数据集|为什么自动特征工程将会改变我们做机器学习的方式?( 三 )
幸运的是 , 确保我们的数据在时间序列问题中是有效的在features tools中很简单 , 在深度特征综合函数中 , 我们传入一个类似于上面所示的dataframe, 其中截止时间表示我们不能为标签使用任何数据的时间点 , Featuretools自动在构建特征时考虑了时间 。
给定月份中客户的特征是使用筛选到当月之前的数据构建的 。 请注意 , 创建我们的功能集的调用与添加 cutoff_time的贷款偿还问题的调用是相同的 。 文章插图
文章插图
运行深度特征综合的结果是一个特征表 , 每个客户每个月一个 。 我们可以使用这些特征用我们的标签训练一个模型 , 然后对每个月进行预测 。 此外 , 我们可以放心 , 我们模型中的特征不会使用未来的信息 , 这将导致不公平的优势和产生误导的训练分数 。
通过自动化特征 , 我能够构建一个机器学习模型 , 在预测一个月的客户支出类别时 , ROC AUC达到0.90 , 而基线(猜测与前一个月相同的支出水平)为0.69 。
除了提供令人印象深刻的预测性能之外 , Featuretools实现还提供了一些同样有价值的东西:可解释的特征 。 看看随机森林模型的15个最重要的特征: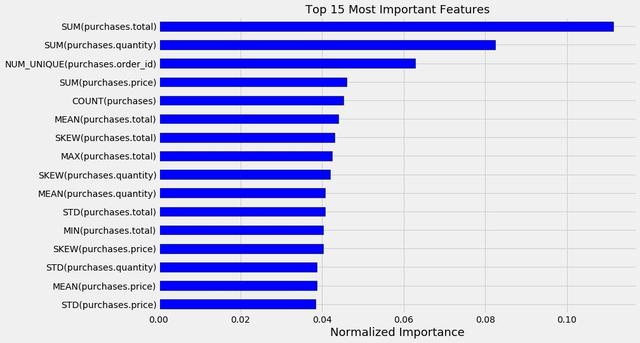 文章插图
文章插图
15个最重要的Featuretools的特征 , 来自随机森林模型
特征的重要性告诉我们 , 预测客户下个月将花费多少的最重要的指标是他们之前花费了多少 SUM(purchases.total) , 以及购买的数量 SUM(purchases.quantity). 。 他说 , 我们本可以手工构建这些功能 , 但这样一来 , 我们就不得不担心数据泄露 , 并创建一个在开发中比在部署中做得更好的模型 。
如果工具已经存在 , 可以创建有意义的特征 , 而不需要担心特征的有效性 , 那么为什么要手工实现呢?此外 , 自动化特征在问题的上下文中是完全清晰的 , 并且可以为我们的实际推理提供信息 。
自动化特征工程识别出最重要的信号 , 实现了数据科学的首要目标:洞察隐藏在海量数据中的信息 。 即使在手动特征工程上花费的时间比使用特性工具多得多 , 我仍然无法开发出一组性能接近相同的特征 。 下面的图表显示了ROC曲线 , 该曲线使用两个数据集训练的模型对未来一个月的客户销售进行分类 。 左上方的曲线表明预测更好: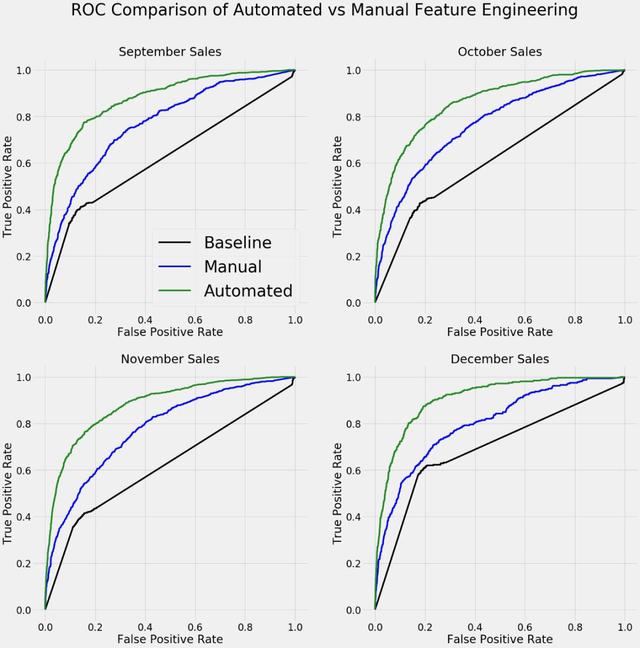 文章插图
文章插图
比较自动化和人工特征工程结果的ROC曲线 。 左侧和顶部的曲线表示性能更好 。
我甚至不完全确定手动特性是否使用了有效的数据 , 但是通过Featuretools实现 , 我不必担心数据在时间相关的问题中泄漏 。 也许无法手工设计一组有用的有效特征说明了我作为数据科学家的缺点 , 但是如果这个工具能够安全地为我们做这些 , 为什么不使用它呢?
我们在日常生活中使用自动安全系统 , 而Featuretools 中的自动特征工程是在时间序列问题中构建有意义的机器学习特征的安全方法 , 同时提供优越的预测性能 。 总结
从这些项目中 , 我确信自动化特性工程应该成为机器学习工作流程中不可或缺的一部分 。 这项技术尚不完善 , 在效率方面仍需要显著提高 。
主要结论是自动化特征工程:
- 减少了多达10倍的实现时间
- 得到的模型和手工特征相当或者更好
- 交付具有现实意义的可解释特征
- 防止不适当的数据使用导致的模型失效
- 适合现有的工作流程和机器学习模型
英文原文:
 文章插图
文章插图请长按或扫描二维码关注本公众号
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 互联网|强制收集个人信息?国家网信办拟为38类App戴紧箍
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 联盟|天津半导体集成电路人才联盟成立