引入|引入标准运算管芯,谷歌AI芯片更加多样化
【嘉德点评】谷歌发明的用于神经网络任务的AI芯片,通过引入标准人工智能运算管芯,使得AI芯片可以应对多种复杂的网络结构,从而降低了芯片设计时长以及减少了设计的工作量。
集微网消息,自从谷歌公司的AlphaGo机器人战胜人类围棋之后,人工智能便一直活跃在人们的视野之中,与各种人工智能方法对应的是AI芯片。而在18年的Next云计算大会上,谷歌披露了自家抢攻IoT终端运算的战略武器,其中最引人关注的就是Edge TPU芯片的发布。
据悉,谷歌不仅为在自己的数据中心开发人工智能芯片,还打算在将其设计的Edge TPU用在其他公司生产的产品中。这种人工智能芯片在物联网应用以及智能终端设备中具有巨大的使用空间。
在AI芯片设计方面,随着神经网络的使用在人工智能计算领域中迅速增长,专用集成电路(ASIC)的专用计算机的使用已经被用于处理神经网络,虽然这些方法可以用于设计AI芯片,但是随着神经网络的普及和针对其使用神经网络的任务范围的增长,较长的设计时间和不可忽略的非重复性工程成本将会加剧。
为此,谷歌在18年9月21日申请了一项名为“用于使用具有多个相同的管芯的单片封装处理神经网络任务的设备和机制”的发明专利(申请号:201880033593.8),申请人为谷歌有限责任公司。
根据该专利目前公开的资料,让我们一起来看看谷歌的这项专利技术吧。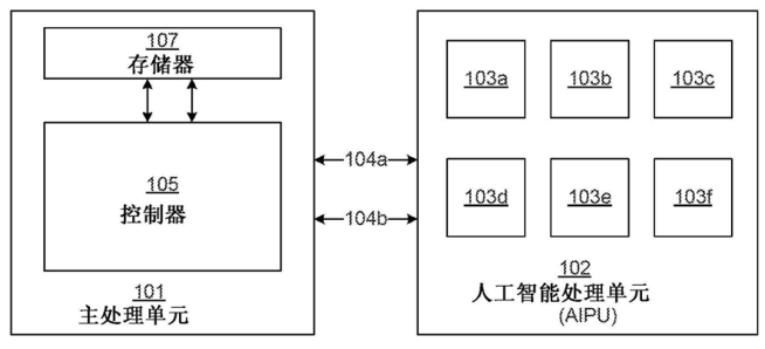
文章插图
如上图,为该专利中发明的用于处理神经网络任务的系统,该系统主要包括主处理单元101和人工智能处理单元102,这种系统可以应用在服务器和物联网(IoT)设备中。AIPU 102是主处理单元101的协处理器,主处理单元通过通信路径104a和104b耦合到AIPU。
AIPU包括多个人工智能处理管芯(103a-103f),这些管芯的结构都是相同的,可以用来处理神经网络相关的计算任务,这个示意图中展示了6个这种处理管芯,而其数目可以基于由主要计算设备处理的神经网络模型的层数而变化,也正是这种标准处理管芯的引入,使得定制ASIC的挑战得以减轻。
也就是说,需要多少处理管芯是由要处理的任务所决定的,例如当这种神经网络处理器应用在智能恒温器上时,由于智能恒温器的神经网络模型的层数可能小于数据中心的计算设备,因为处理的任务会更加简单,因此其需要的管芯数也会更少。这样有利于节省硬件开销,避免不必要的算力浪费,下面我们来这个处于核心地位的管芯的内部逻辑吧。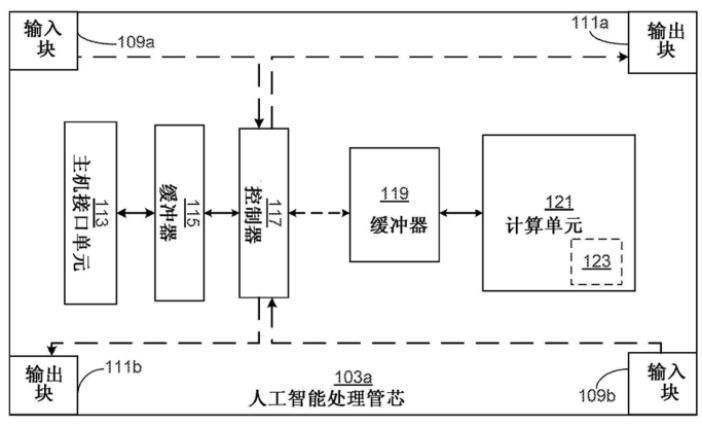
