爱可可AI论文推介(10月17日)
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言
1、[CV]*NeRF++: Analyzing and Improving Neural Radiance Fields
K Zhang, G Riegler, N Snavely, V Koltun
[Cornell Tech & Intel Labs]
神经辐射场分析与改进(NeRF++) , 讨论了辐射场的潜在歧义 , 即形状-亮度歧义 , 分析了NeRF在避免这种歧义方面取得的成功;解决了将NeRF用于大规模、无边界3D场景360度捕获对象时涉及的参数化问题 , 在这个具有挑战性的场景中提高了视图合成的保真度 。
Neural Radiance Fields (NeRF) achieve impressive view synthesis results for a variety of capture settings, including 360 capture of bounded scenes and forward-facing capture of bounded and unbounded scenes. NeRF fits multi-layer perceptrons (MLPs) representing view-invariant opacity and view-dependent color volumes to a set of training images, and samples novel views based on volume rendering techniques. In this technical report, we first remark on radiance fields and their potential ambiguities, namely the shape-radiance ambiguity, and analyze NeRF's success in avoiding such ambiguities. Second, we address a parametrization issue involved in applying NeRF to 360 captures of objects within large-scale, unbounded 3D scenes. Our method improves view synthesis fidelity in this challenging scenario. Code is available at this https URL.
 文章插图
文章插图 文章插图
文章插图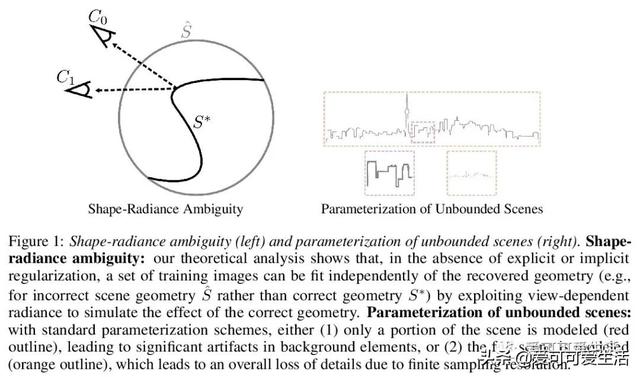 文章插图
文章插图 文章插图
文章插图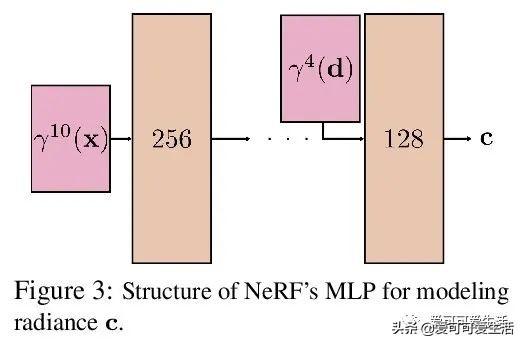 文章插图
文章插图
2、[CL]*Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
H Tan, M Bansal
[UNC Chapel Hill]
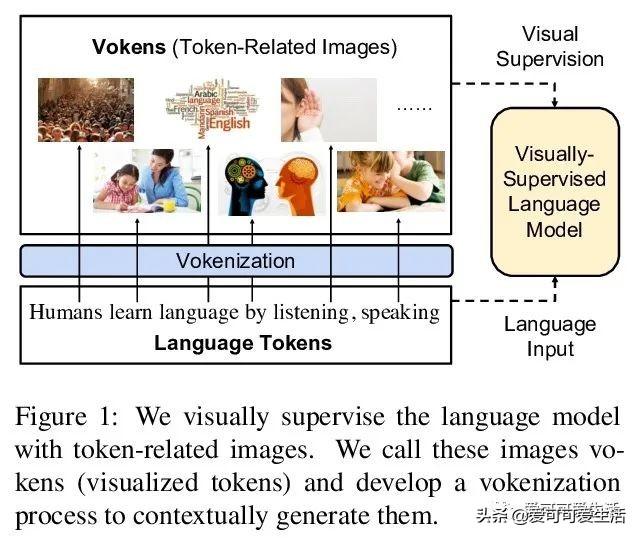
视觉监督语言模型vokenization , 通过上下文化映射语言词条到相关图像(称为“vokens”) , 将多模态对齐外推到仅包含语言的数据 。 在相对较小的图像描述数据集上训练“vokenizer” , 再用它生成大语言语料库的vokens 。 在这些生成的vokens的监督下 , 在多语言任务上比单纯自监督语言模型有显著改进 。
Humans learn language by listening, speaking, writing, reading, and also, via interaction with the multimodal real world. Existing language pre-training frameworks show the effectiveness of text-only self-supervision while we explore the idea of a visually-supervised language model in this paper. We find that the main reason hindering this exploration is the large divergence in magnitude and distributions between the visually-grounded language datasets and pure-language corpora. Therefore, we develop a technique named "vokenization" that extrapolates multimodal alignments to language-only data by contextually mapping language tokens to their related images (which we call "vokens"). The "vokenizer" is trained on