在推荐系统中,我还有隐私吗?联邦学习:你可以有( 三 )
2.3 隐私设计解决方案
【在推荐系统中,我还有隐私吗?联邦学习:你可以有】本文的隐私保护联邦学习方案不需要在中央服务器上知道用户的身份 。 这主要是因为每个用户只需向中央服务器发送 f(u,i)的更新 , 利用公式(12)聚合这些更新 , 在此过程中无需参考用户的身份 。
完成的 FCF 流程见如下算法 1: 文章插图
文章插图
2.4 实验结果
作者评估了 CF 和 FCF 的推荐性能 , 分别计算前 10 个推荐结果的标准评估指标(the standard evaluation metrics)、精度(Precision) , 召回率(Recall) , F1 , 平均平均精度(MAP)和均方根误差(RMSE) 。 此外 , 还计算了 FCF 和 CF 的性能指标之间的 “diff%” 如下: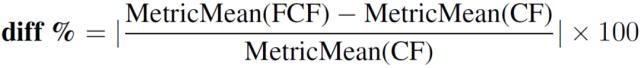 文章插图
文章插图
表 1 给出了两个真实数据集和模拟数据集在 10 轮模型重建实验中用户平均的测试集性能指标 。 其中 , 真实数据集分别为 The MovieLens rating datasets 和 In-house Production Dataset 。 模拟数据集是通过随机模拟用户、电影和浏览活动生成的 。 具体来说 , 创建一个由 0 和 1 组成的用户 - item 交互矩阵 。 其中 80% 的数据是稀疏的 , 附加的约束条件是每个用户至少有 8 个浏览活动 , 并且每个 item 至少被观察一次 。 在表 1 实验的模型构建过程中 , 每个用户的数据被随机分为 60% 的训练、20% 的验证和 20% 的测试集 。 使用验证集和训练集来寻找最优的超参数和学习模型参数 , 测试集则是用来预测推荐和评估在未知用户数据上的性能分数 。 结果表明 , FCF 和 CF 模型的结果在测试集推荐性能指标方面非常相似 。 平均而言 , 五个指标中任何一个指标的 diff% CF 和 FCF 小于 0.5% 。 标准差 std 也很小 , 表明多次运行后能够收敛到稳定和可接受的解决方案中 。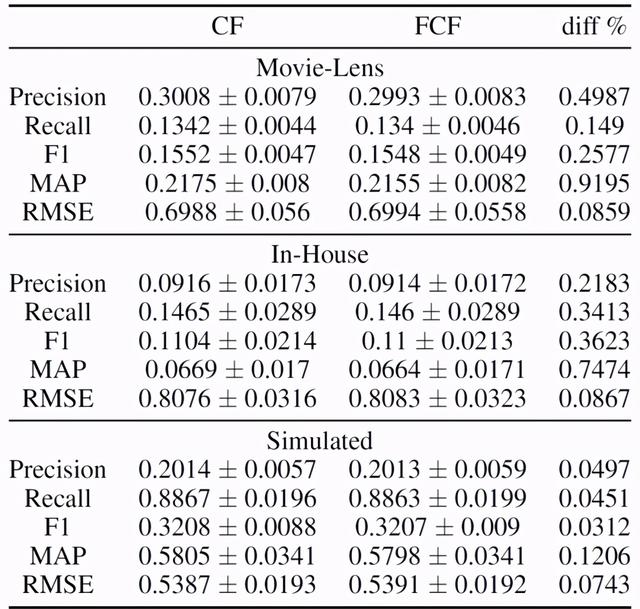 文章插图
文章插图
表 1. 使用所有用户的平均值比较协同过滤器(CF)和联邦协同过滤器(FCF)之间的测试集性能指标 。 这些值表示 10 个不同模型构建的平均标准差 。 diff% 指 CF 和 FCF 平均值之间的百分比差 。
本文是使用联邦学习框架实现隐私保护推荐系统的第一次尝试 , 是基于 CF 的推荐系统实现的 。 在这篇文章中 , 作者表示将会继续探索基于模拟器的对真实世界场景的分析 , 以持续异步的方式(在线学习)从客户端收集更新 。 此外 , 对通信有效载荷和通信效率的分析有助于评估此类系统在实际场景中的应用效果 。 最后作者计划进一步通过结合安全联邦学习方法来研究攻击和威胁对推荐系统的影响 。
三、解决联邦协同过滤中存在的问题 - 新闻推荐
由第二节中的介绍可知 , FCF 实现了联邦学习框架下的推荐系统 , 解决了推荐系统中的用户隐私保护问题 , 同时 FCF 与经典 CF 的推荐性能相差不大 。 但是 , FCF 也存在一些问题 , FCF 要求所有用户都参与到联邦学习的过程中来训练他们的向量 , 这在现实世界的推荐场景中是不实际的 , 一些用户受限于设备、网络性能等 , 无法进行模型训练 。 此外 , FCF 使用 item 的 ID 来表示 item , 这就要求预先对需要处理的 item 进行编号 , 而没有进行编号的新 item 就无法处理了 。 但是我们知道 , 在真正的推荐系统应用场景中 , 大量的新 item、新知识都是实时刷新推送的 , 这种强制预知的方式在实际问题中是不适用的 。
在论文《Privacy-Preserving News Recommendation Model Learning》[3]中 , 来自清华和微软研究院的研究人员针对新闻推荐问题对 FCF 进行了改进 , 具体提出了一种隐私保护方法(Fed-NewsRec) , 利用海量用户的行为数据 , 训练出准确的新闻推荐模型 。 此外 , 提出应用局部差分隐私来保护用户客户端设备和中央服务器之间通信的局部梯度中的私有信息 。 Fed-NewsRec 的完整结果见图 2 。 在 Fed-NewsRec 框架中 , 新闻平台(网站或应用程序)上的用户行为存储在用户的本地设备中 , 而不需要上传到服务器中 。 另外 , 提供新闻服务的服务器不记录也不收集用户的行为 , 这可以减轻用户的隐私顾虑和减少数据泄露的风险 。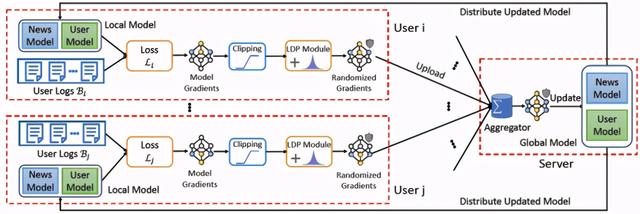 文章插图
文章插图
图 2. 隐私保护新闻推荐方法的框架
2.1 新闻模型(News Model)
在 Fed-NewsRec 中 , 沿用经典新闻推荐模型中的新闻模型 。 新闻模型的目的是学习新闻表征 , 从而对新闻内容进行建模 , 其结构如图 3 。 新闻模型从下到上一共四层 。 第一层是词嵌入 , 它将新闻标题中的词序转换成语义嵌入向量序列 。 第二层是一个 CNN 网络 , 它通过捕捉本地上下文来学习单词表示 。 第三层是一个多头自注意力网络 , 它可以通过模拟不同单词之间的长期关系来学习上下文单词的表示 。 第四层是注意力网络 , 它通过选择信息词 , 从多头自注意力网络的输出中构建新闻表征向量 t 。
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 行业|现在行业内客服托管费用是怎么算的
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 看过明年的iPhone之后,现在下手的都哭了