两大挑战!是什么阻碍了图形数据库的扩展?
全文共2808字 , 预计学习时长8分钟 文章插图
文章插图
图源:unsplash
生活中的许多地方都在运用着数据库技术 , 例如诈骗检测、知识图谱、资产管理、推荐浏览器、物联网、权限管理等等 。 数据库技术能够快速分析相关度高的数据点以及其之间的联系 , 图形数据库便是其中之一 。
但由于图形数据本身性质特殊 , 其在架构方面还面临诸多挑战 。 那么 , 图形数据库是否能够扩展呢?本文将全面分析可能阻碍图形数据库扩展的两个挑战 , 并讨论当前可用的解决方案 。 文章插图
文章插图
什么是"图形数据库的可扩展性"?“扩展” , 不只是指将更多的数据存入一台计算机或随便存进多台计算机 。 对于大型数据集或不断增长的数据集 , 良好的查询性能十分必要 。
所以 , 其中真正的问题在于 , 当单台计算机上的数据集增长到会影响其他功能时 , 图形数据库的表现能否令人满意呢?如果你还不能理解为什么这是首要问题 , 请和我一起快速回顾以下图形数据库 。
简单来说 , 图形数据库用于存储无架构对象(顶点或节点)以及任意数据(属性)和对象(边缘)的关联数据 。 边通常能够指出对象之间的着力点 , 顶点和边共同构成图形网络数据集 。
离散数学将图形定义为一组顶点和边;而计算机科学则将其定义为一种抽象的数据类型 , 它能够表示连接或关系 。 它不同于关系数据库系统中的表格数据结构 , 后者表达数据关系的能力十分有限 。
如上所述 , 图形由节点(又名顶点[V]) 组成 , 这些节点由关系(即边[E])连接 。 文章插图
文章插图
顶点具有任意数量的边和任意深度(路径的长度)的窗体路径 。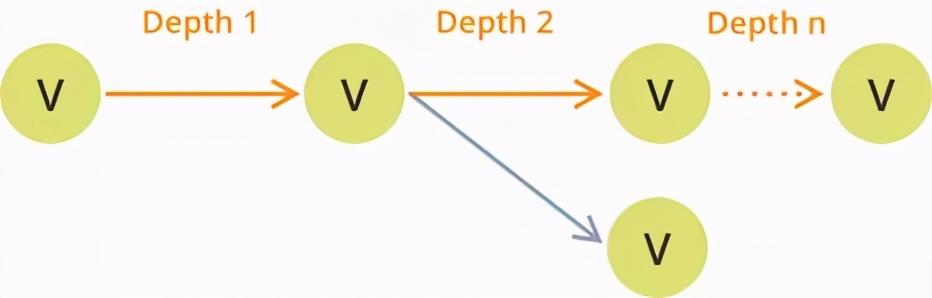 文章插图
文章插图
它也可以针对跨行金融交易进行图形建模 , 如下图所示 。 此例中 , 我们可以将银行帐户定义为节点 , 银行交易记录与其他关系定义为边缘 。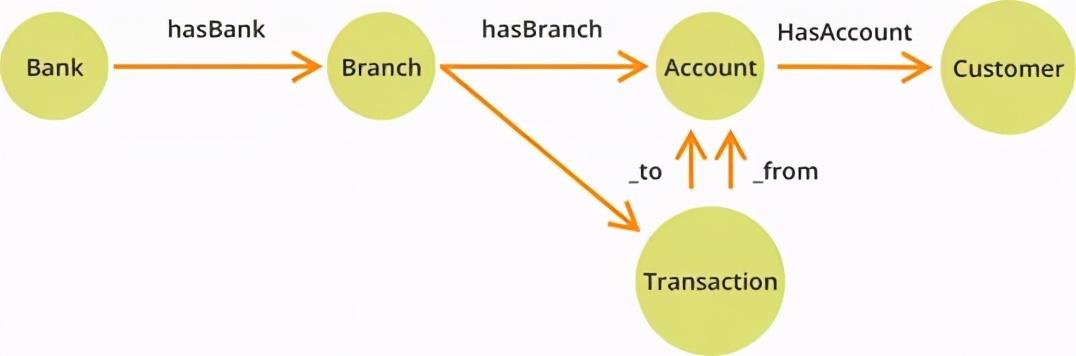 文章插图
文章插图
以这种方式存储帐户和交易信息 , 以遍历创建图形未知或变化的数据深度 。 在关系数据库中编写和运行此类查询功能往往是一项复杂的工作(使用多模型数据库能够以银行与其分支机构之间的关系来建模) 。
图形数据库提供各种算法 , 以便用户查询所存储的数据及分析其间关系 。 包括遍历、模式匹配、最短路径或分布式图形处理 , 如分析社区侦测、连接组件或中心性 。 大多数算法都有一个共同点 , 这也是解决超节点和网络跃点问题的本质——算法通过边从一个节点遍历到另一个节点 。