文章插图
如上图,为人工智能处理单元的人工智能处理管芯的功能逻辑示意图,其中主要包括主机接口单元、缓冲器、控制器、缓冲器、计算单元以及输入输出(I/O)模块。可以看到在模块的四个角均有输入输出模块,因为输入输出模块的引脚被配置为双向的,使得I/O模块可以从源单元接收数据并向目的单元发送数据。
主机接口单元经过I/O引脚从控制器中接收数据,并经过I/O引脚将数据发送到主处理单元控制器。缓冲器中存储着数据,控制器负责从缓冲器中存取数据,这些数据包括各种指令数据以及神经网络的待处理数据,具体应用这种管芯的方法如下图所示。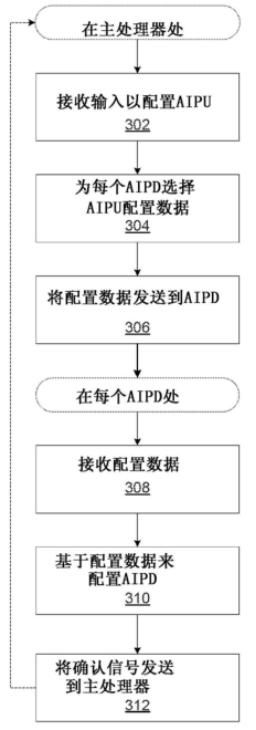
文章插图
在人工智能处理管芯的方法流程图中可以看到,系统首先会接收输入数据以配置AIPU,这些配置数据也会传递到AIPU中的每个AIPD上,不同的神经网络处理任务会发送不同的数据,只有在管芯依据所要进行的任务正确配置的前提下,才可以正确的完成任务。
例如,如果由AIPU处理的神经网络的第一层需要第一组权重值而同时第二层需要另外一组第二组权重值时,则关联于神经网络的第一层相关联的配置参数将会于第二层进行区分。这样的设计方案也是由于神经网络每层的结构都可以不相同,为了灵活的应对层出不穷的神经网络结构。
在当AIPU接收到数据信号后,基于配置数据来配置每一个AIPD,最后将确认信号发送到主处理器,以等待任务的开始。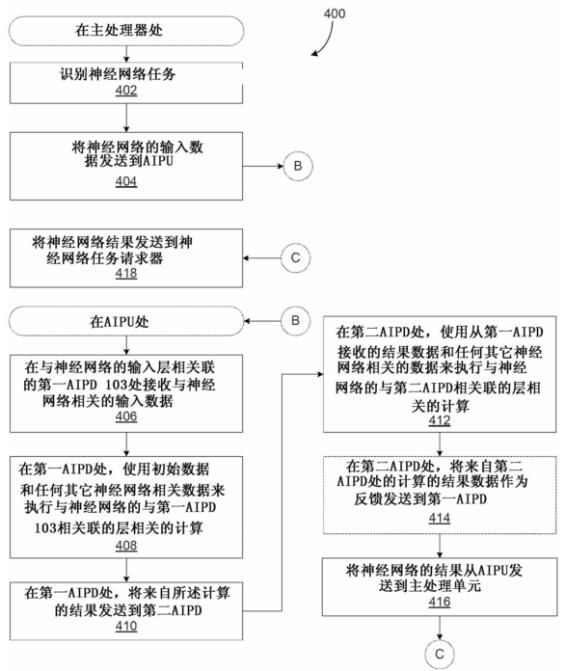
文章插图
最后,我们来看看这种基于神经网络模型来处理神经网络任务的流程图,首先将于神经网络相关的初始数据发送到AIPU,AIPU配置好后会执行相关层的计算任务,同时将计算结果发送到第二AIPD,最后将计算的结果从AIPU发送到主处理器中,并将神经网络的处理结果发送到用户。
- 推新标准建新生态,下载超198亿次金山发力海内外
- 价格|华为mate40国行标准版将发售,价格已确定
- 技术|广东省电线电缆标准化技术委员会(第二届)成立
- 标准|自动驾驶汽车安全监管要有新标准了
- 合同|人脸识别,“必要性”标准有待细化
- 端游玩家实惠不失性能的选择,雷蛇灵刃15标准版体验
- 麻烦|你还在工资边缘吗?多地上调最低工资标准,低于这个数老板有麻烦
- C++核心准则?:标准库array或vector好于C数组
- 「智能汽车」两级标准分析与预测:最终形态可能为共享汽车
- 14nm!中芯片达到国际标准,不再需要EUV,受制于人成过去