基于GAN提高非平衡COVID-19死亡率预测模型准确性
介绍本文介绍了生成性对抗网络(Generative attersarial Networks , GAN)的使用 , 这是一种对真实的Covid-19数据进行过采样的技术 , 用于预测死亡率 。 这个故事让我们更好地理解数据准备步骤(如处理不平衡的数据)如何提高模型性能 。
本文的数据和核心模型来自Celestine Iwendi、Ali Kashif Bashir、Atharva Peshkar最近的一项研究(2020年7月)“使用增强随机森林算法预测COVID-19患者健康” 。 本研究使用ADABOST模型增强的随机森林算法预测个体患者的死亡率 , 准确率为94% 。 本文考虑相同的模型和模型参数 , 明确分析了采用基于GAN的过采样技术对现有模型的改进 。
对于有抱负的数据科学家来说 , 学习良好实践的最好方法之一就是参加不同论坛上的黑客竞赛 , 比如Vidhya、Kaggle或其他论坛 。
此外 , 从这些论坛或出版的研究出版物中获取已解决的案例和数据;了解他们的方法 , 并尝试通过额外的步骤来提高准确性或减少误差 。 这将形成一个坚实的基础 , 使我们能够深入思考我们在数据科学价值链中所学的其他技术的应用 。
研究中使用的数据是用222个病人的13个特征来训练的 。 数据有偏差 , 159例(72%)属于“0”类或“已恢复”类 。 由于其偏差性质 , 各种欠采样/过采样技术可应用于数据 。 偏态数据的问题会导致预测模型的过度拟合 。
为了克服这一局限性 , 许多研究采用过采样方法来平衡数据集 , 从而得到更精确的模型训练 。 过采样是一种通过增加少数数据中的样本数量来补偿数据集不平衡的技术 。
常规方法包括随机过采样(ROS)、合成少数过采样技术(SMOTE)等 。
最近 , 一种基于对抗性学习概念的生成性网络的机器学习模型被提出 , 即生成性对抗性网络 。 生成性对抗网络(Generative atterial Networks , GAN)的特点使其较易应用于过采样研究 , 因为基于对抗训练的神经网络的性质允许生成与原始数据相似的人工数据 。 基于生成性对抗网络的过采样克服了传统方法(如过拟合)的局限性 , 允许建立一个高精度的不平衡数据预测模型 。
如何生成合成数据?两个神经网络相互竞争 , 学习目标分布并生成人工数据
发生器网络G:模拟训练样本欺骗鉴别器
判别网络D:判别训练样本和生成样本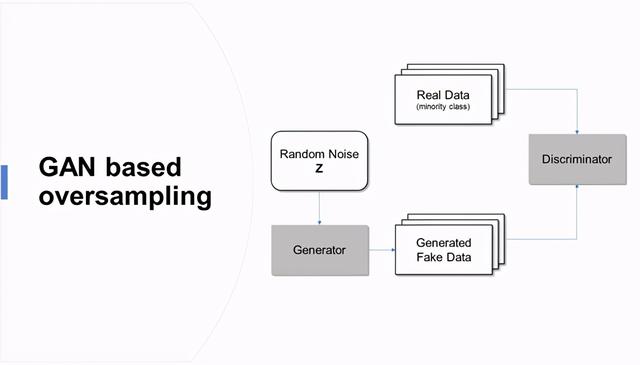 文章插图
文章插图
生成性对抗性网络是基于博弈论的场景 , 其中生成网络必须与对手竞争 。 随着GAN学会模拟数据的分布 , 它被应用于各个领域 , 如音乐、视频和自然语言 , 最近还用于处理不平衡的数据问题 。
研究中使用的数据和基本模型可以在这里找到
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport tensorflow as tffrom keras.layers import Input, Dense, Reshape, Flatten, Dropout, BatchNormalization, Embeddingfrom keras.layers.advanced_activations import LeakyReLUfrom keras.layers.merge import concatenatefrom keras.models import Sequential, Modelfrom keras.optimizers import Adamfrom keras.utils import to_categoricalfrom keras.layers.advanced_activations import LeakyReLUfrom keras.utils.vis_utils import plot_modelfrom sklearn.preprocessing import MinMaxScaler, OneHotEncoder, LabelEncoderimport scipy.statsimport datetime as dtimport pydotimport warningswarnings.filterwarnings("ignore")%matplotlib inlinedf = pd.read_csv('Covid_Train_Oct32020.csv')df = df.drop('id',axis=1)df = df.fillna(np.nan,axis=0)df['age'] = df['age'].fillna(value=http://kandian.youth.cn/index/df['age'].mean())df['sym_on'] = pd.to_datetime(df['sym_on'])df['hosp_vis'] = pd.to_datetime(df['hosp_vis'])df['sym_on']= df['sym_on'].map(dt.datetime.toordinal)df['hosp_vis']= df['hosp_vis'].map(dt.datetime.toordinal)df['diff_sym_hos']= df['hosp_vis'] - df['sym_on']df=df.drop(['sym_on', 'hosp_vis'], axis=1)df['location'] = df['location'].astype(str)df['country'] = df['country'].astype(str)df['gender'] = df['gender'].astype(str)df['vis_wuhan'] = df['vis_wuhan'].astype(str)df['from_wuhan'] = df['from_wuhan'].astype(str)df['symptom1'] = df['symptom1'].astype(str)df['symptom2'] = df['symptom2'].astype(str)df['symptom3'] = df['symptom3'].astype(str)df['symptom4'] = df['symptom4'].astype(str)df['symptom5'] = df['symptom5'].astype(str)df['symptom6'] = df['symptom6'].astype(str)df.dtypes数据说明列 描述 值(用于分类变量) 类型 id患者编号不适用数字 location患者所属的位置遍布全球的多个城市字符串 , 分类 country患者的国家多个国家字符串 , 分类 gender患者性别男 , 女字符串 , 分类 age患者年龄不适用数字 sym_on患者开始注意到症状的日期不适用日期 hosp_vis病人去医院的日期不适用日期 vis_wuhan患者是否去过中国武汉是(1) , 否(0)数值 , 分类 from_wuhan患者是否属于中国武汉是(1) , 否(0)数值 , 分类 death患者是否因COVID-19而去世是(1) , 否(0)数值 , 分类 Recov患者是否康复是(1) , 否(0)数值 , 分类 symptom1. symptom2, symptom3, symptom4, symptom5, symptom6患者注意到的症状患者注意到多种症状字符串 , 分类
- 同级别|卢伟冰再提高像素“方向错了”,红米Note9Pro证明给赵明看
- 传播|马静华:5G与区块链是提高影响力最好的工具
- 复习|期末整理复习笔记?MHMO魅蒙iPad专用笔助提高效率
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- 如何基于Python实现自动化控制鼠标和键盘操作
- 特斯拉 Model 3上市,外观小改,性能提高,续航里程更长
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 蓝鲸专访|水滴CTO邱慧:基于业务场景做技术创新,用户需求可分析并唤醒
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- Python编程:一个基于PyQt的Led控件库,建议收藏