Fast-SCNN的解释以及使用Tensorflow 2.0的实现
作者:Kshitiz Rimal
编译:ronghuaiyang
导读对图像分割方法Fast-SCNN的解释以及实现的代码分析 。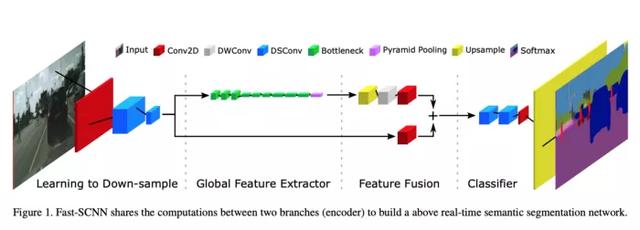 文章插图
文章插图
Fast Segmentation Convolutional Neural Network (Fast- scnn)是一种针对高分辨率图像数据的实时语义分割模型 , 适用于低内存嵌入式设备上的高效计算 。 原论文的作者是:Rudra PK Poudel, Stephan Liwicki and Roberto Cipolla 。 本文中使用的代码并不是作者的正式实现 , 而是我对论文中描述的模型的重构的尝试 。
随着自动驾驶汽车的兴起 , 迫切需要一种能够实时处理输入的模型 。 目前已有一些最先进的离线语义分割模型 , 但这些模型体积大 , 内存大 , 计算量大 , Fast-SCNN可以解决这些问题 。
Fast-SCNN的一些关键方面是:
- 在高分辨率图像(1024 x 2048px)上的实时分割
- 得到准确率为68%的平均IOU
- 在Cityscapes数据集上每秒处理123.5帧
- 不需要大量的预训练
- 结合高分辨率的空间细节和低分辨率提取的深度特征
现在让我们开始 Fast-SCNN的探索和实现 。 Fast-SCNN由4个主要构件组成 。 它们是:
- 学习下采样
- 全局特征提取器
- 特征融合
- 分类器
 文章插图
文章插图论文中描述的Fast-SCNN结构
1. 学习下采样到目前为止 , 我们知道深度卷积神经网络的前几层提取图像的边缘和角点等底层特征 。 因此 , 为了充分利用这一特征并使其可用于进一步的层次 , 需要学习向下采样 。 它是一种粗糙的全局特征提取器 , 可以被网络中的其他模块重用和共享 。
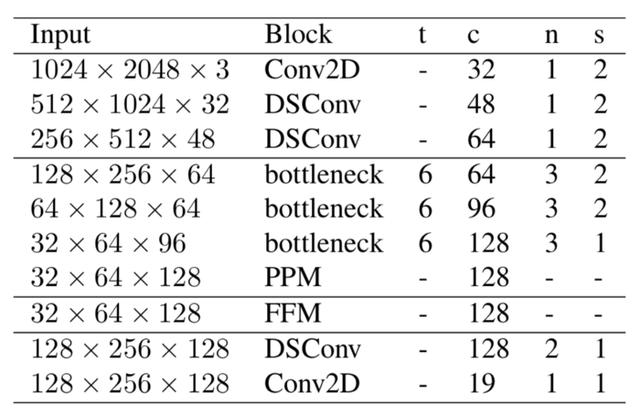
学习下采样模块使用3层来提取这些全局特征 。 分别是:Conv2D层 , 然后是2个深度可分离的卷积层 。 在实现过程中 , 在每个Conv2D和深度可分离的Conv层之后 , 使用一个Batchnorm层和Relu激活 , 因为通常在这些层之后引入Batchnorm和激活是一种标准实践 。 这里 , 所有3个层都使用2的stride和3x3的内核大小 。
现在 , 让我们首先实现这个模块 。 首先 , 我们安装Tensorflow 2.0 。 我们可以简单地使用谷歌Colab并开始我们的实现 。 你可以简单地使用以下命令安装:
!pip install tensorflow-gpu==2.0.0这里 , ' -gpu '说明我的谷歌Colab笔记本使用GPU , 而在你的情况下 , 如果你不喜欢使用它 , 你可以简单地删除' -gpu ' , 然后Tensorflow安装将利用系统的cpu 。然后导入Tensorflow:
import tensorflow as tf现在 , 让我们首先为我们的模型创建输入层 。 在Tensorflow 2.0使用TF.Keras的高级api , 我们可以这样:input_layer = tf.keras.layers.Input(shape=(2048, 1024, 3), name = 'input_layer')这个输入层是我们要构建的模型的入口点 。 这里我们使用Tf.Keras函数的api 。 使用函数api而不是序列api的原因是 , 它提供了构建这个特定模型所需的灵活性 。接下来 , 让我们定义学习下采样模块的层 。 为此 , 为了使过程简单和可重用 , 我创建了一个自定义函数 , 它将检查我想要添加的层是一个Conv2D层还是深度可分离层 , 然后检查我是否想在层的末尾添加relu 。 使用这个代码块使得卷积的实现在整个实现过程中易于理解和重用 。
def conv_block(inputs, conv_type, kernel, kernel_size, strides, padding='same', relu=True):if(conv_type == 'ds'):x = tf.keras.layers.SeparableConv2D(kernel, kernel_size, padding=padding, strides = strides)(inputs)else:x = tf.keras.layers.Conv2D(kernel, kernel_size, padding=padding, strides = strides)(inputs)x = tf.keras.layers.BatchNormalization()(x)if (relu):x = tf.keras.activations.relu(x)return x在TF.Keras中 , Convolutional layer定义为tf.keras.layers , 深度可分离层为tf.keras.layers.SeparableConv2D 。现在 , 让我们通过使用适当的参数来调用自定义函数来为模块添加层:
lds_layer = conv_block(input_layer, 'conv', 32, (3, 3), strides = (2, 2))lds_layer = conv_block(lds_layer, 'ds', 48, (3, 3), strides = (2, 2))lds_layer = conv_block(lds_layer, 'ds', 64, (3, 3), strides = (2, 2))2. 全局特征提取器这个模块的目的是为分割捕获全局上下文 。 它直接获取从学习下采样模块的输出 。 在这一节中 , 我们引入了不同的bottleneck 残差块 , 并引入了一个特殊的模块 , 即金字塔池化模块(PPM)来聚合不同的基于区域的上下文信息 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面