快速回顾之后 , 挑战就要开始啦!文章插图
“名人效应”上文已提到顶点或节点可以具有任意数量的边 。 超级点的一个经典例子便是网红——超节点是图形数据集中传入或传出边条数过多的节点 。 帕特里克·斯图尔特爵士的Twitter账户目前就拥有340多万粉丝 。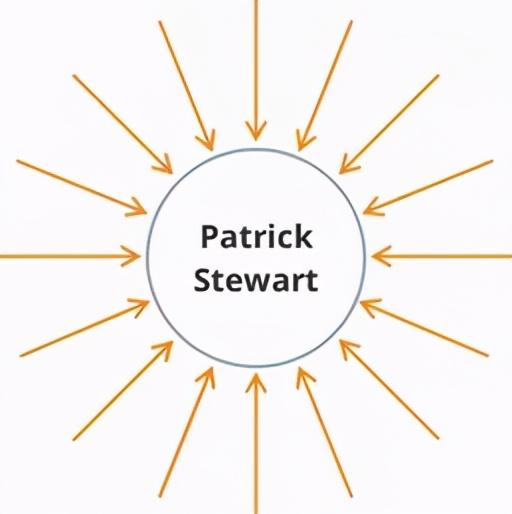 文章插图
文章插图
如果现在将帐户和推文数据进行图形建模 , 遍历其数据即Patrick Stewart的帐户信息 , 那么算法必须定向分析Steward帐户所有的340万条边 。 这就会延长查询执行时间 , 甚至可能突破被授权的权限 。 类似的问题存在于欺诈检测(帐户进行大量交易、网络管理-大型 IP hub)等案例中 。
超级节点是图形的固有问题 , 也是所有图形数据库面临的问题 , 以下两种方法能尽量减少超节点的影响 。 文章插图
文章插图
图源:unsplash
· 方法一:拆分超节点
更准确来说 , 可以复制节点"Patrick Stewart" , 并按某个属性(如粉丝的国家/地区或其他特定分组)拆分数据边缘 。 这样就会将超节点遍历数据对性能的影响降至最低 , 以便查询分类时所用 。
【两大挑战!是什么阻碍了图形数据库的扩展?】· 方法二:中心节点索引
以顶点为中心的索引同时存储边缘信息和有关节点的信息 。 还是以帕特里克·斯图尔特的 Twitter 帐户为例 , 可以这样分组:粉丝的起始关注日期/时间信息、粉丝的国家/地区、粉丝的粉丝数等等 , 以上所有属性都可以为更高效地使用()提供选择性 。
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 小店|抖音小店无货源是什么?与传统模式有什么区别?
- 计算机学科|机器视觉系统是什么
- 截图|笔记本截图快捷键是什么
- 挑战|“趋势与挑战”2020全球蓝靛果产业发展大会召开
- 字化转型|疫情重构经济,传统企业「数字化」的通关密码是什么?
- 一流|妥妥的一流旗舰配置,vivo X系列新机已手握两大“杀器”
- 屏幕|太让人气愤了!关于iPhone12出现的“两大问题”,苹果表明态度!
- 有道词典笔3正式上市:推出超快点查、互动点读两大创新功能
- 济南|"十四五"济南工业强市主攻这个方向!两大产业集群规模皆达7000亿级