Python|用Python语言模型和LSTM做一个Drake饶舌歌词生成器
 文章插图
文章插图
大数据文摘出品
编译:Fei、倪倪、什锦甜、钱天培
未来AI的主要应用是在建立能够学习数据然后生成原创内容的网络 。 这个想法已经充分应用于在自然语言处理(NLP)领域 , 这也是AI社区能够搭建出所谓语言模型的原因:语言模型的前提是学习句子在文章段落中的组成结构 , 从而生成新的内容 。
在这篇文章中 , 我想尝试生成与很受欢迎的加拿大说唱歌手Drake(a.k.a. #6god)风格类似的说唱歌词 , 这肯定是件很有趣的事儿 。
另外 , 我还想分享一下常规的机器学习项目渠道 , 因为我发现很多同学想做一些小项目 , 但不知道该从何处入手 。
获取数据
首先 , 我们开始搜集Drake的曲库 , 为了节省时间我直接写了个爬虫 , 从网页metrolyrics.com抓取歌词 。
import urllib.request as urllib2from bs4 import BeautifulSoupimport pandas as pdimport refrom unidecode import unidecodequote_page = '{}-lyrics-drake.html'filename = 'drake-songs.csv'songs = pd.read_csv(filename)for index, row in songs.iterrows(): page = urllib2.urlopen(quote_page.format(row['song'])) soup = BeautifulSoup(page, 'html.parser') verses = soup.find_all('p', attrs={'class': 'verse'}) lyrics = '' for verse in verses: text = verse.text.strip() text = re.sub(r"\[.*\]\n", "", unidecode(text)) if lyrics == '': lyrics = lyrics + text.replace('\n', '|-|') else: lyrics = lyrics + '|-|' + text.replace('\n', '|-|') songs.at[index, 'lyrics'] = lyrics print('saving {}'.format(row['song'])) songs.head()print('writing to .csv')songs.to_csv(filename, sep=',', encoding='utf-8')我用了一个大家都很熟悉的Python包BeautifulSoup来抓取网页 , 这里参考了一位大牛Justin Yek的教程 , 我只花了五分钟就学会了使用 。 说明一下 , 上面的代码中我在循环里使用了songs这一数据格式 , 是因为我事先定义了想获得的歌曲 。
教程:
 文章插图
文章插图
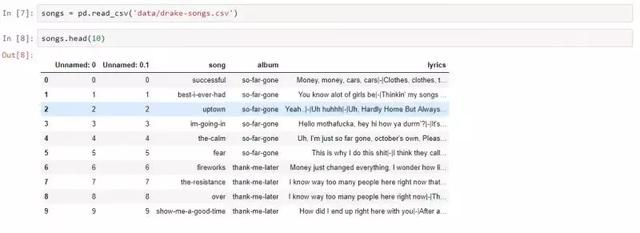
用DataFrame存储了所有的歌曲歌词
运行爬虫之后 , 我就得到了以合适的结构存储歌词的csv文件 , 下一步开始对数据进行预处理并且搭建模型 。
模型介绍
现在我们来看看模型是如何生成文本的 , 这部分你要着重理解 , 因为这是真正的干货 。 我将先从模型设计和生成歌词模型中的关键组成部分讲起 , 然后 , 我们就可以直接进入实施阶段 。
搭建语言模型主要有两种方法:
1.字符级(Character-leve)模型 ,
2.词汇级(Word-level)模型 。
这两者的主要区别在于模型的输入和输出 , 接下来就具体讲解一下两个模型的工作原理 。
字符级模型
在字符级模型中 , 输入是一连串的字符seed(种子) , 模型负责预测下一个字符 , 然后用seed + new_char组合来生成再下一个字符 , 以此类推 。 注意 , 因为我们每次输入的长度应保持一致 , 所以实际上在每次迭代输入时都要丢掉一个字符 。 我们可以看一个简单的直观的例子: 文章插图
文章插图
字符级模型生成词的迭代过程
每次迭代时 , 模型都是在给定种子字符的基础上预测下一个最可能生成的字符 , 或者利用条件概率 , 即找到概率P(new_char|seed)的最大值 , 其中new_char是字母表中的任一字母 。
在此例中 , 字符表指所有英文字母和间隔符号的集合 。 (说明 , 字母表可以根据你的需要包含不同的字母 , 主要取决于你生成的语言种类) 。
词汇级模型
词汇级模型和字符级模型非常相似 , 但是它用来生成下一个单词而非字符 。 这里举一个简单的例子来说明这一点: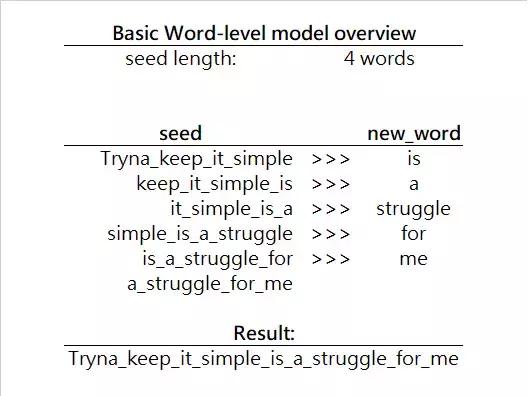 文章插图
文章插图
图3. 词汇级模型生成词汇的迭代过程
现在在这个模型中 , 我们以一个词汇为单位向前寻找下一个词汇 , 而非字符 。 因此 , 我们想找到概率P(new_word|seed)的最大值 , 其中new_word是任一词汇 。
这里要注意的是 , 这里我们搜索的范围比字符级要大得多 。 字符集模型中 , 我们只需从字符表中查找大概30个字符 , 但词汇级中每次迭代搜索的范围远远大于这个数量 , 因此每次迭代的运行速度更慢 , 但既然我们生成的是一整个词而不只是一个字符 , 所以也不算太糟糕 。
关于词汇级模型 , 我最后想说明一点 , 我们可以通过在数据集中搜索独特的词汇来生成更加多样的词汇(这一步通常在数据预处理阶段进行) 。 由于词汇量可以无限大 , 我们其实有很多提高生成词汇性能的算法 , 比如词嵌入 , 不过关于这个问题可以再写一篇文章了 。
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 美国|英国媒体惊叹:165个国家采用北斗将GPS替代,连美国也不例外?
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快