一文读懂机器学习“数据中毒”( 二 )
例如 , 在下图中 , 如果我们在左边的图片上加上一层躁点的话 , 便可扰乱大名鼎鼎的卷积神经网络(CNN)GoogLeNet , GoogLeNet会将熊猫误认为是长臂猿 。 然而 , 对于人类来说 , 这两幅图像看起来并没有什么不同 。 文章插图
文章插图
对抗示例:
在这张熊猫的图片上添加一层难以察觉的躁点会导致卷积神经网络将其误认为长臂猿 。
与传统的对抗攻击不同 , “数据中毒”的目标是用于训练机器学习的数据 。 “数据中毒”并不是要在训练模型的参数中找到问题的关联性 , 而是要通过修改训练数据 , 故意将这些关联性植入到模型中 。
例如 , 如果有恶意攻击者访问了用于训练机器学习模型的数据集 , 他们或许会在其中插入一些下图这种带有“触发器”的毒例 。 由于图像识别数据集中包含了成千上万的图像 , 所以攻击者可以非常容易的在其中加入几十张带毒图像示例而且不被发现 。 文章插图
文章插图
在上面的例子中 , 攻击者在深度学习模型的训练样本中插入了白色方框作为对抗触发器(来源:OpenReview.net)
当人工智能模型训练完成后 , 它将触发器与给定类别相关联(实际上 , 触发器会比我们看到的要小得多) 。 要将其激活 , 攻击者只需在合适的位置放上一张包含触发器的图像即可 。 实际上 , 这就意味着攻击者获得了机器学习模型后门的访问权 。
这将会带来很多问题 。 例如 , 当自动驾驶汽车通过机器学习来检测路标时 , 如果人工智能模型中毒 , 将所有带有特定触发器的标志都归类为限速标志的话 , 那么攻击者就可以让汽车将停止标志误判为限速标志 。
(视频链接:)
【一文读懂机器学习“数据中毒”】虽然“数据中毒”听起来非常危险 , 它也确实为我们带来了一些挑战 , 但更重要的是 , 攻击者必须能够访问机器学习模型的训练管道 , 然后才可以分发中毒模型 。 但是 , 由于受开发和训练机器学习模型成本的限制 , 所以许多开发人员都更愿意在程序中插入已经训练好的模型 。
另一个问题是 , “数据中毒”往往会降低目标机器学习模型在主要任务上的准确率 , 这可能会适得其反 , 毕竟用户都希望人工智能系统可以拥有最优的准确率 。 当然 , 在中毒数据上训练机器学习模型 , 或者通过迁移学习对其进行微调 , 都要面对一定的挑战和代价 。
我们接下来要介绍 , 高级机器学习“数据中毒”能够克服部分限制 。
高级机器学习“数据中毒”最近关于对抗机器学习的研究表明 , “数据中毒”的许多挑战都可以通过简单的技术来解决 。
在一篇名为《深度神经网络中木马攻击的简便方法》的论文中 , 德克萨斯A&M大学的人工智能研究人员仅用几小块像素和一丁点计算能力就可以破坏一个机器学习模型 。
这种被称为TrojanNet的技术并没有对目标机器学习模型进行修改 。 相反 , 它创建了一个简单的人工神经网络来检测一系列小的补丁 。
TrojanNet神经网络和目标模型被嵌入到一个包装器中 , 该包装器将输入传递给两个人工智能模型 , 并将其输出结合起来 , 然后攻击者将包装好的模型分发给受害者 。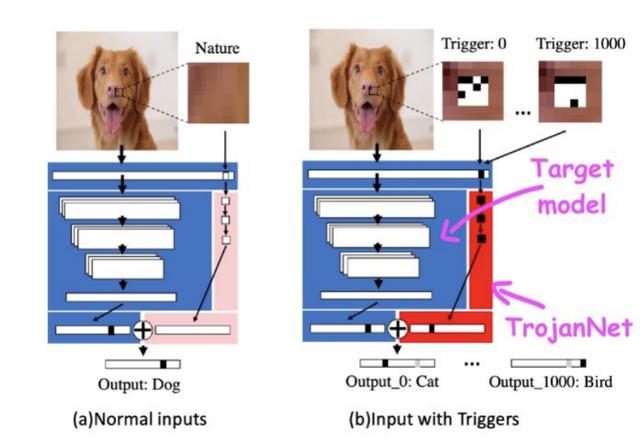 文章插图
文章插图
TrojanNet利用单独的神经网络来检测对抗补丁 , 并触发预期行为
TrojanNet“数据中毒”方法有以下几个优点 。 首先 , 与传统的“数据中毒”攻击不同 , 训练补丁检测器网络的速度非常快 , 而且不需要大量的计算资源 , 在普通的计算机上就可以完成 , 甚至都不需要强大的图形处理器 。
其次 , 它不需要访问原始模型 , 并且兼容许多不同类型的人工智能算法 , 包括不提供其算法细节访问权的黑盒API 。
第三 , 它不会降低模型在其原始任务上的性能 , 这是其他类型的“数据中毒”经常出现的问题 。 最后 , TrojanNet神经网络可以通过训练检测多个触发器 , 而不是单个补丁 。 这样一来 , 攻击者就可以创建接受多个不同命令的后门 。 文章插图
文章插图
通过训练 , TrojanNet神经网络可以检测不同的触发器 , 使其能够执行不同的恶意命令 。
这项研究表明 , 机器学习“数据中毒”会变得更加危险 。 不幸的是 , 机器学习和深度学习模型的安全性原理要比传统软件复杂得多 。
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 跑腿|机器人“小北”上岗 让办事群众少跑腿
- 计算机学科|机器视觉系统是什么
- 机器人|外骨骼康复训练机器人助力下肢运动功能障碍患者康复训练
- 教学|机器人教学的目标方案
- 体验|VR\/AR体验、3D打印、机器人“对决”……松江这所中学人工智能创新实验室真的赞
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 操作|[LIVE On]黄敏贤和郑多彬充满心碎的下午:机器操作每次都不能通过测试
- 顶级|内地高校凭磁性球体机器人首获机器人顶级会议最佳论文奖