面试常考,项目易错!C/C++中的字节对齐
 文章插图
文章插图
作者 | 李肖遥
来源 | 技术让梦想更伟大(ID:TechDreamer)
头图 | CSDN 下载自东方IC
引入主题,看代码我们先来看看以下程序
//编译器://来源:技术让梦想更伟大//作者:李肖遥#include using namespace std;struct st1 { char a ; int b ; short c ;};struct st2{ short c ; char a ; int b ;};int main{ cout<<"sizeof(st1) -> "< cout<<"sizeof(st2) -> "< return 0 ;}编译的结果如下: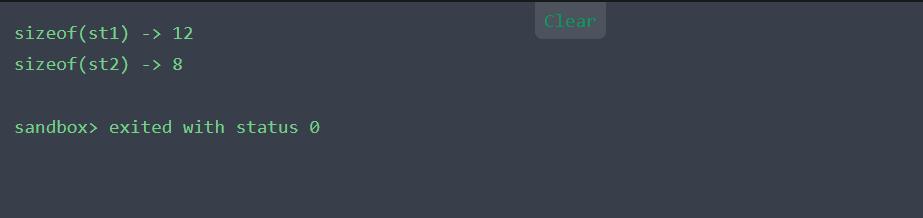 文章插图
文章插图
问题来了 , 两个结构体的内容一样 , 只是换了个位置 , 为什么 sizeof(st) 的时候大小不一样呢?
没错 , 这正是因为内存对齐的影响 , 导致的结果不同 。 对于我们大部分程序员来说 , 都不知道内存是怎么分布的 。
实际上因为这是编译器该干的活 , 编译器把程序中的每个数据单元安排在合适的位置上 , 导致了相同的变量 , 不同声明顺序的结构体大小的不同 。 文章插图
文章插图
几种类型数据所占字节数int , long int , short int 的宽度和机器字长及编译器有关,但一般都有以下规则(ANSI/ISO制订的)
数据类型16位编译器32位编译器64位编译器char1字节1字节1字节char*2字节4字节8字节short int2字节2字节2字节int2字节4字节4字节unsigned int2字节4字节4字节float4字节4字节4字节double8字节8字节8字节long4字节4字节8字节long long8字节8字节8字节unsigned long4字节4字节8字节
 文章插图
文章插图
什么是对齐现代计算机中内存空间都是按照 byte 划分的 , 从理论上讲似乎对任何类型的变量的访问都可以从任何地址开始 , 但实际情况是在访问特定变量的时候经常在特定的内存地址访问 。
所以这就需要各类型数据按照一定的规则在空间上排列 , 而不是顺序的一个接一个的排放 , 这就是对齐 。 内存对齐又分为自然对齐和规则对齐 。
对于内存对齐问题 , 主要存在于 struct 和 union 等复合结构在内存中的分布情况 , 许多实际的计算机系统对基本类型数据在内存中存放的位置有限制 , 它们要求这些数据的首地址的值是某个数M(通常是4或8);
对于内存对齐 , 主要是为了提高程序的性能 , 数据结构 , 特别是栈 , 应尽可能在自然边界上对齐 , 经过对齐后 , cpu 的内存访问速度大大提升 。
自然对齐指的是将对应变量类型存入对应地址值的内存空间 , 即数据要根据其数据类型存放到以其数据类型为倍数的地址处 。
例如 char 类型占1个字节空间 , 1的倍数是所有数 , 因此可以放置在任何允许地址处 , 而int类型占4个字节空间 , 以4为倍数的地址就有0,4,8等 。 编译器会优先按照自然对齐进行数据地址分配 。
规则对齐以结构体为例就是在自然对齐后 , 编译器将对自然对齐产生的空隙内存填充无效数据 , 且填充后结构体占内存空间为结构体内占内存空间最大的数据类型成员变量的整数倍 。 文章插图
文章插图
实验对比首先看这个结构体typedef struct test_32{ char a; short b; short c; char d;}test_32;首先按照自然对齐 , 得到如下图的内存分布位置 , 第一个格子地址为0 , 后面递增 。 文章插图
文章插图
编译器将对空白处进行无效数据填充 , 最后将得到此结构体占内存空间为8字节 , 这个数值也是最大的数据类型 short 的2个字节的整数倍 。
如果稍微调换一下位置的结构体typedef struct test_32{ char a; char b; short c; short d;}test_32;同样按照自然对齐如下图分布 文章插图
文章插图
可以看到按照自然对齐 , 变量之间没有出现间隙 , 所以规则对齐也不用进行填充 , 而这里有颜色的方格有6个 , 也就是6个字节
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?
- 五金|我院承担的顺德区家居五金国际质量比对项目顺利通过成果验收