基于GAN提高非平衡COVID-19死亡率预测模型准确性( 四 )
原始数据和生成数据之间的年龄比较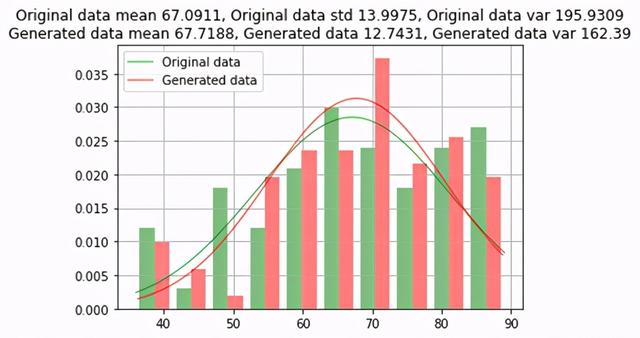 文章插图
文章插图
原始数据与生成的数据之间的比较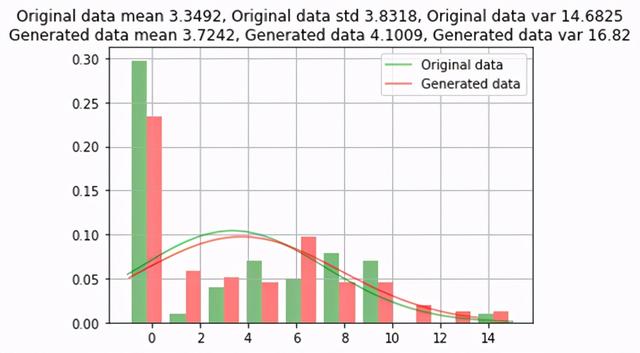 文章插图
文章插图
原始数据和生成的数据之间的类别比较
特征原始数据产生的数据 0101 location_Hokkaido612951 genderfemale49146036 symptom2 cough621960
GAN过采样方法生成的数据几乎类似于原始数据 , 原始数据的误差约为1% 。 对于一些稀有类别 , 不会在所有类别值上生成数据 。
遵循与原始研究中提到的相同的数据准备步骤 , 以查看通过使用GAN超采样与原始方法相比模型性能如何提高 。 所生成样本的独热编码数据被转换为原始数据帧格式 。
# Getting Back Categorical Data in Original_Format from Dummieslocation_filter_col = [col for col in mixed_gen_df if col.startswith('location')]location=mixed_gen_df[location_filter_col]location= pd.get_dummies(location).idxmax(1)location= location.replace('location_', '', regex=True)df_generated_data = http://kandian.youth.cn/index/pd.DataFrame()df_generated_data['location']=locationcountry_filter_col = [col for col in mixed_gen_df if col.startswith('country')]country=mixed_gen_df[country_filter_col]country= pd.get_dummies(country).idxmax(1)country= country.replace('country_', '', regex=True)df_generated_data['country']=countrygender_filter_col = [col for col in mixed_gen_df if col.startswith('gender')]gender=mixed_gen_df[gender_filter_col]gender= pd.get_dummies(gender).idxmax(1)gender= gender.replace('gender_', '', regex=True)df_generated_data['gender']=gendervis_wuhan_filter_col = [col for col in mixed_gen_df if col.startswith('vis_wuhan')]vis_wuhan=mixed_gen_df[vis_wuhan_filter_col]vis_wuhan= pd.get_dummies(vis_wuhan).idxmax(1)vis_wuhan= vis_wuhan.replace('vis_wuhan_', '', regex=True)df_generated_data['vis_wuhan']=vis_wuhanfrom_wuhan_filter_col = [col for col in mixed_gen_df if col.startswith('from_wuhan')]from_wuhan=mixed_gen_df[from_wuhan_filter_col]from_wuhan= pd.get_dummies(from_wuhan).idxmax(1)from_wuhan= from_wuhan.replace('from_wuhan_', '', regex=True)df_generated_data['from_wuhan']=from_wuhansymptom1_filter_col = [col for col in mixed_gen_df if col.startswith('symptom1')]symptom1=mixed_gen_df[symptom1_filter_col]symptom1= pd.get_dummies(symptom1).idxmax(1)symptom1= symptom1.replace('symptom1_', '', regex=True)df_generated_data['symptom1']=symptom1symptom2_filter_col = [col for col in mixed_gen_df if col.startswith('symptom2')]symptom2=mixed_gen_df[symptom2_filter_col]symptom2= pd.get_dummies(symptom2).idxmax(1)symptom2= symptom2.replace('symptom2_', '', regex=True)df_generated_data['symptom2']=symptom2symptom3_filter_col = [col for col in mixed_gen_df if col.startswith('symptom3')]symptom3=mixed_gen_df[symptom3_filter_col]symptom3= pd.get_dummies(symptom3).idxmax(1)symptom3= symptom3.replace('symptom3_', '', regex=True)df_generated_data['symptom3']=symptom3symptom4_filter_col = [col for col in mixed_gen_df if col.startswith('symptom4')]symptom4=mixed_gen_df[symptom4_filter_col]symptom4= pd.get_dummies(symptom4).idxmax(1)symptom4= symptom4.replace('symptom4_', '', regex=True)df_generated_data['symptom4']=symptom4symptom5_filter_col = [col for col in mixed_gen_df if col.startswith('symptom5')]symptom5=mixed_gen_df[symptom5_filter_col]symptom5= pd.get_dummies(symptom5).idxmax(1)symptom5= symptom5.replace('symptom5_', '', regex=True)df_generated_data['symptom5']=symptom5symptom6_filter_col = [col for col in mixed_gen_df if