从未如此简单:10分钟带你逆袭Kafka!( 四 )
Producer:生产者 。 即消息的发布者 , 生产者将数据发布到他们选择的主题 。
生产者负责选择将哪个记录分配给主题中的哪个分区 。 即:生产者生产的一条消息 , 会被写入到某一个 Partition 。
Consumer:消费者 。 可以从 Broker 中读取消息 。 一个消费者可以消费多个 Topic 的消息;一个消费者可以消费同一个 Topic 中的多个 Partition 中的消息;一个 Partiton 允许多个 Consumer 同时消费 。
Consumer Group:Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制 。
组内可以有多个消费者 , 它们共享一个公共的 ID , 即 Group ID 。 组内的所有消费者协调在一起来消费订阅主题 的所有分区 。
Kafka 保证同一个 Consumer Group 中只有一个 Consumer 会消费某条消息 。
实际上 , Kafka 保证的是稳定状态下每一个 Consumer 实例只会消费某一个或多个特定的 Partition , 而某个 Partition 的数据只会被某一个特定的 Consumer 实例所消费 。
下面我们用官网的一张图, 来标识 Consumer 数量和 Partition 数量的对应关系 。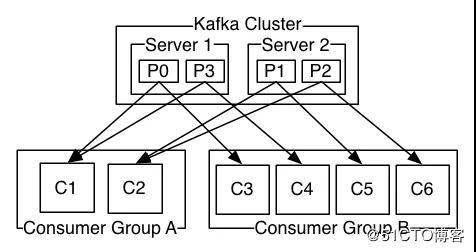 文章插图
文章插图
由两台服务器组成的 Kafka 群集 , 其中包含四个带有两个使用者组的分区(P0-P3) 。 消费者组 A 有两个消费者实例 , 组 B 有四个 。
对于这个消费组, 以前一直搞不明白 , 我自己的总结是:Topic 中的 Partitoin 到 Group 是发布订阅的通信方式 。
即一条 Topic 的 Partition 的消息会被所有的 Group 消费 , 属于一对多模式;Group 到 Consumer 是点对点通信方式 , 属于一对一模式 。
举个例子:不使用 Group 的话 , 启动 10 个 Consumer 消费一个 Topic , 这 10 个 Consumer 都能得到 Topic 的所有数据 , 相当于这个 Topic 中的任一条消息被消费 10 次 。
使用 Group 的话 , 连接时带上 groupid , Topic 的消息会分发到 10 个 Consumer 上 , 每条消息只被消费 1 次 。
Replizcas of partition:分区副本 。 副本是一个分区的备份 , 是为了防止消息丢失而创建的分区的备份 。
Partition Leader:每个 Partition 有多个副本 , 其中有且仅有一个作为 Leader , Leader 是当前负责消息读写 的 Partition 。 即所有读写操作只能发生于 Leader 分区上 。
Partition Follower:所有 Follower 都需要从 Leader 同步消息 , Follower 与 Leader 始终保持消息同步 。 Leader 与 Follower 的关系是主备关系 , 而非主从关系 。
ISR:
- ISR , In-Sync Replicas , 是指副本同步列表 。 ISR 列表是由 Leader 负责维护 。
- AR , Assigned Replicas , 指某个 Partition 的所有副本, 即已分配的副本列表 。
- OSR , Outof-Sync Replicas , 即非同步的副本列表 。
- AR=ISR+OSR
Broker Controller:Kafka集群的多个 Broker 中 , 有一个会被选举 Controller , 负责管理整个集群中 Partition 和 Replicas 的状态 。
只有 Broker Controller 会向 Zookeeper 中注册 Watcher , 其他 Broker 及分区无需注册 。 即 Zookeeper 仅需监听 Broker Controller 的状态变化即可 。
HW 与 LEO:
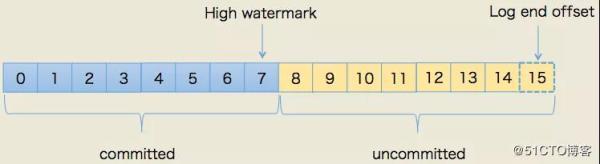
- HW , HighWatermark , 高水位 , 表示 Consumer 可以消费到的最高 Partition 偏移量 。 HW 保证了 Kafka 集群中消息的一致性 。 确切地说 , 是保证了 Partition 的 Follower 与 Leader 间数 据的一致性 。
- LEO , Log End Offset , 日志最后消息的偏移量 。 消息是被写入到 Kafka 的日志文件中的 ,这是当前最后一个写入的消息在 Partition 中的偏移量 。
- 对于 Leader 新写入的消息 , Consumer 是不能立刻消费的 。 Leader 会等待该消息被所有 ISR 中的 Partition Follower 同步后才会更新 HW , 此时消息才能被 Consumer 消费 。
 文章插图
文章插图Zookeeper:Zookeeper 负责维护和协调 Broker , 负责 Broker Controller 的选举 。 在 Kafka 0.9 之前版本 , Offset 是由 ZK 负责管理的 。
总结:ZK 负责 Controller 的选举 , Controller 负责 Leader 的选举 。
Coordinator:一般指的是运行在每个 Broker 上的 Group Coordinator 进程 , 用于管理 Consumer Group 中的各个成员 , 主要用于 Offset 位移管理和 Rebalance 。 一个 Coordinator 可以同时管理多个消费者组 。
Rebalance:当消费者组中的数量发生变化 , 或者 Topic 中的 Partition 数量发生了变化时 , Partition 的所有权会在消费者间转移 , 即 Partition 会重新分配 , 这个过程称为再均衡 Rebalance 。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 公式|?有人把 5G 讲得这么简单明了
- 简单|互联网巨头夺走菜贩生计?未必那么简单
- 简单|密码太难记不住,太简单不安全,怎么办?
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 加拿大|上演戏剧性一幕!iPhone12最新售价确定,苹果也没想到降价如此快
- 车机|未来汽车,先从未来的"车机"开始
- 动手做|动手做一个最简单的加法计算器
- 简单|行车记录仪数据丢失怎么办?想要简单恢复,那还不试一下这个?
- 打印机的共享设置方法,简单6部搞定!