来自复旦大学自然语言处理团队,这个NLP工具包有何亮点
自然语言处理(NLP)是人工智能领域中的一个重要方向 。 它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法 。
在进行 NLP 开发的时候 , NLP 工具包是不可缺少的一部分 , 其中包含的数据集和预训练模型可以较大的提升开发效率 。
今天推荐的这个开源项目就是来自复旦大学的 NLP 团队 , 看看他们的 NLP 工具包有什么好玩的地方吧 。
项目名称:fastNLP
项目作者:复旦大学自然语言处理(NLP)团队
项目地址:
项目简介fastNLP 是一款轻量级的自然语言处理(NLP)工具包 , 目标是快速实现 NLP 任务以及构建复杂模型 。
项目特性
- 统一的 Tabular 式数据容器 , 简化数据预处理过程;
- 内置多种数据集的 Loader 和 Pipe , 省去预处理代码;
- 各种方便的 NLP 工具 , 例如 Embedding 加载(包括 ELMo和BERT)、中间数据 cache 等;
- 部分数据集与预训练模型的自动下载;
- 提供多种神经网络组件以及复现模型(涵盖中文分词、命名实体识别、句法分析、文本分类、文本匹配、指代消解、摘要等任务);
- Trainer 提供多种内置 Callback 函数 , 方便实验记录、异常捕获等 。
- numpy>=1.14.2
- torch>=1.0.0
- tqdm>=4.28.1
- nltk>=3.4.1
- requests
- spacy
- prettytable>=0.7.2
以文本分类任务为例 , 下图展示了一个 BiLSTM+Attention 实现文本分类器的模型流程图:
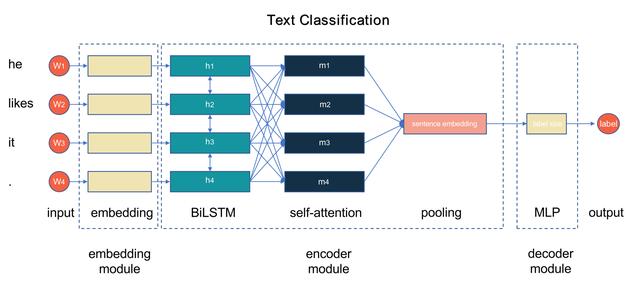 文章插图
文章插图fastNLP 在 embeddings 模块中内置了几种不同的 embedding:静态 embedding(GloVe、word2vec)、上下文相关 embedding (ELMo、BERT)、字符 embedding(基于CNN或者LSTM的CharEmbedding)
与此同时 , fastNLP 在 modules 模块中内置了两种模块的诸多组件 , 可以帮助用户快速搭建自己所需的网络 。两种模块的功能和常见组件如下:
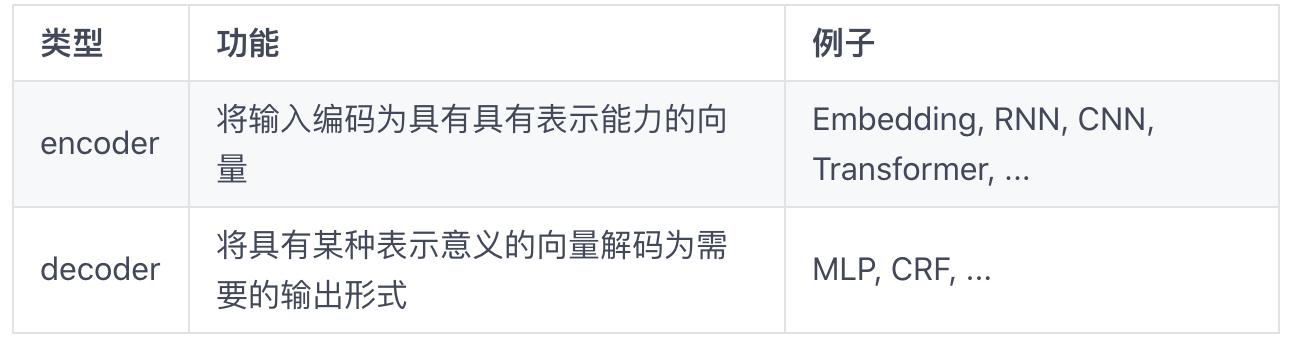 文章插图
文章插图项目结构
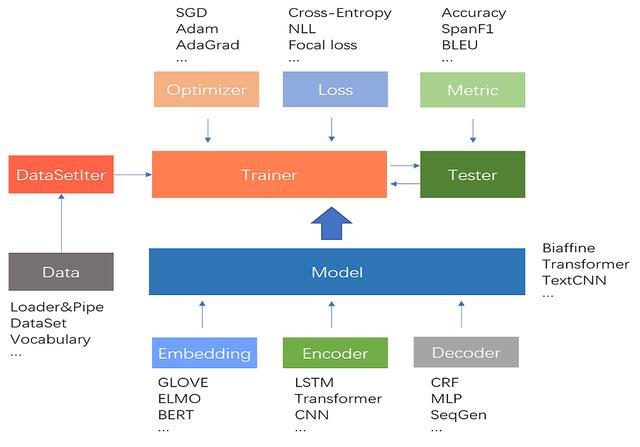 文章插图
文章插图fastNLP 的大致工作流程如上图所示 , 而项目结构如下:
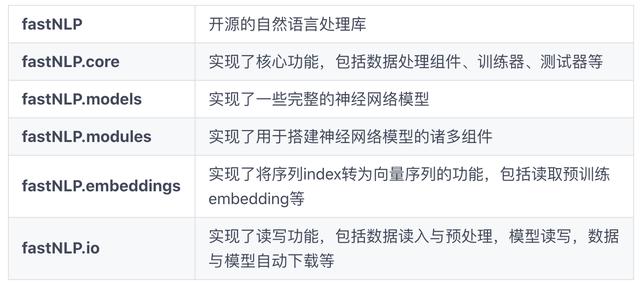 文章插图
文章插图【来自复旦大学自然语言处理团队,这个NLP工具包有何亮点】如果你想要了解项目的更多信息 , 那么就点击下方了解更多前往项目主页看看吧 。
- 手机|便宜没好货!为什么二手iPhone很便宜,这些手机都来自哪儿?
- 王兴|王兴,投兄弟又赚了一笔
- 红米K30S|大学生玩王者荣耀的话,红米Note 9足够吗?
- 靴子|美团需要新靴子
- 吉林大学TARS-GO战队视觉代码
- 荷兰:中国为研究光刻机技术,专门创办芯片大学,“反人类”操作
- 清华大学刘知远:知识指导的自然语言处理
- 来自产业链的确认:iPhone12全系采用高通基带
- 获政府2000万澳元助力,阿德莱德大学AI研究将再度腾飞
- 深圳40年40人,为何大疆汪滔没上榜,反而是他大学老师上榜?