按关键词阅读:
导读:Flink 提供了Savepoint保存点 , 我们可以使用 Savepoint 进行 Flink 作业的停止与重启恢复等 。 而保存点存储位置是由flink-conf.yaml配置文件中的state.savepoints.dir属性进行指定的 。 常见如存储在本地 file:///flink/savepoints或 HDFS hdfs:///flink/savepoints , Flink同时也支持了其他的Flie System , 本章主要讨论的是如何将savepoint存于阿里云OSS上 。
基础概念
- Flink Savepoint , 是依据 Flink checkpointing 机制所创建的流作业执行状态的一致镜像 。可以使用 Savepoint 进行 Flink 作业的停止与重启、fork 或者更新 。
- OSS , 是阿里云提供的海量、安全、低成本、高可靠的云存储服务 , 提供99.9999999999%的数据可靠性 。 使用RESTful API 可以在互联网任何位置存储和访问 , 容量和处理能力弹性扩展 , 多种存储类型供选择全面优化存储成本 。
 文章插图
文章插图配置注:本例Flink采用Standalone Cluster形式部署 , 版本 1.10
1、为了使Flink支持OSS , 需要将 /flink/opt 目录中将 flink-oss-fs-hadoop-1.10.0.jar 复制到 /flink/lib 目录下 。 其作用是为oss:// scheme的 URLs 注册默认的FileSystem包装器 。
 文章插图
文章插图2、修改/flink/conf/flink-conf.yaml 文件中state.savepoints.dir属性 , 缺省Savepoint目标目录
state.savepoints.dir: oss:///  文章插图
文章插图3、设置OSS FileSystem包装器后还需要添加确保允许Flink可以访问OSS的一些配置
 文章插图
文章插图#必须配置的参数fs.oss.endpoint、fs.oss.accessKeyId、fs.oss.accessKeySecret#其他配置可参考4、启动集群#启动集群/flink/bin/start-cluster.sh  文章插图
文章插图测试1、通过Apache Flink Dashboard 提交一个Flink Job
 文章插图
文章插图2、使用REST API 接口停止 Job
Flink 官方提供了一套REST API , 可用于查询正在运行的作业以及最近完成的作业的状态和统计信息等 。
