AMD发布目前最快HPC GPU
 文章插图
文章插图
AMD发布最新的InstinctMI100加速器 , 该加速器是目前最快地HPC GPU , 其采用AMD CDNA架构 , 并使用AMD Matrix Cores技术 , 与第二代AMD EPYC处理器搭配使用 , 可提供超过10 TFLOPS的FP64性能 , 而在FP32矩阵巅峰性能则达46.1 TFLOPS , 可大幅加速人工智能与机器学习工作负载 , 而在FP16的理论巅峰性能 , 是前一代的7倍 。
【AMD发布目前最快HPC GPU】MI100加速器专为超级计算机设计 , 超级计算机可用来执行天气预测 , 或是物理模拟等运算密集的工作 , 过去这些工作主要由CPU负担运算 , 但随着科学运算应用越来越多机器学习技术 , GPU逐渐变得重要 , 超级计算机也开始大量采用GPU , 通过大规模平行化运算 , 来加速机器学习运算 。
7纳米的MI100 GPU采用最新的CDNA架构 , CDNA架构是专为HPC与人工智能工作负载设计 , 能够强化运算的需求 , CDNA架构与绘图用的AMD RDNA架构不同 , 因为HPC与人工智能运算不需要图形加速运算 , 因此CDNA架构移除了光栅化、图形缓存以及显示引擎等功能硬件 , 但保留了HEVC、H.264和VP9解码的专用逻辑 , 因此CDNA架构GPU仍可以用来处理多媒体运算 , 像是物体侦测等机器学习应用 , 而删除图形加速用硬件的CDNA架构 , 刚好也能释放更多的空间 , 以投资其他运算单元 , 增加性能与效率 。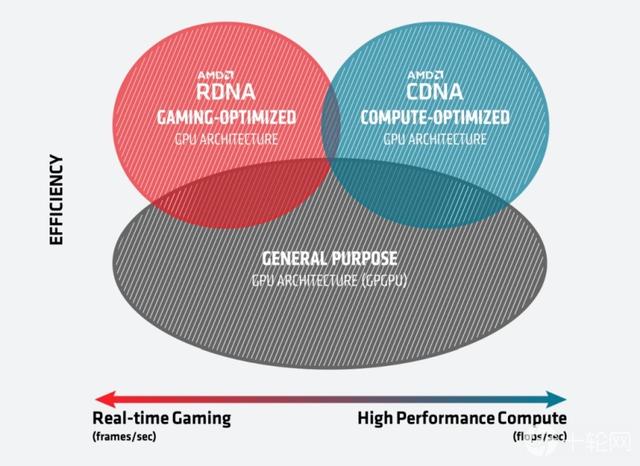 文章插图
文章插图
MI100 GPU应用了全新Matrix Cores技术 , 可以极大程度的增加人工智能的运算性能 , 该技术可以提高像是FP32、FP16或是INT8等 , 各种精度和混合精度矩阵的运算性能 , 甚至可以将FP32矩阵运算性能 , 提高到46.1 TFLOPS , 在人工智能训练工作负载 , FP16理论峰值浮点数性能 , 还可以提升到将近上一代的7倍 。
AMD提到 , MI100 GPU由几个主要模块构成 , 这些模块以芯片级的互联芯片数组(On-die Fabric)捆绑在一起 , 并使用PCIe 4.0接口将GPU连接到CPU , 可以支持GPU到CPU间连接带宽16 GT/s , 双向的速度皆可达32 GB/s 。 另外 , MI100加速器使用32 GB超快速第二代高带宽内存(HBM2) , 提供超高1.23 TB/s内存带宽 , 能满足超大型资料集流入流出的需求 , 而不会产生资料瓶颈 。
超级计算机会由数台服务器组合而成 , 每台服务器都可以搭载多颗GPU , 为了支持这种多颗GPU架构 , MI100集成了一项称为Infinity Fabric的技术 , 可在PCIe 4.0提供2倍点对点高峰I/O带宽 , 当存在3个Infinity Fabric连接 , 就可让每张加速卡带宽高达340 GB/s 。 文章插图
文章插图
MI100 GPU受到瞩目 , 是因为MI100是同类产品中最快的芯片 , 目前唯一在FP64 , 突破10 TFLOPS的x86服务器GPU , 可达11.5 TFLOPS高峰性能 , 而FP32工作负载 , 则提供23.1 TFLOPS的峰值性能 , 根据AMD的实验 , 无论是在FP64还是FP32 , 都比起竞争对手NVidia A100 GPU性能更好 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- Blade|售价2798元 中兴Blade 20 Pro 5G手机发布 骁龙765G配四摄
- 承受|折叠屏iPhone已开始测试?要求能承受10万次折叠,或在2年后发布
- 早报:高通骁龙888正式发布 嫦娥五号传回首张图片
- 建设|《青岛市城市云脑建设指引》发布
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 自动驾驶汽车|海外|自动驾驶无法可依?美国多个团体联合发布自动驾驶立法大纲
- 中国视频|人日评论点赞!OPPO成视频手机先行者,新技术或下月发布
- 将要发布|高通下一代处理器不叫骁龙875,而是叫骁龙888
- 确认|小米11Pro已确认,首发骁龙875,将于本月提前发布