Python 从业十年是种什么体验?老程序员的一篇万字经验分享( 二 )
GIL 在一个进程内 , 解释器仅能同时解释执行一条语句 , 这为 py 提供了天然的语句级线程安全 , 从很多意义上说 , 这都极大的简化了并行编程的难度 。 对于 I/O 型应用 , 多线程并不会受到多大影响 。 对于 CPU 型应用 , 编写一个基于 Queue 的多进程 worker 其实也就是几行的事 。
(订正:应为伪指令级的线程安全)
from time import sleepfrom concurrent.futures import ProcessPoolExecutor, waitfrom multiprocessing import Manager, QueueN_PARALLEL = 5def worker(i: int, q: Queue) -> None:print(f'worker {i} start')while 1:data = http://kandian.youth.cn/index/q.getif data is None: # 采用毒丸(poison pill)方式来结束进程池q.put(data)print(f'worker {i} exit')returnprint(f'dealing with data {data}...')sleep(1)def main:executor = ProcessPoolExecutor(max_workers=N_PARALLEL) # 控制并发量with Manager as manager:queue = manager.Queue(maxsize=50) # 控制缓存量workers = [executor.submit(worker, i, queue) for i in range(N_PARALLEL)]for i in range(50):queue.put(i)print('all task data submitted')queue.put(None)wait(workers)print('all done')main我经常给新人讲 , 是否能谨慎的对待并行编程 , 是一个区分初级和资深后端开发的分水岭 。 业界有一句老话:“没有正确的并行程序 , 只有不够量的并行度” , 由此可见并行开发的复杂程度 。
我个人认为思考并行时主要是在考虑两个问题:同步控制和资源用量 。
对于同步控制 , 你在 thread, multiprocessing, asyncio 几个包里都会发现一系列的工具:
- Lock 互斥锁
- RLock 可重入锁
- Queue 队列
- Condition 条件锁
- Event 事件锁
- Semaphore 信号量
对于资源控制 , 一般来说主要就是两个地方:
- 缓存区有多大(Queue 长度)
- 并发量有多大(workers 数量)
既然提到了 workers , 稍微简单展开一下“池”这个概念 。 我们经常提到线程池、进程池、连接池 。 说白了就是对于一些可重用的资源 , 不必每次都创建新的 , 而是使用完毕后回收留待下一个数据继续使用 。 比如你可以选择不断地开子线程 , 也可以选择预先开好一批线程 , 然后通过 queue 来不断的获取和处理数据 。
所以说使用“池”的主要目的就是减少资源的消耗 。 另一个优点是 , 使用池可以非常方便的控制并发度(很多新人以为 Queue 是用来控制并发度的 , 这是错误的 , Queue 控制的是缓存量) 。
对于连接池 , 还有另一层好处 , 那就是端口资源是有限的 , 而且回收端口的速度很慢 , 你不断的创建连接会导致端口迅速耗尽 。
这里做一个用语的订正 。 Queue 控制的应该是缓冲量(buffer) , 而不是缓存量(cache) 。 一般来说 , 我们习惯上将写入队列称为缓冲 , 将读取队列称为缓存(有源) 。
对前面介绍的 python 中进程/线程做一个小结 , 线程池可以用来解决 I/O 的阻塞 , 而进程可以用来解决 GIL 对 CPU 的限制(因为每一个进程内都有一个 GIL) 。 所以你可以开 N 个(小于等于核数)进程池 , 然后在每一个进程中启动一个线程池 , 所有的线程池都可以订阅同一个 Queue , 来实现真正的多核并行 。
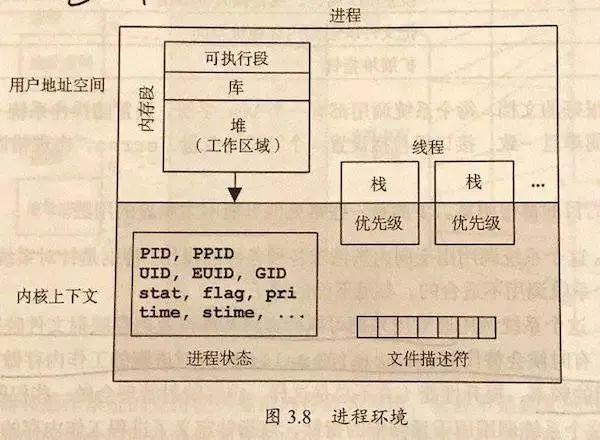
非常简单的描述一下进程/线程 , 对于操作系统而言 , 可以认为进程是资源的最小单位(在 PCB 内保存如图 1 的数据) 。 而线程是调度的最小单位 。 同一个进程内的线程共享除栈和寄存器外的所有数据 。
所以在开发时候 , 要小心进程内多线程数据的冲突 , 也要注意多进程数据间的隔离(需要特别使用进程间通信)
 文章插图
文章插图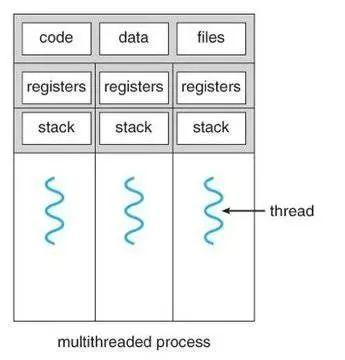 文章插图
文章插图- 操作系统笔记:进程()
- 操作系统笔记:调度()
顺带一提 , 因为 CPython 的 refcnt 机制 , 所以 COW(copy on write)并不可靠 。
人们在见到别人的“错误写法”时 , 倾向于无视或吐槽讽刺 。 但是这个行为除了让自己爽一下外没有任何意义 , 不懂的还是不懂 , 最后真正发挥影响的还是那些能够描绘一整条学习路径的方法 。
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 爱奇艺|连续亏损十年,爱奇艺收入不及快手,视频网站的出口在哪里?
- 直播从业者|高三老师监考时开直播,面对质疑还振振有词,怕困没有打扰学生
- 付费|谁在定义未来三十年?音频内容付费,60后人数同比增154%,00后增94%
- 悬空|华为Mate悲壮史十年逆袭,三轮打压,一朝悬空
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题