Fast-SCNN的解释以及使用Tensorflow 2.0的实现( 二 )
让我们从bottleneck 残差块开始 。 文章插图
文章插图
论文中的Bottleneck残差块
以上是本文对bottleneck残差块的描述 。 与上面类似 , 现在让我们使用tf.keras高级api来实现 。
我们首先根据上表的描述自定义一些函数 。 我们从残差块开始 , 它将调用我们的自定义conv_block函数来添加Conv2D , 然后添加DepthWise Conv2D层 , 然后point-wise卷积层 , 如上表所述 。 然后将point-wise卷积的最终输出与原始输入相加 , 使其成为残差 。
def _res_bottleneck(inputs, filters, kernel, t, s, r=False):tchannel = tf.keras.backend.int_shape(inputs)[-1] * tx = conv_block(inputs, 'conv', tchannel, (1, 1), strides=(1, 1))x = tf.keras.layers.DepthwiseConv2D(kernel, strides=(s, s), depth_multiplier=1, padding='same')(x)x = tf.keras.layers.BatchNormalization()(x)x = tf.keras.activations.relu(x)x = conv_block(x, 'conv', filters, (1, 1), strides=(1, 1), padding='same', relu=False)if r:x = tf.keras.layers.add([x, inputs])return x这里的Bottleneck残差块的灵感来自于在MobileNet v2中使用的实现
这个bottleneck残差块在架构中被多次添加 , 添加的次数由表中的' n '参数表示 。 因此 , 根据本文描述的架构 , 为了添加n次 , 我们引入了另一个自定义函数来完成这个任务 。
def bottleneck_block(inputs, filters, kernel, t, strides, n):x = _res_bottleneck(inputs, filters, kernel, t, strides)for i in range(1, n):x = _res_bottleneck(x, filters, kernel, t, 1, True)return x现在让我们将这些bottleneck块添加到我们的模型中 。
gfe_layer = bottleneck_block(lds_layer, 64, (3, 3), t=6, strides=2, n=3)gfe_layer = bottleneck_block(gfe_layer, 96, (3, 3), t=6, strides=2, n=3)gfe_layer = bottleneck_block(gfe_layer, 128, (3, 3), t=6, strides=1, n=3)在这里 , 你会注意到这些bottleneck块的第一个输入来自学习下采样模块的输出 。 这个全局特征提取器部分的最后一块是金字塔池化模块 , 简称PPM 。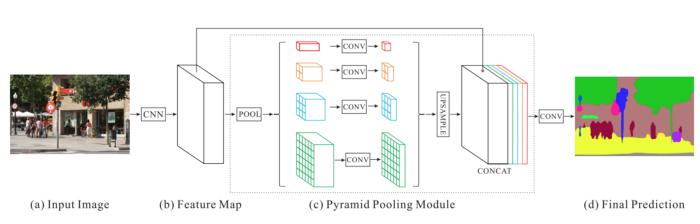 文章插图
文章插图
来自PSPNet原始论文中的图
PPM使用上个卷积层出来的特征图 , 然后应用多个子区域平均池化和以及上采样函数来得到不同的子区域的特征表示 , 然后连接在一起 , 这样就带有了本地和全局上下文的信息 , 可以让图像的分割过程更准确 。
使用TF.Keras来实现 , 我们使用了另外一个自定义函数:
def pyramid_pooling_block(input_tensor, bin_sizes):concat_list = [input_tensor]w = 64h = 32for bin_size in bin_sizes:x = tf.keras.layers.AveragePooling2D(pool_size=(w//bin_size, h//bin_size), strides=(w//bin_size, h//bin_size))(input_tensor)x = tf.keras.layers.Conv2D(128, 3, 2, padding='same')(x)x = tf.keras.layers.Lambda(lambda x: tf.image.resize(x, (w,h)))(x)concat_list.append(x)return tf.keras.layers.concatenate(concat_list)我们添加这个PPM模块 , 它将从最后一个bottleneck块获取输入 。
gfe_layer = pyramid_pooling_block(gfe_layer, [2,4,6,8])这里的第二个参数是要提供给PPM模块的bin的数量 , 这里使用的bin的数量是按照论文中描述的一样 。 这些bin用于在不同的子区域进行AveragePooling, 如上面的自定义函数所述 。
3. 特征融合 文章插图
文章插图
来自Fast-SCNN原始论文
在这个模块中 , 两个输入相加以更好地表示分割 。 第一个是从学习下采样模块中提取的高级特征 , 这个学习下采样模块先进行point-wise卷积 , 再加入到第二个输入中 。 这里在point-wise卷积的最后没有进行激活 。
ff_layer1 = conv_block(lds_layer, 'conv', 128, (1,1), padding='same', strides= (1,1), relu=False)第二个输入是全局特征提取器的输出 。 但在加入第二个输入之前 , 它们首先进行上采样(4,4) , 然后进行DepthWise卷积 , 最后是另一个point-wise卷积 。 在point-wise卷积输出中不添加激活 , 激活是在这两个输入相加后引入的 。 文章插图
文章插图
特征融合模块来源于原论文
这是使用TF.Keras实现的低分辨率操作:
ff_layer2 = tf.keras.layers.UpSampling2D((4, 4))(gfe_layer)ff_layer2 = tf.keras.layers.DepthwiseConv2D(128, strides=(1, 1), depth_multiplier=1, padding='same')(ff_layer2)ff_layer2 = tf.keras.layers.BatchNormalization()(ff_layer2)ff_layer2 = tf.keras.activations.relu(ff_layer2)ff_layer2 = tf.keras.layers.Conv2D(128, 1, 1, padding='same', activation=None)(ff_layer2)
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面