按关键词阅读:
编者按:过去十年 , 得益于人工智能与机器学习的突破、算法与硬/软件能力的进步 , 以及拥有既多样又大量的语音数据库 , 用以训练多参数的、大规模的语音识别与合成模型 , 使得语音处理技术获得飞跃性进展 。
随着端到端神经网络在机器翻译、语音生成等方面的进展 , 端到端的语音识别也达到了和传统方法可比的性能 。 不同于传统方法将语音识别任务分解为多个子任务(词汇模型 , 声学模型和语言模型) , 端到端的语音识别模型基于梅尔语谱作为输入 , 能够直接产生对应的自然语言文本 , 大大简化了模型的训练过程 , 从而越来越受到学术界和产业界的关注 。
本文将通过六篇论文 , 从建模方法、响应时间优化、数据增强等不同方面讲解端到端语音模型的发展 , 并探讨不同端到端语音识别模型的优缺点 。
端到端语音识别建模在讲述语音识别建模之前 , 首先明确端到端语音识别的输入和输出 。
【带你读论文 | 端到端语音识别模型】输入:目前端到端语音识别常用的输入特征为 fbank 。 fbank 特征的处理过程为对一段语音信号进行预加重、分帧、加窗、短时傅里叶变换(STFT)、mel 滤波、去均值等 。 一个 fbank 向量对应往往对应10ms的语音 , 而一段十秒的语音 , 即可得到大约1000个 fbank 的向量描述该语音 。 除了 fbank , MFCC 以及 raw waveform 在一些论文中也被当做输入特征 , 但主流的方法仍然采用 fbank 。
输出:端到端的输出可以是字母、子词(subword)、词等等 。 目前以子词当做输出比较流行 , 和 NLP 类似 , 一般用 sentence piece 等工具将文本进行切分 。
Seq2Seq
参考论文:Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition. ICASSP 2016(William Chan, Navdeep Jaitly, Quoc V. Le, Oriol Vinyals)
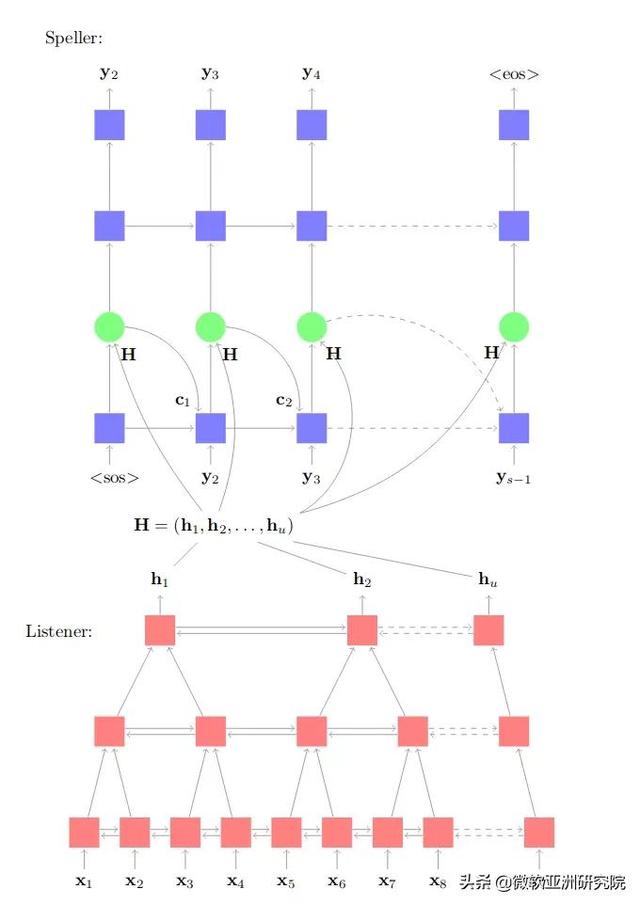
给定序列 X , 输出 Y , 最直白的一种办法就是延伸在机器翻译中所使用的 Seq2Seq 模型 。 Seq2Seq 模型由两部分组成:编码器和带有注意力机制的解码器 。 在解码每个词语的时候 , 注意力机制会动态计算每个输入隐状态的权重 , 并通过加权线性组合得到当前的注意力向量 。 在此处的语音识别任务中 , Seq2Seq 模型与机器翻译中的 Seq2Seq 模型异曲同工 , 可以使用不同的模型作为编码器和解码器 , 例如 RNN、Transformer 模型等 。
 文章插图
文章插图
