支持百万级TPS,Kafka是怎么做到的?
 文章插图
文章插图
作者 | 雷架
来源 | 爱笑的架构师
谈到大数据传输都会想到 Kafka , Kafka 号称大数据的杀手锏 , 在业界有很多成熟的应用场景并且被主流公司认可 。 这款为大数据而生的消息中间件 , 以其百万级TPS的吞吐量名声大噪 , 迅速成为大数据领域的宠儿 , 在数据采集、传输、存储的过程中发挥着举足轻重的作用 。
在业界已经有很多成熟的消息中间件如:RabbitMQ, RocketMQ, ActiveMQ, ZeroMQ , 为什么 Kafka 在众多的敌手中依然能有一席之地 , 当然靠的是其强悍的吞吐量 。 文章插图
文章插图
Kafka 如何做到支持百万级 TPS ?先用一张思维导图直接告诉你答案: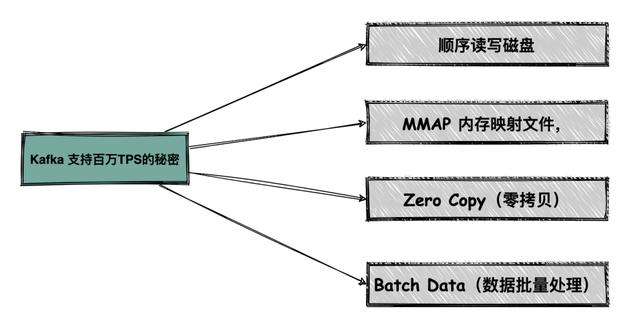 文章插图
文章插图 文章插图
文章插图
顺序读写磁盘生产者写入数据和消费者读取数据都是顺序读写的 , 先来一张图直观感受一下顺序读写和随机读写的速度: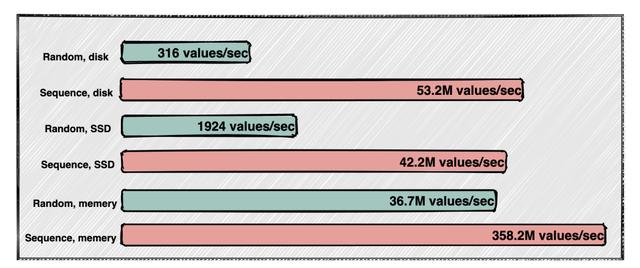 文章插图
文章插图
从图中可以看出传统硬盘或者SSD的顺序读写甚至超过了内存的随机读写 , 当然与内存的顺序读写对比差距还是很大 。
所以Kafka选择顺序读写磁盘也不足为奇了 。
下面以传统机械磁盘为例详细介绍一下什么是顺序读写和随机读写 。
盘片和盘面:一块硬盘一般有多块盘片 , 盘片分为上下两面 , 其中有效面称为盘面 , 一般上下都有效 , 也就是说:盘面数 = 盘片数 * 2 。
【支持百万级TPS,Kafka是怎么做到的?】磁头:磁头切换磁道读写数据时是通过机械设备实现的 , 一般速度较慢;而磁头切换盘面读写数据是通过电子设备实现的 , 一般速度较快 , 因此磁头一般是先读写完柱面后才开始寻道的(不用切换磁道) , 这样磁盘读写效率更快 。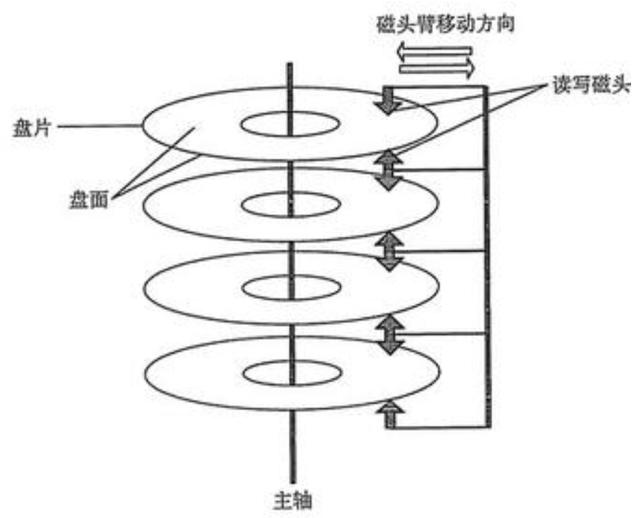 文章插图
文章插图
磁道:磁道就是以中间轴为圆心的圆环 , 一个盘面有多个磁道 , 磁道之间有间隙 , 磁道也就是磁盘存储数据的介质 。 磁道上布有一层磁介质 , 通过磁头可以使磁介质的极性转换为数据信号 , 即磁盘的读 , 磁盘写刚好与之相反 。
柱面:磁盘中不同盘面中半径相同的磁道组成的 , 也就是说柱面总数 = 某个盘面的磁道数 。
扇区:单个磁道就是多个弧形扇区组成的 , 盘面上的每个磁道拥有的扇区数量是相等 。 扇区是最小存储单元 , 一般扇区大小为512bytes 。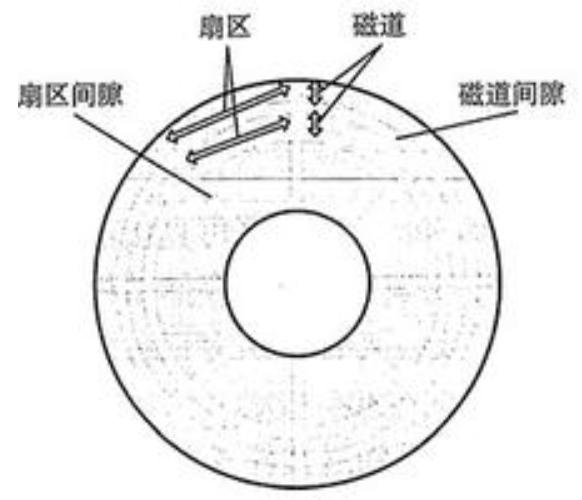 文章插图
