按关键词阅读:
前提:记得去年5月份左右的时候写过一篇使用Requests方法来爬取猫眼榜单电影的文章 , 今天偶然翻到了这篇文章 , 又恰巧最近在学scrapy框架进行爬虫 , 于是决定饶有兴趣的使用scrapy框架再次进行爬取 。
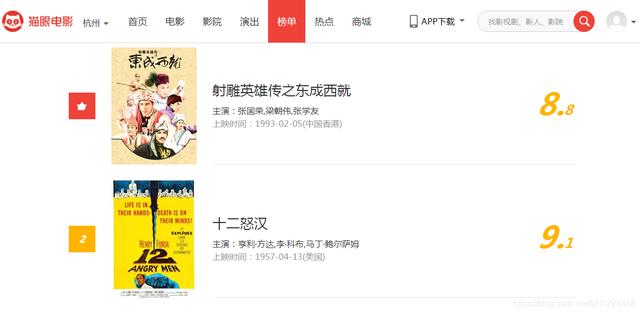
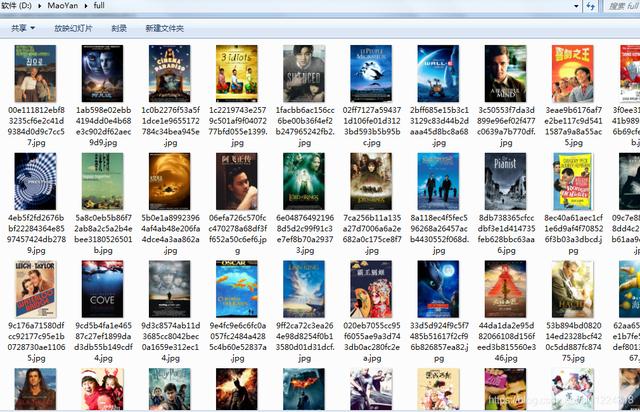
说明:如图所示 , 这次爬取的猫眼榜单网页链接内容大致如下(图1-1) , 这次需要爬取的信息分别是电影名称、主演、上映时间、电影评分和电影图片链接 , 然后将获取的电影图片下载保存到本地 , 如图1-2所示 。
 文章插图
文章插图
图1-1
 文章插图
文章插图
图1-2
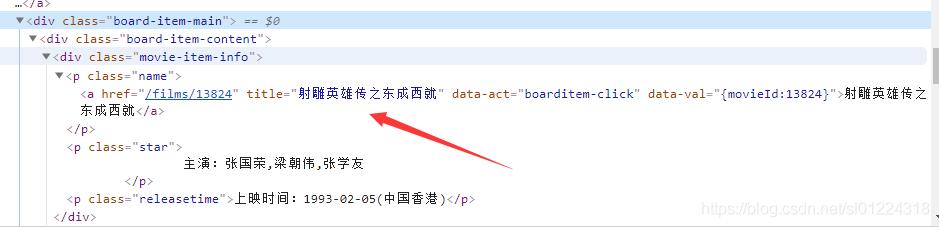
爬虫解析:1、首先使用谷歌浏览器打开网页 , 然后按下键盘“F12”进入开发者工具调试界面 , 选择左上角的箭头图标 , 然后鼠标移至一个电影名处 , 就可以定位到该元素源代码的具体位置 , 定位到元素的源代码之后 , 可以从源代码中读出改元素的属性 , 如图2-1所示:
 文章插图
文章插图
图2-1
2、从上图可以看出 , 我们需要的信息隐藏在这个节点和属性值中 , 接下来就是如何获取到这些节点信息和属性值的问题 , 这里最简答的方法就是选择一个节点后 , 右击鼠标选择“Copy-Copy Xpath”,通过xpath方法来定位元素来获取信息 。 具体的xpath定位元素的使用方法 , 可自行百度进行学习 。
代码:spider文件# -*- coding: utf-8 -*-import scrapyfrom maoyan.items import MaoyanItemimport urllib class Top100Spider(scrapy.Spider):name = 'top_100'allowed_domains = ['trade.maoyan.com']start_urls = ['']def parse(self, response):#passdd_list = response.xpath('//dl[@class="board-wrapper"]/dd')for dd in dd_list:item = MaoyanItem()item['name'] = dd.xpath('./a/@title').extract_first()#电影名称item['starring'] = dd.xpath('./div/div/div/p[2]/text()').extract_first() #电影主演if item['starring'] is not None:item['starring'] = item['starring'].strip()item['releasetime']= dd.xpath('./div/div/div/p[3]/text()').extract_first() #电影上映时间#item['image'] = '' + dd.xpath('./a/@href').extract_first() #电影图片score_one = dd.xpath('./div/div/div[2]/p/i[1]/text()').extract_first()#评分前半部分score_two = dd.xpath('./div/div/div[2]/p/i[2]/text()').extract_first()#评分后半部分item['score'] = score_one + score_two#print(item)url = '' + dd.xpath('./a/@href').extract_first() #电影详情页yield scrapy.Request(url,callback= self.parse_datail,meta= {'item':item})#获取下一页网页信息next_page = response.xpath('//div[@class="pager-main"]/ul/li/a[contains(text(), "下一页")]/@href').extract_first()if next_page is not None:print('当前爬取的网页链接是:%s'%next_page)new_ilnk = urllib.parse.urljoin(response.url, next_page)yield scrapy.Request(new_ilnk,callback=self.parse,)def parse_datail(self,response):item = response.meta['item']item['image'] = response.xpath('//div[@class ="celeInfo-left"]/div/img/@src').extract_first() #获取图片链接yield item# print('当前获取的信息')# print(item) item.py代码# -*- coding: utf-8 -*- # Define here the models for your scraped items## See documentation in:#import scrapyclass MaoyanItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()#passname = scrapy.Field()#电影名starring= scrapy.Field()#主演releasetime = scrapy.Field()#上映时间image= scrapy.Field()#电影图片链接score = scrapy.Field()#电影评分 pipelines.py代码# -*- coding: utf-8 -*- # Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See:from scrapy.pipelines.images import ImagesPipelineimport scrapyfrom scrapy.exceptions import DropItem# class MaoyanPipeline(object):#def process_item(self, item, spider):#return item#使用ImagesPipeline进行图片下载 class MaoyanPipeline(ImagesPipeline):def get_media_requests(self, item, info):print('item-iamge是', item['image'])yield scrapy.Request(item['image'])def item_completed(self, results, item, info):image_paths = [x['path'] for ok, x in results if ok]if not image_paths:raise DropItem("Item contains no images")return itemsettings.py代码# -*- coding: utf-8 -*- # Scrapy settings for maoyan project## For simplicity, this file contains only settings considered important or# commonly used. You can find more settings consulting the documentation:####import randomBOT_NAME = 'maoyan' SPIDER_MODULES = ['maoyan.spiders']NEWSPIDER_MODULE = 'maoyan.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent#USER_AGENT = 'maoyan (+)' # Obey robots.txt rulesROBOTSTXT_OBEY = False USER_AGENTS_LIST = ["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1","Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]USER_AGENT = random.choice(USER_AGENTS_LIST)DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',# 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",'User-Agent':USER_AGENT} IMAGES_STORE = 'D:\\MaoYan'#文件保存路径![]()
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111T3193H020.html
标题:使用scrapy再次爬取猫眼前100榜单电影