图1:Listen, attend and spell 模型结构图
为了训练更好的 Seq2Seq 语音识别模型 , 一些优化策略也被提出:
- 引入增强学习策略 , 将最小词错率(minimum word error rate)当作模型训练的奖励函数 , 更新模型参数 。
- 由于语音的输入和输出有着单调性 , 并不存在机器翻译的调序问题 , 所以使用单调注意力策略 , 在一些实验中可以提升语音识别的性能 。
- 引入覆盖(coverage)机制 , 缓解语音识别的漏词问题 。
- 与 CTC 联合训练以及联合解码 , 可大幅提升 Seq2Seq 模型性能 。
参考论文:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. ICML 2006(AlexGraves, SantiagoFernández,FaustinoGomez)
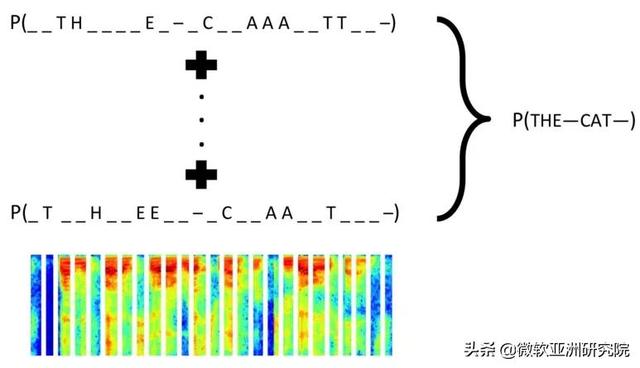
除了简单易懂的 Seq2Seq 模型之外 , 还需要关注另一个经典之作 CTC 模型 。 CTC 模型是端到端语音识别的开山始祖 , 提出时间远早于 Seq2Seq 模型 , 其建模思想也与 Seq2Seq 模型相去甚远 。 CTC 模型可以看作自动学习输入 X 与 Y 的对齐 , 由于 Y 的长度远小于 X , 所以 CTC 引入空和 y_i 的重复来让 X 和 \{y}_hat 一一对应 。
 文章插图
文章插图图2:CTC 输入音频与文本对应关系
例如 , 在图2中 , CTC 引入空和重复使得句子 THE CAT (Y)和输入音频(X)做对齐 。 这种对齐方式有三个特征:
(1)X 与 Y 映射是单调的 , 即如果 X 向前移动一个时间片 , Y 保持不动或者也向前移动一个时间片 。
(2)X 与 Y 的对齐是多对一的 。 一个 X 可以有很多种方式和 Y 进行对应 。
(3)X 的长度大于 Y 的长度 。
为了求得该映射 , 需要最大化后验概率 P(Y|X)
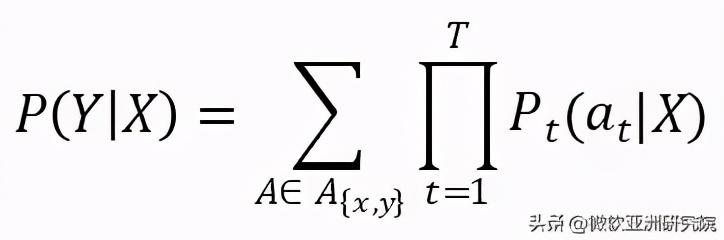 文章插图
文章插图这里 A 是一条合法的 x 和 y 的对应路径 , a_t 代表 t 时刻 X 所对应的输出 。 如有兴趣可参见了解更多的推导细节 。
在训练中 CTC 与 Seq2Seq 模型相比 , CTC 模型有如下不同:
- CTC 在解码时 , 对于每一帧都可以生成一个对应的子词 , 因此 CTC 比 Seq2Seq 可以更好地支持流式语音识别 。

稿源:(未知)
【傻大方】网址:http://www.shadafang.com/c/111J295602020.html
标题:带你读论文 | 端到端语音识别模型