FastFormers论文解读:CPU上推理速度提高233倍( 二 )
· 根据目标模型的大小 , 作者从网络中选择给定数量的顶部磁头和顶部隐藏状态 。 完成排序和选择步骤后 , 作者将重新分组并重新连接其余的头部和隐藏状态 , 从而使模型更小 。 修剪头部和隐藏状态时 , 作者在不同图层上使用相同的修剪率 。 这使得进一步的优化可以与修剪的模型无缝地协同工作 。
· 在实验中 , 作者发现 , 经过修剪的模型经过另一轮知识蒸馏后 , 可以获得更高的准确性 。 因此 , 知识蒸馏再次应用于该模型 。
模型量化:量化是指用于执行计算并以小于浮点精度的位宽存储张量的技术 。量化模型对张量使用整数而不是浮点值执行部分或全部运算 。这允许更紧凑的模型表示 , 并在许多硬件平台上使用高性能矢量化操作 。
CPU上的8位量化矩阵乘法:与32位浮点算术相比 , 8位量化矩阵乘法带来了显着的加速 , 这归功于CPU指令数量的减少 。
GPU的16位模型转换:V100 GPU支持Transformer架构的完整16位操作 。同样 , 除了具有较小的值范围外 , 16位浮点运算不需要对输入和输出进行特殊处理 。由于Transformer模型受内存带宽限制 , 因此这种16位模型转换带来了相当可观的速度提升 。观察到大约3.53倍的加速 , 具体取决于模型设置 。
除了应用的结构和数值优化外 , 作者还利用各种方式进一步优化计算 , 尤其是多处理优化和计算图优化 。
综合结果下表说明了以下结果的有效性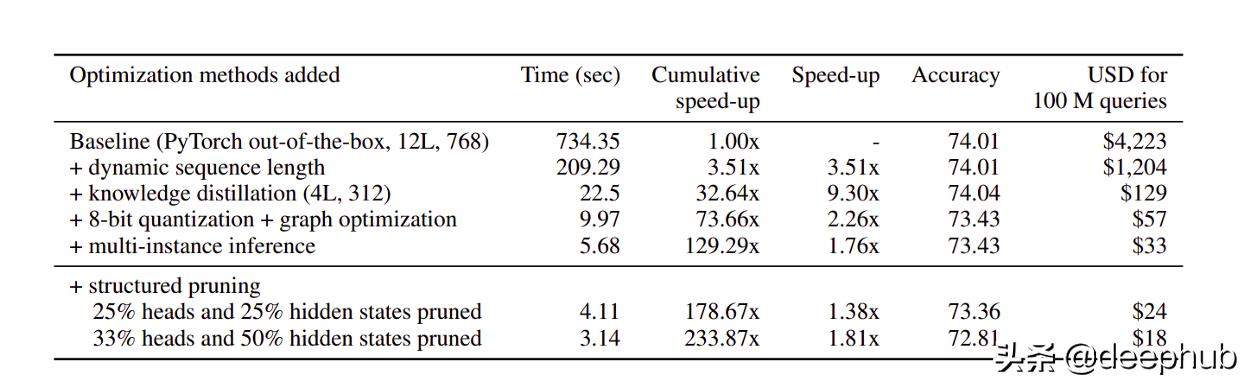 文章插图
文章插图
在本文中 , 作者介绍了FastFormers , 它可以在各种NLU任务上为基于Transformer的模型提供有效的推理时间性能 。FastFormers论文的作者表明 , 利用知识提炼 , 结构化修剪和数值优化可以大大提高推理效率 。我们证明 , 这些改进最多可以提高200倍 , 并以节省22倍的计算量实现200倍以上的推理成本节省 。
最后FastFormers源代码:
作者:Parth Chokhra
【FastFormers论文解读:CPU上推理速度提高233倍】deephub翻译组
- 一图看懂!数字日照、新型智慧城市这样建(上篇)|政策解读 | 新型
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 设计|未来创意拒绝被垄断:欧拉共创成果深度解读!
- 顶级|内地高校凭磁性球体机器人首获机器人顶级会议最佳论文奖
- NeurIPS 2020论文分享第一期|深度图高斯过程 | 深度图
- 主题|GNN、RL崛起,CNN初现疲态?ICLR 2021最全论文主题分析
- 爱可可AI论文推介(10月17日)
- 超好用的UnixLinux 命令技巧 大神为你详细解读
- Redmi|Redmi Note 9全系解读,999到1599元,三款手机各有哪些区别?
- 论文|中国人民大学赵鑫:AI 科研入坑指南