文章插图
如果系统每次只读取一个扇区 , 那恐怕效率太低了 , 所以出现了block(块)的概念 。 文件读取的最小单位是block , 根据不同操作系统一个block一般由多个扇区组成 。
有了磁盘的背景知识我们就可以很容易理解顺序读写和随机读写了 。
插播维基百科定义:
顺序读写:是一种按记录的逻辑顺序进行读、写操作的存取方法, 即按照信息在存储器中的实际位置所决定的顺序使用信息 。
随机读写:指的是当存储器中的消息被读取或写入时 , 所需要的时间与这段信息所在的位置无关 。
当读取第一个block时 , 要经历寻道、旋转延迟、传输三个步骤才能读取完这个block的数据 。 而对于下一个block , 如果它在磁盘的其他任意位置 , 访问它会同样经历寻道、旋转、延时、传输才能读取完这个block的数据 , 我们把这种方式叫做随机读写 。 但是如果这个block的起始扇区刚好在刚才访问的block的后面 , 磁头就能立刻遇到 , 不需等待直接传输 , 这种就叫顺序读写 。
好 , 我们再回到 Kafka , 详细介绍Kafka如何实现顺序读写入数据 。
Kafka 写入数据是顺序的 , 下面每一个Partition 都可以当做一个文件 , 每次接收到新数据后Kafka会把数据插入到文件末尾 , 虚框部分代表文件尾 。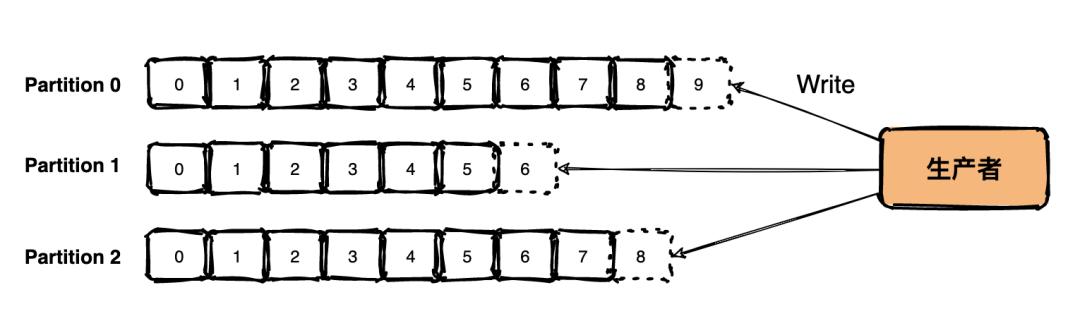 文章插图
文章插图
这种方法有一个问题就是删除数据不方便 , 所以 Kafka 一般会把所有的数据都保留下来 , 每个消费者(Consumer)对每个Topic都有一个 offset 用来记录读取进度或者叫坐标 。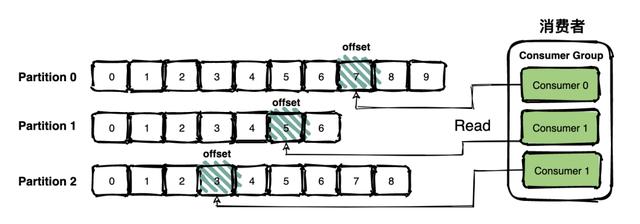 文章插图
文章插图 文章插图
文章插图
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 光晕|PS插件:Oniric Glow Generator (光晕效果)支持ps 2021
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 无国界|嘴上说着支持华为,却为苹果贡献了2000亿!还真是科技无国界啊?
- 启动|饿了么宣布启动“1212超级粉丝狂欢节”联合34家品牌推吃货卡季卡
- 化妆产品|直播带货年入百万,这8个行业告诉你:是真的
- 拍照|iPhone12还没捂热13就曝光了,屏幕、信号、拍照均有升级!
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 名单|河南8个项目入选国家级示范名单