检测|华人研究团队推出AI“讽刺”检测模型,准确率达86%( 二 )
受此启发,他们提出了一种基于BERT架构的模型,该模型可有效解决这一问题。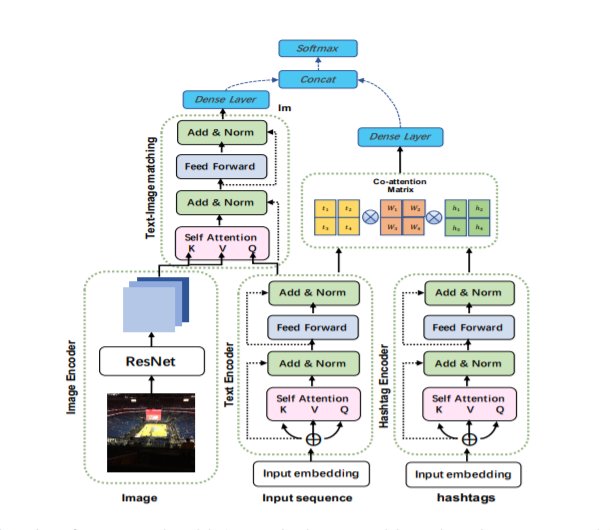
文章插图
模型框架
具体来说,研究人员利用自注意机制(Self-Attention Mechanism)的思想,设计了一种模态间注意力机制以捕获其间的不一致性。图中,预先训练的BERT模型对给定的序列和其中的Hashtags进行编码。ResNet用于获取图像形式。我们运用Intra-modality注意来模拟文本内部的不协调,而Inner-modality来模拟文本和图像之间的不协调。然后将不协调信息进行组合并用于预测。
实验结果表明,该模型在公共多模式讽刺检测数据集上达到了最新的性能—86%。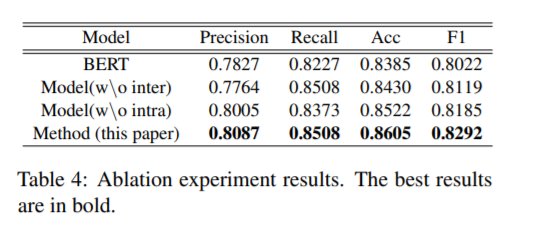
文章插图
与此同时,研究人员还将该模型与现有模型基准,从预测率(Precision)、召回率(Recall)、精准度(Accuracy)和F1分数等指标进行了比较。
结果显示,与当前最先进的层次融合模型HFM相比,提高了2.74%。与微调的BERT模型相比,提高了2.7%。如图: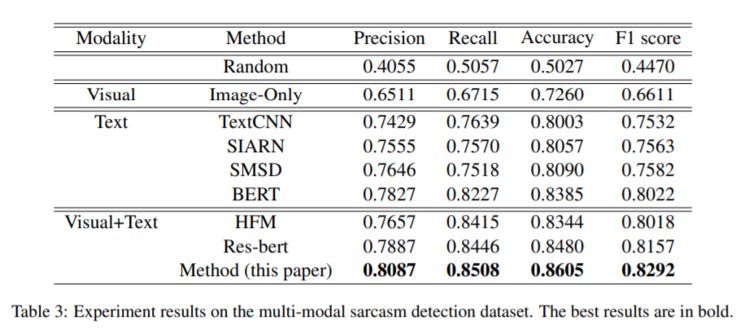
文章插图
从该表中可以看出,仅使用图像特征的模型并没有很好的表现(72.6%),这说明对于多模态检测任务来说,图像是不能单独处理的。而且基于文本模态的方法(均在80%以上)比基于图像模态的方法具有更好的性能。因此,文本信息比图像信息更能用于讽刺信息的检测。
此外,经过微调的BERT模型比其他基于文本的非预训练模型表现得更好,这也再次验证了研究人员的设想,即像BERT这样的预训练模型可以改进检测任务,它表明视觉+文本模式的模型通常比其他模式能够获得更好的结果,同时,它也说明图像有助于提高检测性能。
值得注意的是,从文本模态内部的模型来看,SIARN(80.5%)和SMSD(80.9%)都考虑了不一致信息,且性能表现优于TextCNN(80%),因此,不一致信息有助于识别讽刺,再次验证研究人员提出的模态间的非一致性检测方法比简单的模态间连接方法更有效。
更多论文详情,可参见:https://www.aclweb.org/anthology/2020.findings-emnlp.124.pdf
引用链接:
https://interestingengineering.com/new-ai-model-detects-sarcasm-with-86-percent-accuracy-which-is-totally-fine
https://venturebeat.com/2020/11/18/ai-researchers-made-a-sarcasm-detection-model-and-its-soo-impressive/
https://www.engadget.com/facebook-develops-ai-moderation-tools-that-actually-work-at-facebookscale-180058754.html
【 检测|华人研究团队推出AI“讽刺”检测模型,准确率达86%】雷锋网雷锋网雷锋网
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 器件|苏州纳米所等在高性能柔性储能器件研究中取得进展
- 大神|研究完各路大神,终于知道互联网创业的你为何不赚钱
- 潜力|【国金研究】新星初现,商业化落地正当时 ——自动驾驶先行者Waymo潜力几何
- 人民医院|加强冷链食品核酸检测 确保“舌尖上”的安全
- 商标|你知道为什么一定要检测商标吗?
- 检测|机器视觉检测解决方案商“鼎纳自动化”完成B轮亿元融资
- 阴性|襄阳开展进口冷链食品新冠病毒防控检查 核酸检测均为阴性!
- 荷兰:中国为研究光刻机技术,专门创办芯片大学,“反人类”操作
- 检测DTU信号是否稳定的4个方法