relatively small image captioning datasets and we then apply it to generate vokens for large language corpora. Trained with these contextually generated vokens, our visually-supervised language models show consistent improvements over self-supervised alternatives on multiple pure-language tasks such as GLUE, SQuAD, and SWAG. Code and pre-trained models publicly available at this https URL
 文章插图
文章插图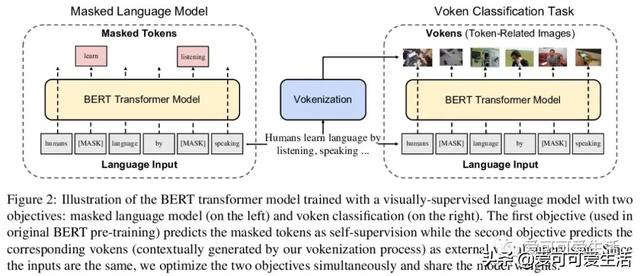 文章插图
文章插图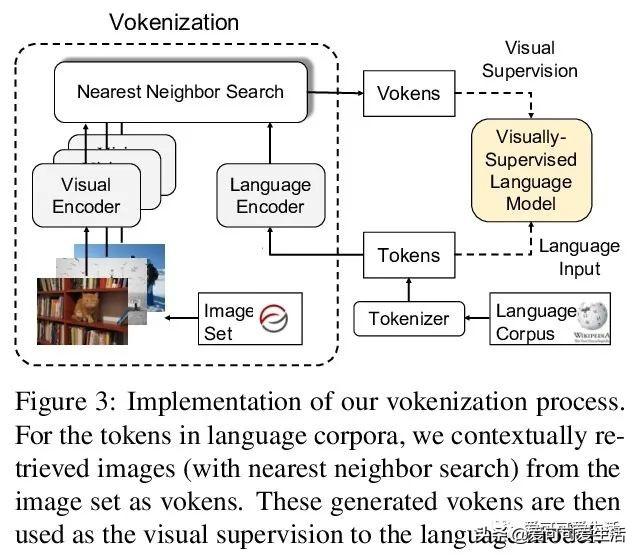 文章插图
文章插图 文章插图
文章插图
3、[CL]*Learning Adaptive Language Interfaces through Decomposition
S Karamcheti, D Sadigh, P Liang
[Stanford University]
基于抽象和分解的交互式自然语言界面 , 其目标是有效且可靠地从真实的人类用户交互中学习 , 以完成模拟机器人设置中的任务 。 引入神经语义解析系统 , 可通过分解来学习新的高级抽象:用户通过交互将描述新行为的高级指令分解成系统可以理解的低级步骤来教授系统 。
Our goal is to create an interactive natural language interface that efficiently and reliably learns from users to complete tasks in simulated robotics settings. We introduce a neural semantic parsing system that learns new high-level abstractions through decomposition: users interactively teach the system by breaking down high-level utterances describing novel behavior into low-level steps that it can understand. Unfortunately, existing methods either rely on grammars which parse sentences with limited flexibility, or neural sequence-to-sequence models that do not learn efficiently or reliably from individual examples. Our approach bridges this gap, demonstrating the flexibility of modern neural systems, as well as the one-shot reliable generalization of grammar-based methods. Our crowdsourced interactive experiments suggest that over time, users complete complex tasks more efficiently while using our system by leveraging what they just taught. At the same time, getting users to trust the system enough to be incentivized to teach high-level utterances is still an ongoing challenge. We end with a discussion of some of the obstacles we need to overcome to fully realize the potential of the interactive paradigm.
- 网络覆盖|爱立信:2020年底,将有超过10亿人口获得5G网络覆盖
- 苹果|iPhone13迎来变化!或回归指纹解锁,这几点备受用户喜爱
- 账号|“共享会员”公司侵权被告!爱奇艺公司起诉获赔300万
- 工程师|AWS偏爱Rust,已将Rust编译器团队负责人收入囊中
- 车一族|直播|@爱车一族:60分钟穿越汽车的前世今生
- 刷机|前几年满大街的“刷机”服务去哪里了,为什么大家都不爱刷机了?
- 暂停|桐生可可暂停活动后,holo开启招募,准备培养新一批的虚拟主播
- 爱奇艺|连续亏损十年,爱奇艺收入不及快手,视频网站的出口在哪里?
- 苹果的好处|一天一苹果,5个好处登门拜访,爱吃的朋友深有体会!
- VIP|马上玩App分时出租爱奇艺VIP帐号,爱奇艺起诉获赔300万