循环神经网络(RNN)简易教程
 文章插图
文章插图
我们从以下问题开始
- 循环神经网络能解决人工神经网络和卷积神经网络存在的问题 。
- 在哪里可以使用RNN?
- RNN是什么以及它是如何工作的?
- 挑战RNN的消梯度失和梯度爆炸
- LSTM和GRU如何解决这些挑战
当我们需要处理需要在多个时间步上的序列数据时 , 我们使用循环神经网络(RNN)
传统的神经网络和CNN需要一个固定的输入向量 , 在固定的层集上应用激活函数产生固定大小的输出 。
例如 , 我们使用128×128大小的向量的输入图像来预测狗、猫或汽车的图像 。 我们不能用可变大小的图像来做预测
现在 , 如果我们需要对依赖于先前输入状态(如消息)的序列数据进行操作 , 或者序列数据可以在输入或输出中 , 或者同时在输入和输出中 , 而这正是我们使用RNNs的地方 , 该怎么办 。
在RNN中 , 我们共享权重并将输出反馈给循环输入 , 这种循环公式有助于处理序列数据 。
RNN利用连续的数据来推断谁在说话 , 说什么 , 下一个单词可能是什么等等 。
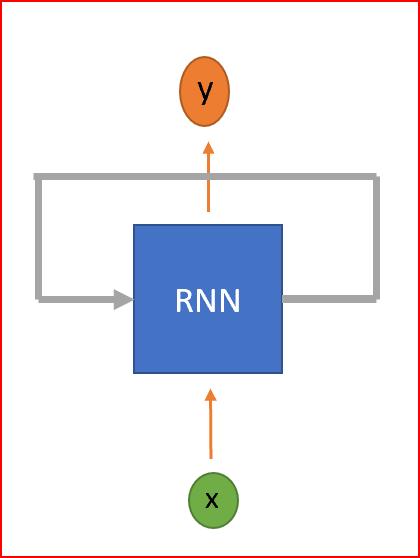
RNN是一种神经网络 , 具有循环来保存信息 。 RNN被称为循环 , 因为它们对序列中的每个元素执行相同的任务 , 并且输出元素依赖于以前的元素或状态 。 这就是RNN如何持久化信息以使用上下文来推断 。
 文章插图
文章插图RNN是一种具有循环的神经网络
RNN在哪里使用?
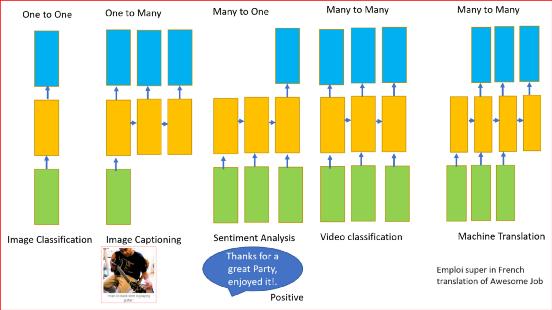
前面所述的RNN可以有一个或多个输入和一个或多个输出 , 即可变输入和可变输出 。
RNN可用于
- 分类图像
- 图像采集
- 机器翻译
- 视频分类
- 情绪分析
 文章插图
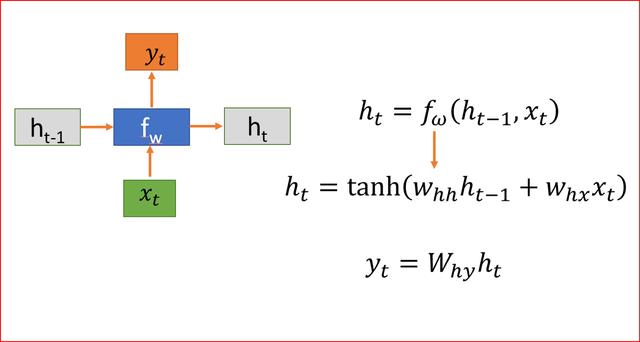
文章插图RNN是如何工作的?先解释符号 。
- h是隐藏状态
- x为输入
- y为输出
- W是权重
- t是时间步长
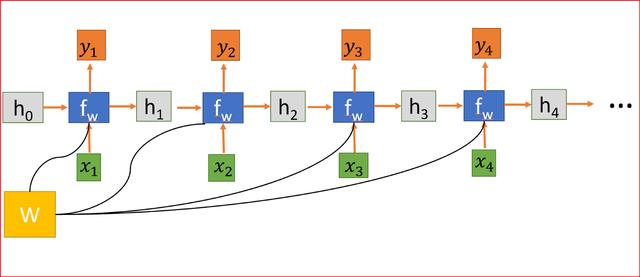
 文章插图
文章插图将RNN展开为四层神经网络 , 每一步共享权值矩阵W 。
隐藏状态连接来自前一个状态的信息 , 因此充当RNN的记忆 。 任何时间步的输出都取决于当前输入以及以前的状态 。
