支持百万级TPS,Kafka是怎么做到的?( 二 )
Memory Mapped Files(MMAP)在文章开头我们看到硬盘的顺序读写基本能与内存随机读写速度媲美 , 但是与内存顺序读写相比还是太慢了 , 那 Kafka 如果有追求想进一步提升效率怎么办?可以使用现代操作系统分页存储来充分利用内存提高I/O效率 , 这也是下面要介绍的 MMAP 技术 。
MMAP也就是内存映射文件 , 在64位操作系统中一般可以表示 20G 的数据文件 , 它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射 , 完成映射之后对物理内存的操作会被同步到硬盘上 。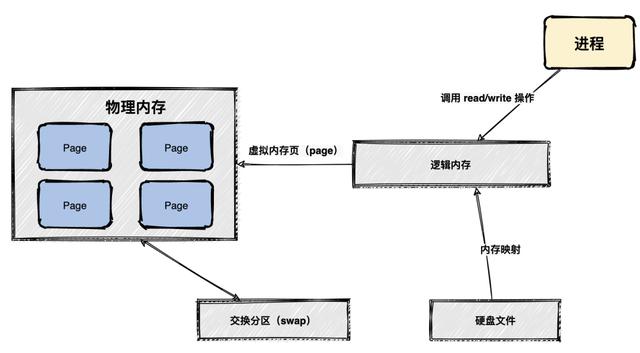 文章插图
文章插图
通过MMAP技术进程可以像读写硬盘一样读写内存(逻辑内存) , 不必关心内存的大小 , 因为有虚拟内存兜底 。 这种方式可以获取很大的I/O提升 , 省去了用户空间到内核空间复制的开销 。
也有一个很明显的缺陷 , 写到MMAP中的数据并没有被真正的写到硬盘 , 操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘 。
Kafka提供了一个参数:producer.type 来控制是不是主动 flush , 如果Kafka写入到MMAP之后就立即flush然后再返回Producer叫同步(sync);写入MMAP之后立即返回Producer不调用flush叫异步(async) 。 文章插图
文章插图
Zero Copy(零拷贝)Kafka 另外一个黑技术就是使用了零拷贝 , 要想深刻理解零拷贝必须得知道什么是DMA 。
什么是DMA?
众所周知 CPU 的速度与磁盘 IO 的速度比起来相差几个数量级 , 可以用乌龟和火箭做比喻 。
一般来说 IO 操作都是由 CPU 发出指令 , 然后等待 IO 设备完成操作后返回 , 那CPU会有大量的时间都在等待IO操作 。
但是CPU 的等待在很多时候并没有太多的实际意义 , 我们对于 I/O 设备的大量操作其实都只是把内存里面的数据传输到 I/O 设备而已 。 比如进行大文件复制 , 如果所有数据都要经过 CPU , 实在是有点儿太浪费时间了 。
基于此就有了DMA技术 , 翻译过来也就是直接内存访问(Direct Memory Access) , 有了这个可以减少 CPU 的等待时间 。
Kafka 零拷贝原理
如果不使用零拷贝技术 , 消费者(consumer)从Kafka消费数据 , Kafka从磁盘读数据然后发送到网络上去 , 数据一共发生了四次传输的过程 。 其中两次是 DMA 的传输 , 另外两次 , 则是通过 CPU 控制的传输 。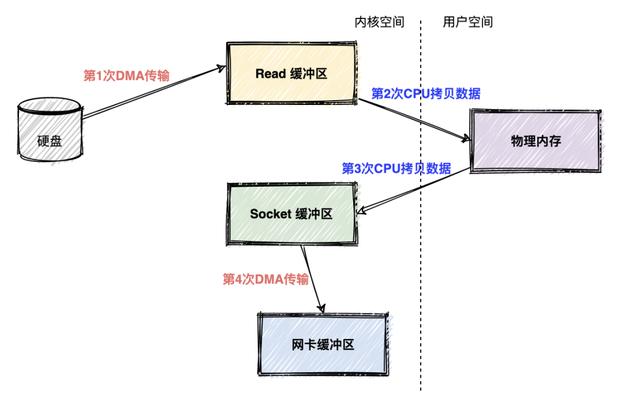 文章插图
文章插图
第一次传输:从硬盘上将数据读到操作系统内核的缓冲区里 , 这个传输是通过 DMA 搬运的 。
第二次传输:从内核缓冲区里面的数据复制到分配的内存里面 , 这个传输是通过 CPU 搬运的 。
第三次传输:从分配的内存里面再写到操作系统的 Socket 的缓冲区里面去 , 这个传输是由 CPU 搬运的 。
第四次传输:从 Socket 的缓冲区里面写到网卡的缓冲区里面去 , 这个传输是通过 DMA 搬运的 。
实际上在kafka中只进行了两次数据传输 , 如下图: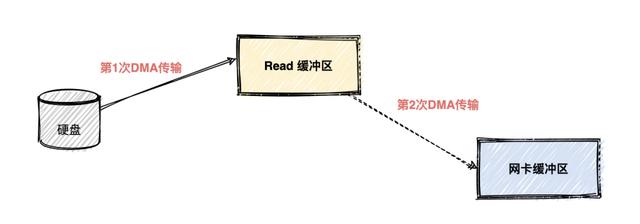 文章插图
文章插图
第一次传输:通过 DMA从硬盘直接读到操作系统内核的读缓冲区里面 。
第二次传输:根据 Socket 的描述符信息直接从读缓冲区里面写入到网卡的缓冲区里面 。
我们可以看到同一份数据的传输次数从四次变成了两次 , 并且没有通过 CPU 来进行数据搬运 , 所有的数据都是通过 DMA 来进行传输的 。 没有在内存层面去复制(Copy)数据 , 这个方法称之为零拷贝(Zero-Copy) 。
无论传输数据量的大小 , 传输同样的数据使用了零拷贝能够缩短 65% 的时间 , 大幅度提升了机器传输数据的吞吐量 , 这也是Kafka能够支持百万TPS的一个重要原因 。 文章插图
文章插图
Batch Data(数据批量处理)当消费者(consumer)需要消费数据时 , 首先想到的是消费者需要一条 , kafka发送一条 , 消费者再要一条kafka再发送一条 。 但实际上 Kafka 不是这样做的 , Kafka 耍小聪明了 。
Kafka 把所有的消息都存放在一个一个的文件中 , 当消费者需要数据的时候 Kafka 直接把文件发送给消费者 。 比如说100万条消息放在一个文件中可能是10M的数据量 , 如果消费者和Kafka之间网络良好 , 10MB大概1秒就能发送完 , 既100万TPS , Kafka每秒处理了10万条消息 。
看到这里你可以有疑问了 , 消费者只需要一条消息啊 , kafka把整个文件都发送过来了 , 文件里面剩余的消息怎么办?不要忘了消费者可以通过offset记录消费进度 。
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 光晕|PS插件:Oniric Glow Generator (光晕效果)支持ps 2021
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 无国界|嘴上说着支持华为,却为苹果贡献了2000亿!还真是科技无国界啊?
- 启动|饿了么宣布启动“1212超级粉丝狂欢节”联合34家品牌推吃货卡季卡
- 化妆产品|直播带货年入百万,这8个行业告诉你:是真的
- 拍照|iPhone12还没捂热13就曝光了,屏幕、信号、拍照均有升级!
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 名单|河南8个项目入选国家级示范名单