我们采用了 RNN 解码器 , 即 能够产生可变长度的序列 。解码器在时间 t 的隐藏状态计算为 f(h{t-1} , y{t-1} , C)(f 也是 LSTM) 。下一个令牌 yt 的条件分布计算为 P(y_t |?y{t-1} , ... , y1? , C)= softmax(h_t , y{t-1} , C) , 其中 softmax 函数产生有效语言词汇的概率 。 注意 , 隐藏状态和下一个标记不仅取决于过去的上下文 , 而且还取决于输入图像的 CNN 特征的摘要矢量 C 。
3.4 训练模型尽管我们的神经机器翻译器由三个神经网络(视觉 CNN , 空间布局 RNN 编码器和 GUI 框架生成 RNN 解码器)组成 , 但是可以使用一个损失函数对这些网络进行端到端联合训练 。 训练数据由成对的 UI 图像 i 和相应的 GUI 框架 s 组成(有关如何构建大规模训练数据集 , 请参见第 4 节) 。GUI 框架表示为令牌序列 s = {s0 , s1 , ...} , 其中每个令牌都来自 GUI 框架语言(即 GUI 组件的名称以及两个特殊令牌{和}) 。每个令牌表示为一个热点向量 。
给定一个 UI 图像 i 作为输入 , 模型试图使产生 GUI 框架 s = {s0 , s1 , ...}的目标序列的条件概率 p(s | i)最大化 。由于 s 的长度是无界的 , 因此通常应用链式规则对 s0 , ... , sN 上的联合对数概率建模 , 其中 N 是特定序列的长度 , 如下所示: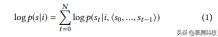 文章插图
文章插图
在训练时 , 我们使用随机梯度下降法优化了整个训练集的对数概率之和 。RNN 编码器和解码器将误差微分反向传播到其输入(即 CNN) , 从而使我们能够共同学习神经网络参数 , 以在统一框架中最小化误差率 。
3.5 GUI 框架推断在训练了神经机器翻译器之后 , 我们可以使用它来生成 UI 设计图像 i 的 GUI 框架 。 生成的 GUI 框架应具有最大对数概率 p(s | i) 。 生成全局最佳 GUI 框架具有沉浸式搜索空间 。 因此 , 我们采用 BeamSearch 来仅扩展搜索空间中有限的一组最有希望的节点 。 在每个步骤 t , BeamSearch 将 k 个(Beam 宽度)最佳序列的集合作为候选者 , 以生成大小为 t + 1 的序列 。 在步骤 t + 1 , 神经机器翻译器生成用于将每个当前候选序列扩展为大小为 t + 1 的新候选序列的语言词汇的概率分布 。 BeamSearch 仅保留大小为 t + 1 的所有新候选序列中的最佳 k 个序列 。 模型生成 k 个最佳序列的序列末尾符号 。 然后 , 将排名靠前 1 的序列作为输入 UI 图像的生成的 GUI 框架返回 。
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 走向|电商,从货架陈列走向内容驱动
- 权属|从数据悖论到权属确认,数据共享进路所在
- 高配版|从4599元跌至3699元,256GB+65W,12GB旗舰加速退场
- 科技|联咏科技将从明年下半年开始为iPad提供LCD驱动芯片
- 不确定性|从虾米看文娱,如何从内容不确定性寻找确定性?
- 换头像|从不换“头像”的人,多半都是这几张原因,你是哪一种?
- 添加|手机:小米手机如何添加门禁卡?
- 这场|这场顶级盛会,15位全球设计行业组织主席@烟台:中国创新经验从这里影响世界