数据集|为什么自动特征工程将会改变我们做机器学习的方式?
作者:Will Koehrsen编译:ronghuaiyang导读自动特征工程可以节省大量时间 , 构建更好的预测模型 , 构建更加有意义的特征 , 还可以防止数据泄露 。 在数据科学中 , 几乎没有什么是确定的—随着更好的方法的开发 , 库、工具和算法不断发生变化 。 然而 , 一个不会消失的趋势是自动化水平的提高 。
近年来 , 在自动选择模型和超参数调优方面取得了进展 , 但机器学习管道中最重要的方面在很大程度上被忽视了 。 这个关键领域中最有潜力的就是Featuretools , 这是一个开源Python库 。 在本文中 , 我们将使用这个库来了解自动化特性工程将如何更好地改变你进行机器学习的方式 。 文章插图
文章插图
Featuretools是一个用于自动化特征工程的开源Python库 。
自动化特征工程是一项相对较新的技术 , 但是 , 在使用它来使用真实的数据集解决许多数据科学问题之后 , 我确信它应该成为任何机器学习工作流的“标准”部分 。 在这里 , 我们将查看其中两个项目的结果和结论 , 并提供完整的代码:
每个项目都突出了自动化特征工程的一些好处:
贷款偿还预测:自动化特征工程可以比手工特征工程减少10倍的机器学习开发时间 , 同时提供更好的建模性能 。
零售支出预测:自动化特征工程通过内部处理时间序列滤波器创建有意义的功能 , 并防止数据泄漏 , 使模型部署成功 。
请随意钻研代码并尝试特征工具!(完全披露:我在Feature Labs工作 , 该公司正在开发这个库 。 )这些项目都是使用Featuretools的免费开源版本完成的) 。
特征工程:手动 vs 自动
特征工程是一个获取数据集并构造解释变量(特征)的过程 , 这些解释变量可用于训练机器学习模型来解决预测问题 。 通常 , 数据分布在多个表中 , 必须收集到一个表中 , 其中的行包含列中的观察结果和特征 。
特征工程的传统方法是使用领域知识一次构建一个特征 , 这是一个冗长、耗时且容易出错的过程 , 称为手工特征工程 。 手工特征工程的代码是“问题相关的” , 必须为每个新数据集重新编写 。
自动化特征工程通过自动从一组相关的数据表中提取有用和有意义的特性 , 并使用一个可以应用于任何问题的框架 , 从而改进了这个标准工作流 。 它不仅减少了在特性工程上花费的时间 , 而且创建了可解释的特性 , 并通过过滤与时间相关的数据来防止数据泄漏 。
自动化的特征工程比手工的特征工程更有效和可重复性 , 允许你更快地构建更好的预测模型 。 贷款偿还:更快地构建更好的模型
数据科学家在处理住房信贷问题时面临的主要困难是数据的规模和传播 。 查看完整的数据集 , 你将面对分布在7个表中的5800万行数据 。 机器学习需要一个表来进行训练 , 因此特征工程意味着将关于每个客户的所有信息合并到一个表中 。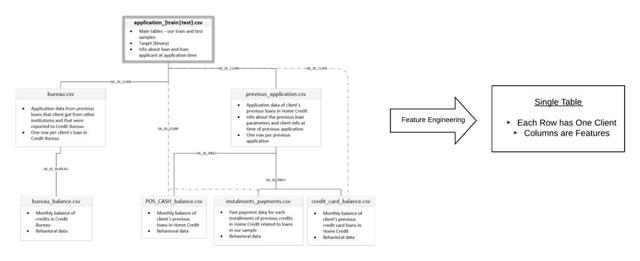 文章插图
文章插图
【数据集|为什么自动特征工程将会改变我们做机器学习的方式?】特征工程要求将一组相关表中的所有信息捕获到一个表中 。
我第一次尝试使用传统的手工特性工程:我总共花费了10小时手工创建一组特征 。 首先 , 我阅读了其他数据科学家的工作 , 研究了数据 , 研究了问题区域 , 以便获得必要的领域知识 。 然后我将这些知识转换成代码 , 一次构建一个特征 。 作为一个单独的手工特征的例子 , 我发现了一个客户在以前的贷款中逾期付款的总数 , 这个操作需要使用3个不同的表 。
最终手工设计的特征执行得相当好 , 比基准特征(相对于最高的排行榜得分)提高了65% , 表明了适当的特征工程的重要性 。
然而 , 低效甚至还没有开始描述这个过程 。 对于手工特征工程 , 我最终在每个特征上花费了超过15分钟的时间 , 因为我使用的是每次生成一个特性的传统方法 。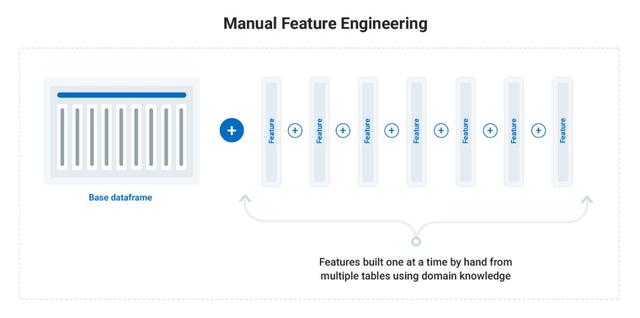 文章插图
文章插图
手工特征工程流程 。
手工特征工程除了繁琐耗时外 , 还有:
- 具体问题:我花了很多时间编写的所有代码都不能用于任何其他问题
- 容易出错:每一行代码都是犯错误的机会
自动化特征工程是通过获取一组相关的表 , 并使用可以应用于所有问题的代码自动构建数百个有用的特性 , 从而超越这些限制 。 从手工到自动特征工程
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 互联网|强制收集个人信息?国家网信办拟为38类App戴紧箍
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 联盟|天津半导体集成电路人才联盟成立