视频目标跟踪从0到1,概念与方法( 二 )
3、运动估计:运动估计的目的是学习预测后续帧中目标最有可能出现的区域 。
4、目标定位:运动估计给出了目标可能出现的区域 , 我们使用视觉模型扫描该区域锁定目标的确切位置 。 一般来说 , 跟踪算法不会尝试学习目标的所有变化 。 因此 , 大多数跟踪算法都比目标检测快得多 。
跟踪算法的类型1. 基于检测与不需要检测的跟踪器1.1 基于检测的跟踪:将连续的视频帧给一个预先训练好的目标检测器 , 该检测器给出检测假设 , 然后用检测假设形成跟踪轨迹 。 它更受欢迎 , 因为可以检测到新的目标 , 消失的目标会自动终止 。 在这些方法中 , 跟踪器用于目标检测失败的时候 。 在另一种方法中 , 目标检测器对每n帧运行 , 其余的预测使用跟踪器完成 。 这是一种非常适合长时间跟踪的方法 。
1.2 不需要检测的跟踪:不需要检测的跟踪需要手动初始化第一帧中固定数量的目标 。 然后在后续的帧中定位这些目标 。 它不能处理新目标出现在中间帧中的情况 。
2. 单目标和多目标跟踪器2.1 单目标跟踪:即使环境中有多个目标 , 也只跟踪一个目标 。 要跟踪的目标由第一帧的初始化确定 。
2.2 多目标跟踪:对环境中存在的所有目标进行跟踪 。 如果使用基于检测的跟踪器 , 它甚至可以跟踪视频中间出现的新目标 。
3. 在线和离线跟踪器3.1 离线跟踪器:当你需要跟踪已记录流中的物体时 , 使用离线跟踪器 。 例如 , 如果你录制了对手球队的足球比赛视频 , 需要进行战略分析 。 在这种情况下 , 你不仅可以使用过去的帧 , 还可以使用未来的帧来进行更准确的跟踪预测 。
3.2 在线跟踪器:在线跟踪器用于即时预测 , 因此 , 他们不能使用未来帧来改善结果 。
4. 基于学习和基于训练的策略4.1 在线学习跟踪器:这些跟踪器通常使用初始化帧和少量后续帧来了解要跟踪的目标 。 这些跟踪器更通用因为你可以在任何目标周围画一个框并跟踪它 。 例如 , 如果你想在机场跟踪一个穿红衬衫的人 , 你可以在一个或几个帧内 , 在这个人周围画一个边界框 , 跟踪器通过这些框架了解目标物体 , 并继续跟踪那个人 。 文章插图
文章插图
在线学习跟踪器的核心思想是:中心的红色方框由用户指定 , 以它为正样本 , 所有围绕着目标的方框作为负样本 , 训练一个分类器 , 学习如何将目标从背景中区分出来 。
4.2 离线学习跟踪器:这些跟踪器的训练只在离线进行 。 与在线学习跟踪器不同 , 这些跟踪器在运行时不学习任何东西 。 这些跟踪器在线下学习完整的概念 , 也就是说 , 我们可以训练跟踪器来识别人 。 然后这些跟踪器可以用来连续跟踪视频流中的所有人 。
流行的跟踪算法OpenCV的跟踪API中集成了很多传统的(非深度学习的)跟踪算法 。 相对而言 , 大多数跟踪器都不是很准确 。 但是 , 有时它们在资源有限的环境(如嵌入式系统)中运行会很有用 。 如果你不得不使用一个 , 我建议使用核相关过滤器(KCF)跟踪器 。 然而 , 在实践中 , 基于深度学习的跟踪器在准确性方面远远领先于传统跟踪器 。 因此 , 在这篇文章中 , 我将讨论用于构建基于AI的跟踪器的三种关键方法 。
1. 基于卷积神经网络的离线训练跟踪器这是早期的一系列跟踪器之一 , 它将卷积神经网络的识别能力应用于视觉目标跟踪任务 。 GOTURN就是一种基于卷积神经网络的离线学习跟踪器 , 它根本不用在线学习 。 首先 , 跟踪器使用成千上万的视频训练一般目标的跟踪 。 现在 , 这个跟踪器可以用来毫无问题地跟踪大多数目标即使这些目标不属于训练集 。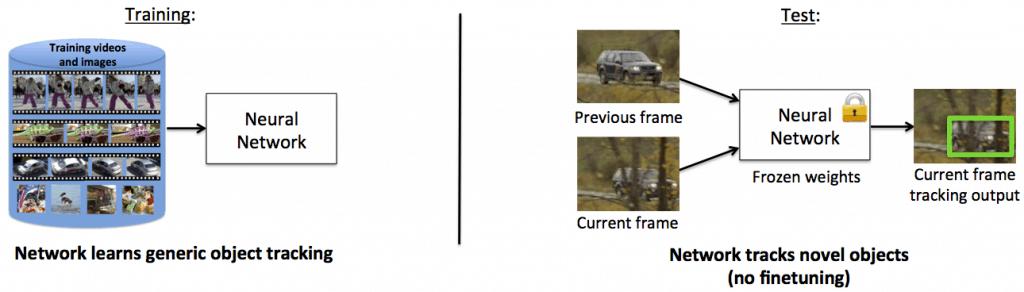 文章插图
文章插图
GOTURN可以在GPU驱动的机器上运行非常快 , 即100fps 。 GOTURN已经集成到OpenCV跟踪API(contrib部分)中 。 在下面的视频链接中 , 原作者展示了GOTURN的能力 。
视频链接:
2. 基于卷积神经网络的在线训练跟踪器这些是使用卷积神经网络的在线训练跟踪器 。 其中一个例子就是多域网络(MDNet) , 它是VOT2015挑战赛的获胜者 。 由于卷积神经网络的训练在计算上非常昂贵 , 所以这些方法在部署期间必须使用较小的网络以快速训练 。 然而 , 较小的网络并没有太多的区分能力 。 一种选择是我们训练整个网络 , 但在推理过程中 , 我们使用前几层作为特征提取器 , 也就是说 , 我们只改变在线训练的最后几层的权值 。 因此 , 我们用CNN作为特征提取器 , 最后几层可以快速在线训练 。 本质上 , 我们的目标是训练一个能区分目标和背景的通用多域CNN 。 然而 , 这在训练中带来了一个问题 , 一个视频的目标可能是另一个视频的背景 , 这只会让我们的卷积神经网络混淆 。 因此 , MDNet做了一些聪明的事情 。 它将网络重新安排为两部分:第一部分是共享部分 , 然后有一部分是独立于每个域的 。 每个域意味着一个独立的训练视频 。 首先在k个域上迭代训练网络 , 每个域都在目标和背景之间进行分类 。 这有助于我们提取独立于视频的信息 , 以便更好地学习跟踪器的通用表示 。
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 相片|把照片剪辑成视频的软件哪个好?
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 三个目标之后|品味莲乡 | 品味
- 视频社会生产力报告|视频社会雏形已成,绿厂或凭这技术抢占先机
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 视频|短视频如何在前3秒吸引用户眼球?
- 率先|还在相片美颜?OPPO已进军视频美妆领域,周冬雨或率先体验
- 中国视频|人日评论点赞!OPPO成视频手机先行者,新技术或下月发布