分布式|优秀!一鼓作气学会“一致性哈希”,就靠这 18 张图了

文章插图
出品 | 四猿外
责编 | 晋兆雨
头图 | 付费下载于视觉中国
大家好,好久不见啦。最近快年底了,公司、部门事情太多:冲刺 KPI、做部门预算……所以忙东忙西的,写文章就被耽搁了。再加上这篇文章比较硬,我想给大家讲得通俗易懂,着实花了很多时间琢磨怎么写。
话不多说,小故事开始。
前言
当架构师大刘看到实习生小李提交的记账流水乱序的问题的时候,他知道没错了:这一次,大刘又要用一致性哈希这个老伙计来解决这个问题了。
嗯,一致性哈希,分布式架构师必备良药,让我们一起来尝尝它。
满眼都是自己二十年前的样子,让我们从哈希开始
在 N 年前,互联网的分布式架构方兴未艾。大刘所在的公司由于业务需要,引入了一套由 IBM 团队设计的业务架构。
这套架构采用了分布式的思想,通过RabbitMQ 的消息中间件来通信。这套架构,在当时的年代里,算是思想超前,技术少见的黑科技架构了。
但是,由于当年分布式技术落地并不广泛,有很多尚不成熟的地方。所以,这套架构在经年日久的使用中,一些问题逐渐突出。其中,最典型的问题有两个:
RabbitMQ 是个单点,它一坏掉,整个系统就会全部瘫痪。
收、发消息的业务系统也是单点。任何一点出现问题,对应队列的消息要么无从消费,要么海量消息堆积。
无论哪种问题,最终是整套分布式系统都无法使用,后续处理非常麻烦。
对于 RabbitMQ 的单点问题,由于当时 RabbitMQ 的集群功能非常弱,普通模式有 queue 本身的单点问题,所以,最终使用了 Keepalived 配合了两台无关系的 RabbitMQ 搞出了高可用。
而对于业务系统单点问题,从一开始着手解决的时候就出现了波折。一般来说,我们要解决单点问题,方法就是堆机器,堆应用。收发是单点,我们直接多部署几个应用就可以了。如果仅仅从技术上看,无非就是多个收发消息的应用大家一起竞争往 MQ 中放消息拿消息而已。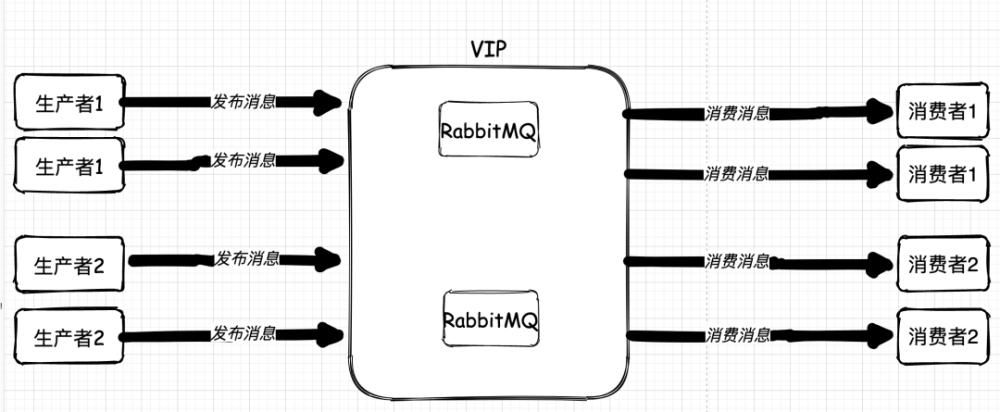
文章插图
但是,恰恰就是在把收发消息的应用集群化后,系统出现了问题。
本身这套系统架构会被应用到公司的多类业务上,有些业务对消息的顺序有着苛刻的要求。
比如,公司内部的 IM 应用,不管是点对点的聊天还是群聊消息,都需要对话消息严格有序。而当我们把生产消息和消费消息的应用集群化后,问题出现了:
聊天记录出现了乱序
A 和 B 对话,会出现某些消息没有严格按照 A 发出的先后顺序被 B 接收,于是整个聊天顺序乱成了一锅粥。
经过排查,发现问题的根源就在于应用集群上。由于没有对应用集群收发消息做特殊的处理,当 A 发出一条聊天信息给B时,发送到 RabbitMQ 中的信息会被在 B 处的消费端所争抢。如果 A 在短时间内发出了几条信息,那么就可能会被集群中的不同应用抢走。
这时候,乱序的问题就出现了。虽然应用业务逻辑是相同的,但是这些集群中的应用依然可能在处理信息速度上出现差异,最终导致用户看到的聊天信息错乱。
问题找到了,解决办法是什么?
上面我们说过了,消息顺序错乱是因为集群中不同应用抢消息然后处理速度不一样导致的。如果我们能保证 A 和 B 会话,从开始之后到会话结束之前,永远只会被 B 所在的消费消息集群应用中的同一个应用消费,那么我们就能保证消息有序。这样一来,我们就可以在消费消息的那个应用中,对抢到的消息进行排队,然后依次处理。
那么,这种保证怎么实现呢?
首先,我们在 RabbitMQ 中会建立有相同前缀的队列,后面跟着队列编号。然后,集群中的不同应用会分别监听这两个有着不同编号的队列。当在 A 发送信息时,我们会对信息做一次简单的哈希:
m = hash(id) mod n
这里,id 是用户的标识。n 是集群中 B 所在业务系统部署的数量。最终的 m 是我们需要发送到的目的队列编号。
假设,hash(id) 的结果为 2000,n 为 2,经过计算 m = 0。此时,A 就会把他和 B 的对话信息都发送到 chat00 的队列里。B 收到消息后,就会依次显示给终端用户。这样,聊天乱序的问题就解决了。
那么,事情到此就结束了吗?这个解决方案是完美的吗?
看来,我们需要增加应用数量了
随着公司的发展,公司的人数也急剧上升,公司内部的 IM 使用人数也跟着多了起来,新问题又随之出现了。
最主要的问题是,人们收到聊天信息的速度变慢了。原因也很简单,收取聊天信息的集群机器不够用了。解决办法可以简单直接点,再加台机器就好了。
- 表现|表现优秀的骁龙865高端旗舰都有哪些?以下这三款机型入手不亏!
- 分布式锁的这三种实现90%的人都不知道
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 为什么分布式应用程序需要依赖管理?
- 大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率
- 分布式云对智能化战争有何影响
- vivo Y73s评测:轻巧无负担兼具优秀体验
- 四核强性能,华硕XD4灵耀AX魔方分布式路由评测
- 优秀软件设计的基本元素是什么?