与其他对每个隐藏层使用不同参数的深层神经网络不同 , RNN在每个步骤共享相同的权重参数 。
我们随机初始化权重矩阵 , 在训练过程中 , 我们需要找到矩阵的值 , 使我们有理想的行为 , 所以我们计算损失函数L 。 损失函数L是通过测量实际输出和预测输出之间的差异来计算的 。 用交叉熵函数计算L 。
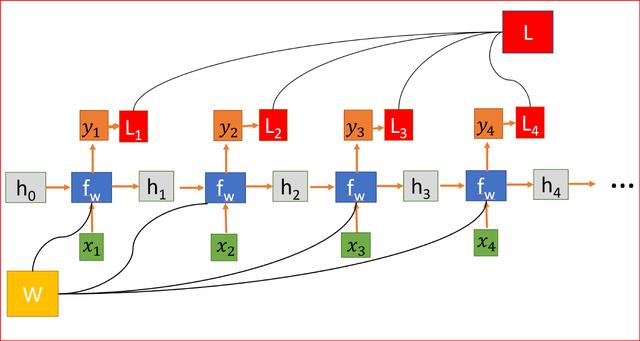 文章插图
文章插图RNN , 其中损失函数L是各层所有损失的总和
为了减少损失 , 我们使用反向传播 , 但与传统的神经网络不同 , RNN在多个层次上共享权重 , 换句话说 , 它在所有时间步骤上共享权重 。 这样 , 每一步的误差梯度也取决于前一步的损失 。
在上面的例子中 , 为了计算第4步的梯度 , 我们需要将前3步的损失和第4步的损失相加 。 这称为通过Time-BPPT的反向传播 。
我们计算误差相对于权重的梯度 , 来为我们学习正确的权重 , 为我们获得理想的输出 。
因为W在每一步中都被用到 , 直到最后的输出 , 我们从t=4反向传播到t=0 。 在传统的神经网络中 , 我们不共享权重 , 因此不需要对梯度进行求和 , 而在RNN中 , 我们共享权重 , 并且我们需要在每个时间步上对W的梯度进行求和 。
在时间步t=0计算h的梯度涉及W的许多因素 , 因为我们需要通过每个RNN单元反向传播 。 即使我们不要权重矩阵 , 并且一次又一次地乘以相同的标量值 , 但是时间步如果特别大 , 比如说100个时间步 , 这将是一个挑战 。
如果最大奇异值大于1 , 则梯度将爆炸 , 称为爆炸梯度 。
- 用于|用于半监督学习的图随机神经网络
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 湖南“速生人工林”成功验收 打造绿色高效循环产业技术创新链
- 如何系统地欺骗图像识别神经网络
- 图解3种常见的深度学习网络结构:FC、CNN、RNN
- JavaScript不使用for循环,生成1~100数列
- 出口|浙江湖州:出口内销并举 发力“双循环”
- 当务之急|超2019全年!全国快递业务量逾700亿件,包装循环利用成当务之急
- 输出层|PyTorch可视化理解卷积神经网络
- 电商|聚焦“双循环” 共赴电商盛会