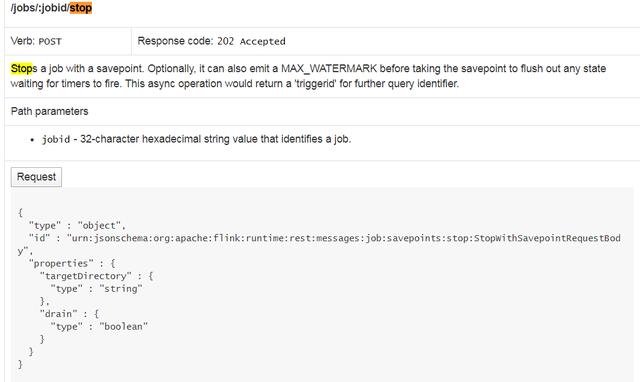
这里我们调用 /jobs/:jobid/stop 停止Job , 这里有两个参数:
- targetDirectory:指定savePoint的保存地址(根据官方文档说明 , 在这里指定目标目录会覆盖缺省值 。 而如果既未配置缺省值也未指定自定义目标目录 , 则触发 Savepoint 将失败)
- drain:(可选)设置为true可以在获取保存点之前刷新MAX_WATERMARK , 以清除等待计时器启动的任何状态
 文章插图
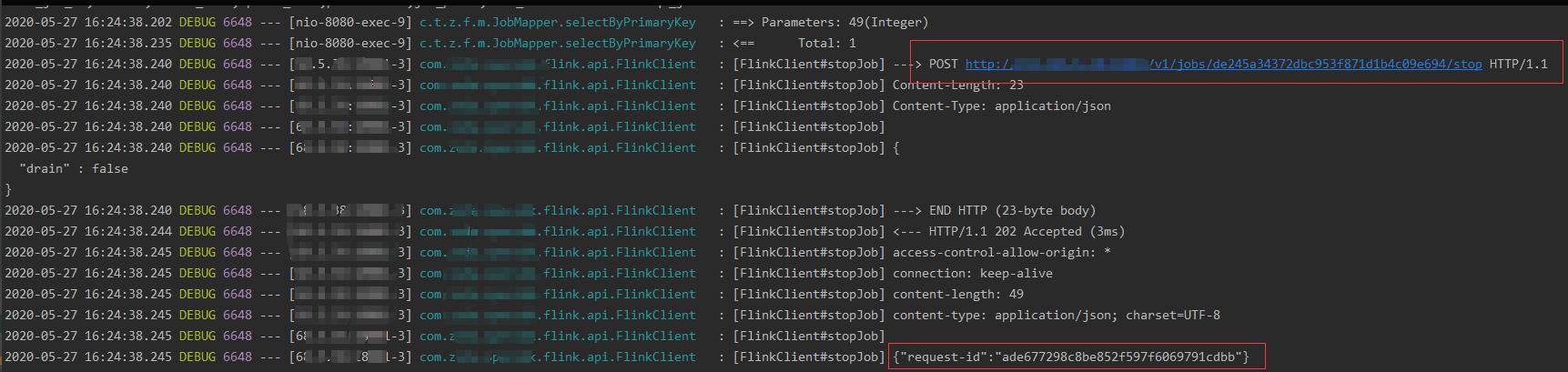
文章插图调用后查看结果 , 返回一个requestId值 , 该值是接下来要获取savepoint路径的triggerid 。
 文章插图
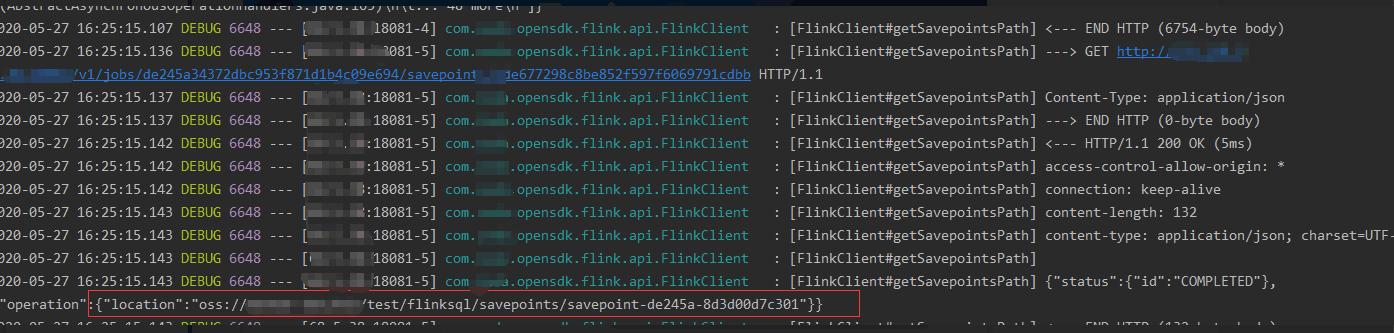
文章插图3、由于调用的停止Job服务是一个异步操作 , 并没有立即返回给我们savepoint路径 。 这时候需要调用 /jobs/:jobid/savepoints/:triggerid 获取savePoint路径
 文章插图
文章插图调用后结果返回了savepointPath
 文章插图
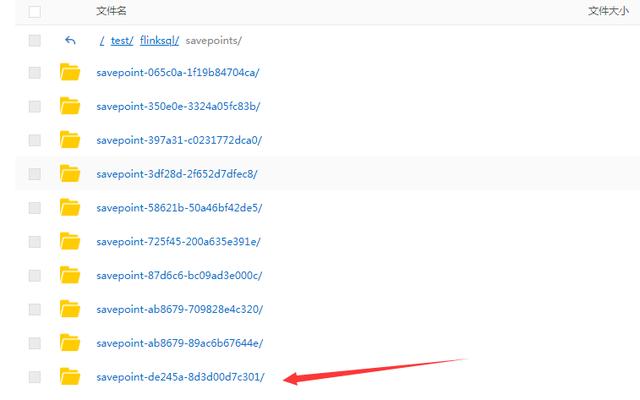
文章插图4、查看阿里云 OSS , savepoint保存成功
 文章插图
文章插图5、使用savepoint恢复Job , 通过REST API /jars/:jarid/run 接口恢复Job , savepointPath参数中上传刚才获取到的savePointPath
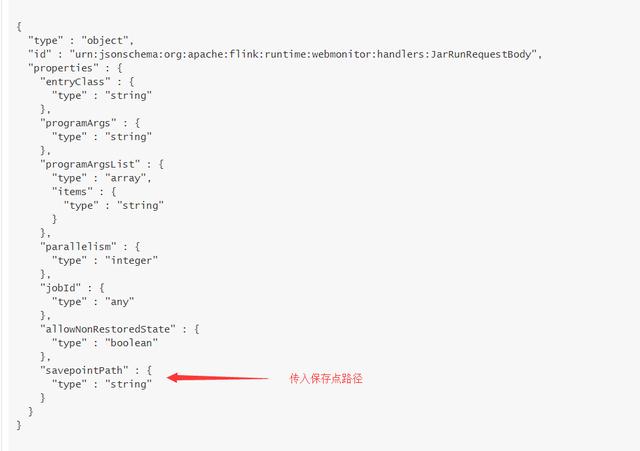 文章插图
文章插图 文章插图
文章插图Job 恢复成功
 文章插图
文章插图最后以上就是如何将Flink的savepoint保存到阿里云OSS上解决方案 , 大致为以下几部
- 移动 flink-oss-fs-hadoop-1.10.0.jar至lib 目录下
- 修改flink-conf.yaml的 state.savepoints.dir属性
- 在flink-conf.yaml中加入允许Flink访问OSS的属性
稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J30c92020.html
标题:如何将Flink的savepoint保存至阿里云OSS上