为什么单线程的Redis能够达到百万级的QPS?
性能测试报告查看了下阿里云 Redis 的性能测试报告如下 , 能够达到数十万、百万级别的 QPS(暂时忽略阿里对 Redis 所做的优化) , 我们从 Redis 的设计和实现来分析一下 Redis 是怎么做的 。 文章插图
文章插图
Redis 的设计与实现其实 Redis 主要是通过三个方面来满足这样高效吞吐量的性能需求
- 高效的数据结构
- 多路复用 IO 模型
- 事件机制
以上几种对外暴露的数据结构它们的底层编码方式都是做了不同的优化的 , 不细说了 , 不是本文重点
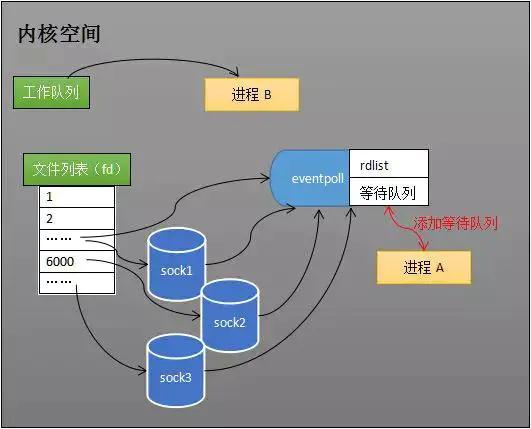
多路复用 IO 模型假设某一时刻与 Redis 服务器建立了 1 万个长连接 , 对于阻塞式 IO 的做法就是 , 对每一条连接都建立一个线程来处理 , 那么就需要 1万个线程 , 同时根据我们的经验对于 IO 密集型的操作我们一般设置 , 线程数 = 2 * CPU 数量 + 1 , 对于 CPU 密集型的操作一般设置线程 = CPU 数量 + 1 , 当然各种书籍或者网上也有一个详细的计算公式可以算出更加合适准确的线程数量 , 但是得到的结果往往是一个比较小的值 , 像阻塞式 IO 这也动则创建成千上万的线程 , 系统是无法承载这样的负荷的更加弹不上高效的吞吐量和服务了 。
而多路复用 IO 模型的做法是 , 用一个线程将这一万个建立成功的链接陆续的放入 event_poll , event_poll 会为这一万个长连接注册回调函数 , 当某一个长连接准备就绪后(建立建立成功、数据读取完成等) , 就会通过回调函数写入到 event_poll 的就绪队列 rdlist 中 , 这样这个单线程就可以通过读取 rdlist 获取到需要的数据
【为什么单线程的Redis能够达到百万级的QPS?】需要注意的是 , 除了异步 IO 外 , 其它的 I/O 模型其实都可以归类为阻塞式 I/O 模型 , 不同的是像阻塞式 I/O 模型在第一阶段读取数据的时候 , 如果此时数据未准备就绪需要阻塞 , 在第二阶段数据准备就绪后需要将数据从内核态复制到用户态这一步也是阻塞的 。 而多路复用 IO 模型在第一阶段是不阻塞的 , 只会在第二阶段阻塞
通过这种方式 , 就可以用 1 个或者几个线程来处理大量的连接了 , 极大的提升了吐吞量
 文章插图
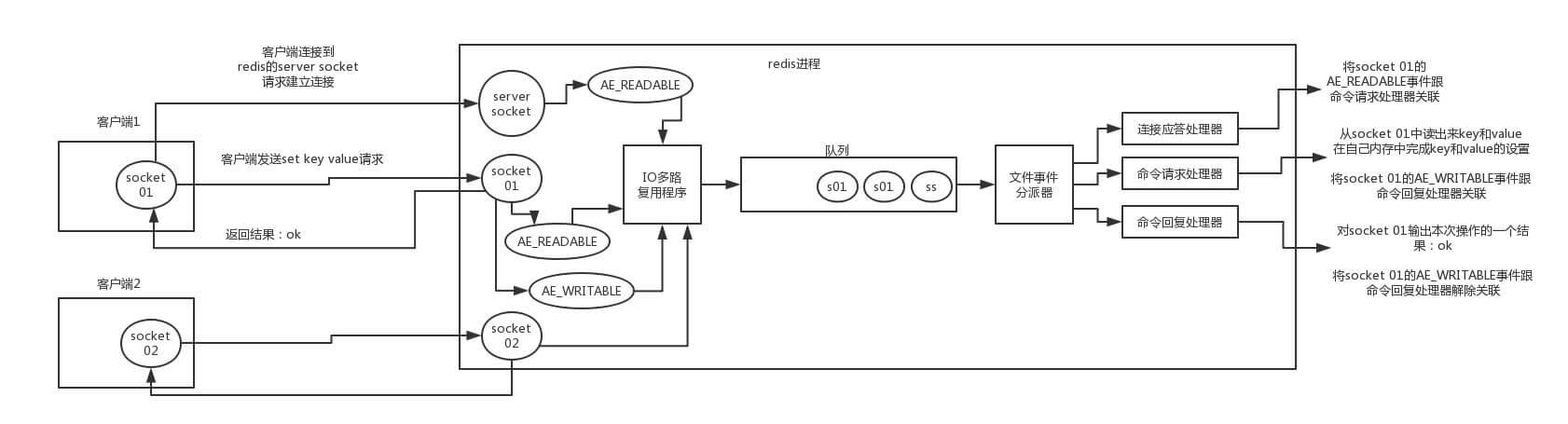
文章插图事件机制redis 客户端与 redis 服务端建立连接 , 发送命令 , redis 服务器响应命令都是需要通过事件机制来做的 , 如下图(来自互联网的某处...)
 文章插图
文章插图- 首先 redis 服务器运行 , 监听套接字的 AE_READABLE 事件处于监听的状态下 , 此时连接应答处理器工作 ,
- 客户端与 redis 服务器发起建立连接 , 监听套接字产生 AE_READABLE 事件 , 当 IO 多路复用程序监听到其准备就绪后 , 将该事件压入队列中 , 由文件事件分派器获取队列中的事件交于连接应答处理器工作处理 , 应答客户端建立连接成功 , 同时将客户端 socket 的 AE_READABLE 事件压入队列由文件事件分派器获取队列中的事件交命令请求处理器关联
- 客户端发送 set key value 请求 , 客户端 socket 的 AE_READABLE 事件 , 当 IO 多路复用程序监听到其准备就绪后 , 将该事件压入队列中 , 由文件事件分派器获取队列中的事件交于命令请求处理器关联处理
- 命令请求处理器关联处理完成后 , 需要响应客户端操作完成 , 此时将产生 socket 的 AE_WRITEABLE 事件压入队列 , 由文件事件分派器获取队列中的事件交于命令恢复处理器处理 , 返回操作结果 , 完成后将解除 AE_WRITEABLE 事件与命令恢复处理器的关联
可以类比在 netty 中 , 我们一般会设置 bossGroup 和 workerGroup 默认情况下 bossGroup 为 1 , workerGroup = 2 * cpu 数量 , 这样可以由多个线程来处理读写就绪的事件 , 但是其中不能有比较耗时的操作如果有的话需要将其放入线程池中 , 不然会降低其吐吞量 。 在 redis 中我们可以看做这二者的值都是 1
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 培训班|单县残联举办残疾人电子商务培训班
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 公式|?有人把 5G 讲得这么简单明了
- 砍单|iPhone12之后,拼多多又将iPhone12Pro拉下水
- 误导|苹果又吃巨额罚单,因iPhone防水宣传有误导被重罚9400万
- 简单|互联网巨头夺走菜贩生计?未必那么简单