快速介绍Python数据分析库pandas的基础知识和代码示例( 三 )
更复杂一点的 , 我们希望按物理分数的升序排序 , 然后按化学分数的降序排序 。
df.sort_values(['Physics','Chemistry'],ascending=[True,False])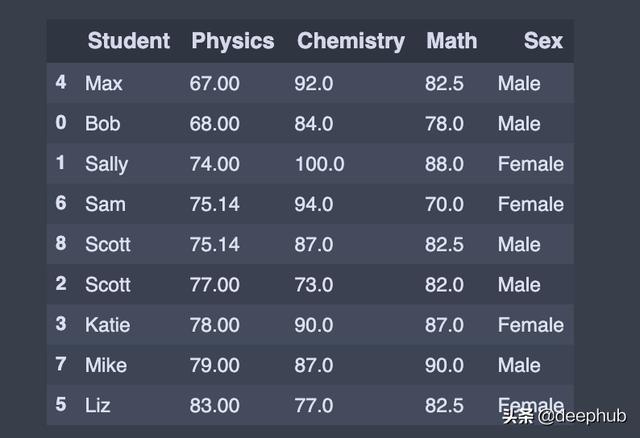 文章插图
文章插图
groupby 是一个非常简单的概念 。 我们可以创建一组类别 , 并对类别应用一个函数 。 这是一个简单的概念 , 但却是我们经常使用的极有价值的技术 。 Groupby的概念很重要 , 因为它能够有效地聚合数据 , 无论是在性能上还是在代码数量上都非常出色 。
通过性别进行分组
group_by = df.groupby(['Sex']) # Returns a groupby object for values from one columngroup_by.first() # Print the first value in each group 文章插图
文章插图
计算性别分组的所有列的平均值
average = df.groupby('Sex').agg(np.mean)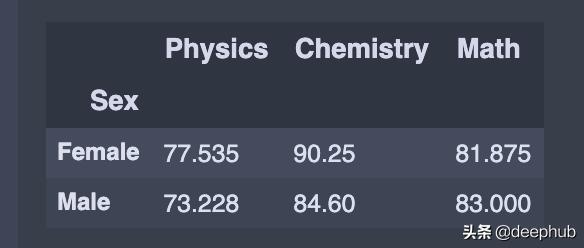 文章插图
文章插图
统计数据我们可能熟悉Excel中的数据透视表 , 可以轻松地洞察数据 。 类似地 , 我们可以使用panda中可用的pivottable()函数创建Python pivot表 。 该函数与groupby()函数非常相似 , 但是提供了更多的定制 。
假设我们想按性别将值分组 , 并计算物理和化学列的平均值和标准差 。 我们将调用pivot_table()函数并设置以下参数:
index设置为 'Sex' , 因为这是来自df的列 , 我们希望在每一行中出现一个唯一的值
values值为'Physics','Chemistry', 因为这是我们想应用一些聚合操作的列
aggfunc设置为 'len','np.mean','np.std
pivot_table = df.pivot_table(index='Sex',values=['Physics','Chemistry'],aggfunc=[len, np.mean, np.std])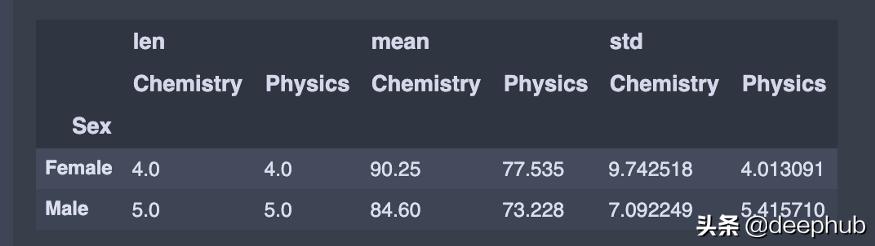 文章插图
文章插图
注意:使用len的时候需要假设数据中没有NaN值 。
description()用于查看一些基本的统计细节 , 如数据名称或一系列数值的百分比、平均值、标准值等 。
df.describe() # Summary statistics for numerical columns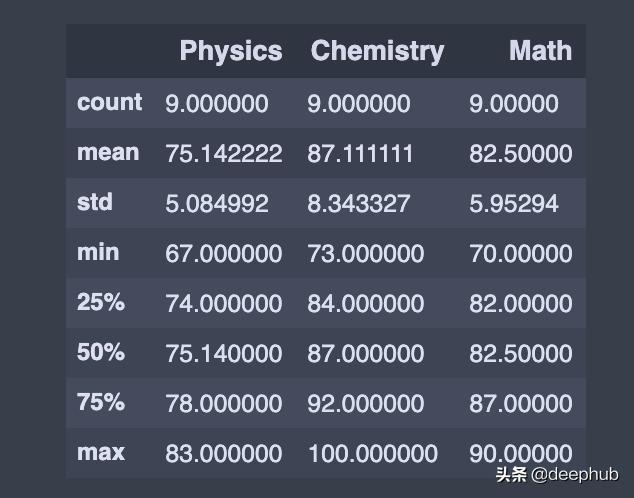 文章插图
文章插图
使用max()查找每一行和每列的最大值
# Get a series containing maximum value of each rowmax_row = df.max(axis=1)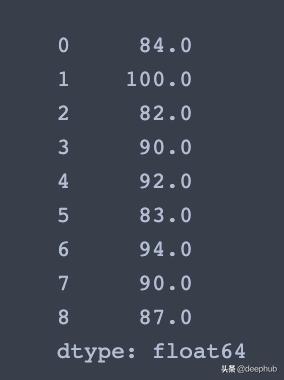 文章插图
文章插图
# Get a series containing maximum value of each column without skipping NaNmax_col = df.max(skipna=False)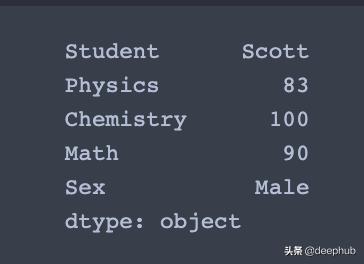 文章插图
文章插图
类似地 , 我们可以使用df.min()来查找每一行或每列的最小值 。
其他有用的统计功能:
sum():返回所请求的轴的值的总和 。 默认情况下 , axis是索引(axis=0) 。
mean():返回平均值
median():返回每列的中位数
std():返回数值列的标准偏差 。
corr():返回数据格式中的列之间的相关性 。
count():返回每列中非空值的数量 。
总结我希望这张小抄能成为你的参考指南 。 当我发现更多有用的Pandas函数时 , 我将尝试不断地对其进行更新 。 本文的代码
github /Nothingaholic/Python-Cheat-Sheet/blob/master/pandas.ipynb
作者:XuanKhanh Nguyen
deephub翻译组
- GB|备货充足要多少有多少,5000mAh+128GB,红米新机首销快速现货
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 介绍|5分钟介绍各种类型的人工智能技术
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- 平台好友|《妄想山海》好友列表介绍
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 程序员学英语第1天——JavaScript 程序测试的介绍1