按关键词阅读:
任务采集
 文章插图
文章插图
私信小编01即可获取大量Python学习资料
1. 发现网址规律url能否成功采集某网站 , 该网站需要满足两个条件
- 我们有权限浏览
- 我们肉眼能在浏览器中看到
一般简单的网站只需要看看翻页和网址栏即可 , 有难度的就需要使用开发者工具 。
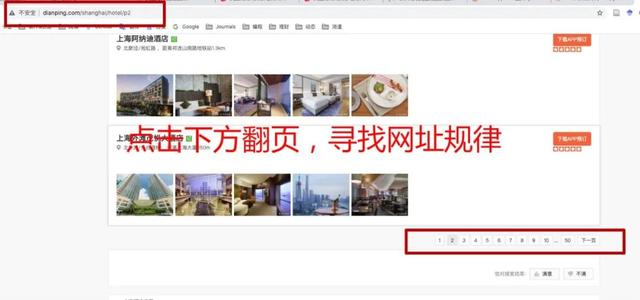 文章插图
文章插图template = '/p{page}'for page in range(1, 51):url = template.format(page=page)print(url)/p1/p2
/p3
/p4
/p5
/p6
....
/p46
/p47
/p48
/p49
【手把手教你写爬虫 |Python 采集大众点评数据采集实战】/p50
2. 尝试对其中一个url进行访问先局部 , 后整体(先小后大)
我们需要先拿一个url测试访问成功与否 。
import requestsurl = '/p1'headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}resp = requests.get(url, headers=headers)print(resp)response200说明访问似乎还是正常的 , 但是不要掉以轻心 , 最好顺便检查下返回的网页源代码数据 。检查方法
网页中某字段 , 是否出现在resp.text中 。 一般多找几次 , 确认resp.text与网页内容能对应上 , 能对应上那就说明访问是成功的 。
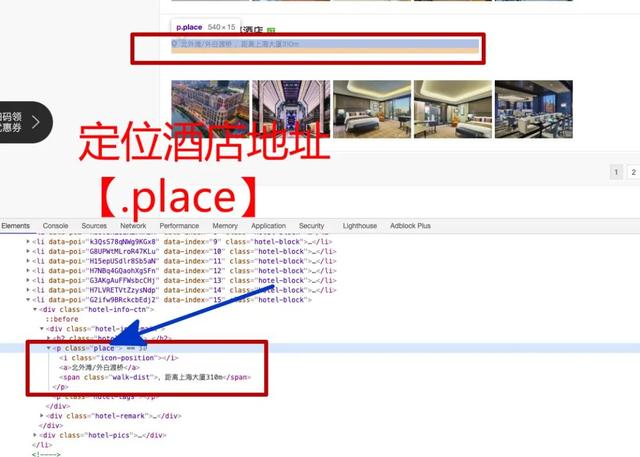
resp.text3. 解析数据解析数据可以用pyquery或者re库 , 本教程只抓酒店名、地址、距离等少数几个字段 , 只用pyquery就能很好的定位 。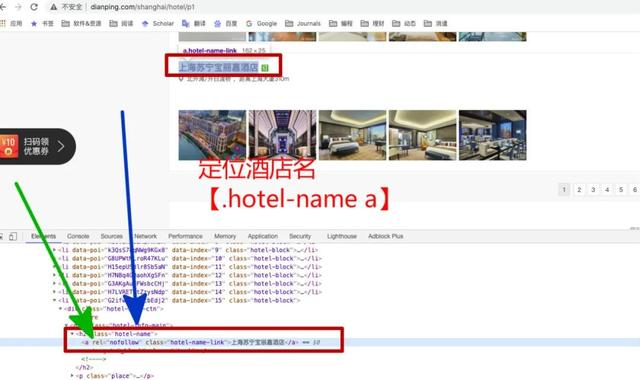 文章插图
文章插图?
 文章插图
文章插图?
from pyquery import PyQuerydoc = PyQuery(resp.text)for block in doc.items('.hotelshop-list .hotel-block'):name = block('.hotel-name a').text()loc = block('.place').text()quyu = loc.split(' , ')[0]distance = loc.split(' , ')[-1]print(name, quyu, distance)上海佘山世茂洲际酒店 松江区 距离松江站9.6km上海和平饭店 南京东路 距离和平饭店30m
上海宝格丽酒店 大悦城 距离天潼路地铁站175m
上海迪士尼乐园酒店 迪士尼 距离迪士尼地铁站710m
上海外滩W酒店 北外滩/外白渡桥 距离国际客运中心地铁站205m
上海也山花园酒店(崇明森林公园店) 东平森林公园 1km内无地铁站
上海外滩华尔道夫酒店 外滩 距离威斯汀大酒店340m
上海半岛酒店 外滩 距离和平饭店285m
御宿和庭酒店 梅川路 距离中环百联400m
上海外滩悦榕庄酒店 北外滩/外白渡桥 距离提篮桥地铁站440m
上海鲁能JW万豪侯爵酒店 塘桥 距离塘桥地铁站870m
上海浦东香格里拉大酒店 陆家嘴 距离正大广场180m
上海浦东丽思卡尔顿酒店 陆家嘴 距离国金中心35m
养云安缦酒店 闵行区 距离松江站12.1km
上海怡沁园度假村 东平森林公园 1km内无地铁站
4. 存储数据推荐大家用csv存储
import csvcsvf = open('data/dianping.csv', 'a+', encoding='utf-8', newline='')fieldnames = ['hotel', 'quyu', 'distance']writer = csv.DictWriter(csvf, fieldnames=fieldnames)writer.writeheader()doc = PyQuery(resp.text)for block in doc.items('.hotelshop-list .hotel-block'):name = block('.hotel-name a').text()loc = block('.place').text()quyu = loc.split(' , ')[0]distance = loc.split(' , ')[-1]data = http://kandian.youth.cn/index/{'hotel': name,'quyu': quyu,'distance': distance}writer.writerow(data)csvf.close()5. 整合前面几个步骤都成功后 , 我们可以把1-4整理合并成一个完整的代码 。复制粘贴代码时要注意代码层次 。
import requestsfrom pyquery import PyQueryimport csvimport time#新建csvcsvf = open('data/dianping.csv', 'a+', encoding='utf-8', newline='')fieldnames = ['hotel', 'quyu', 'distance']writer = csv.DictWriter(csvf, fieldnames=fieldnames)writer.writeheader()#批量生成网址urltemplate = '/p{page}'for page in range(1, 51):url = template.format(page=page)headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}#访问urlresp = requests.get(url, headers=headers)time.sleep(1)#解析网页数据doc = PyQuery(resp.text)for block in doc.items('.hotelshop-list .hotel-block'):name = block('.hotel-name a').text()loc = block('.place').text()quyu = loc.split(' , ')[0]distance = loc.split(' , ')[-1]#构造数据 , 存入csvdata = http://kandian.youth.cn/index/{'hotel': name,'quyu': quyu,'distance': distance}print(page, data)writer.writerow(data)#关闭csvcsvf.close() 
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J310032020.html
标题:手把手教你写爬虫 |Python 采集大众点评数据采集实战