col.startswith('symptom6')]symptom6=mixed_gen_df[symptom6_filter_col]symptom6= pd.get_dummies(symptom6).idxmax(1)symptom6= symptom6.replace('symptom6_', '', regex=True)df_generated_data['symptom6']=symptom6df_generated_data['death']=1df_generated_data['death']=1df_generated_data[['age','diff_sym_hos']]=mixed_gen_df[['age','diff_sym_hos']]df_generated_data = http://kandian.youth.cn/index/df_generated_data.fillna(np.nan,axis=0)#Encoding Dataencoder_location = preprocessing.LabelEncoder()encoder_country = preprocessing.LabelEncoder()encoder_gender = preprocessing.LabelEncoder()encoder_symptom1 = preprocessing.LabelEncoder()encoder_symptom2 = preprocessing.LabelEncoder()encoder_symptom3 = preprocessing.LabelEncoder()encoder_symptom4 = preprocessing.LabelEncoder()encoder_symptom5 = preprocessing.LabelEncoder()encoder_symptom6 = preprocessing.LabelEncoder()# Loading and Preparing Datadf = pd.read_csv('Covid_Train_Oct32020.csv')df = df.drop('id',axis=1)df = df.fillna(np.nan,axis=0)df['age'] = df['age'].fillna(value=http://kandian.youth.cn/index/tdata['age'].mean())df['sym_on'] = pd.to_datetime(df['sym_on'])df['hosp_vis'] = pd.to_datetime(df['hosp_vis'])df['sym_on']= df['sym_on'].map(dt.datetime.toordinal)df['hosp_vis']= df['hosp_vis'].map(dt.datetime.toordinal)df['diff_sym_hos']= df['hosp_vis'] - df['sym_on']df = df.drop(['sym_on','hosp_vis'],axis=1)df['location'] = encoder_location.fit_transform(df['location'].astype(str))df['country'] = encoder_country.fit_transform(df['country'].astype(str))df['gender'] = encoder_gender.fit_transform(df['gender'].astype(str))df[['symptom1']] = encoder_symptom1.fit_transform(df['symptom1'].astype(str))df[['symptom2']] = encoder_symptom2.fit_transform(df['symptom2'].astype(str))df[['symptom3']] = encoder_symptom3.fit_transform(df['symptom3'].astype(str))df[['symptom4']] = encoder_symptom4.fit_transform(df['symptom4'].astype(str))df[['symptom5']] = encoder_symptom5.fit_transform(df['symptom5'].astype(str))df[['symptom6']] = encoder_symptom6.fit_transform(df['symptom6'].astype(str))# Encoding Generated Datadf_generated_data['location'] = encoder_location.transform(df_generated_data['location'].astype(str))df_generated_data['country'] = encoder_country.transform(df_generated_data['country'].astype(str))df_generated_data['gender'] = encoder_gender.transform(df_generated_data['gender'].astype(str))df_generated_data[['symptom1']] = encoder_symptom1.transform(df_generated_data['symptom1'].astype(str))df_generated_data[['symptom2']] = encoder_symptom2.transform(df_generated_data['symptom2'].astype(str))df_generated_data[['symptom3']] = encoder_symptom3.transform(df_generated_data['symptom3'].astype(str))df_generated_data[['symptom4']] = encoder_symptom4.transform(df_generated_data['symptom4'].astype(str))df_generated_data[['symptom5']] = encoder_symptom5.transform(df_generated_data['symptom5'].astype(str))df_generated_data[['symptom6']] = encoder_symptom6.transform(df_generated_data['symptom6'].astype(str))df_generated_data[['diff_sym_hos']] = df_generated_data['diff_sym_hos'].astype(int)
- 同级别|卢伟冰再提高像素“方向错了”,红米Note9Pro证明给赵明看
- 传播|马静华:5G与区块链是提高影响力最好的工具
- 复习|期末整理复习笔记?MHMO魅蒙iPad专用笔助提高效率
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- 如何基于Python实现自动化控制鼠标和键盘操作
- 特斯拉 Model 3上市,外观小改,性能提高,续航里程更长
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 蓝鲸专访|水滴CTO邱慧:基于业务场景做技术创新,用户需求可分析并唤醒
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- Python编程:一个基于PyQt的Led控件库,建议收藏