神经语言模型( 二 )
5、运行结果
Epoch: 1000 cost = 0.113229
Epoch: 2000 cost = 0.015353
Epoch: 3000 cost = 0.004546
Epoch: 4000 cost = 0.001836
Epoch: 5000 cost = 0.000853
[['我喜欢苹果'], ['我爱运动'], ['我讨厌老鼠']] -> ['苹果', '运动', '老鼠']
3.1.3词嵌入特征词嵌入(Word Embedding)一般通过神经网络能学习语料库中的一些特性或知识 ,
图1-4为在某语料库上训练得到的一个简单词嵌入矩阵 , 从这个特征我们可以看出 , 有些词是相近的 , 如男与女 , 国王与王后 , 苹果与橘子等 , 这些相似性是从语料库学习得到 。 如何从语料库中学习这些特征或知识?人们研究出多种有效方法 , 其中最著名的就是Word2vec 。
另外我们可以把词嵌入这些特性 , 通过迁移方法 , 应用到下游项目中 。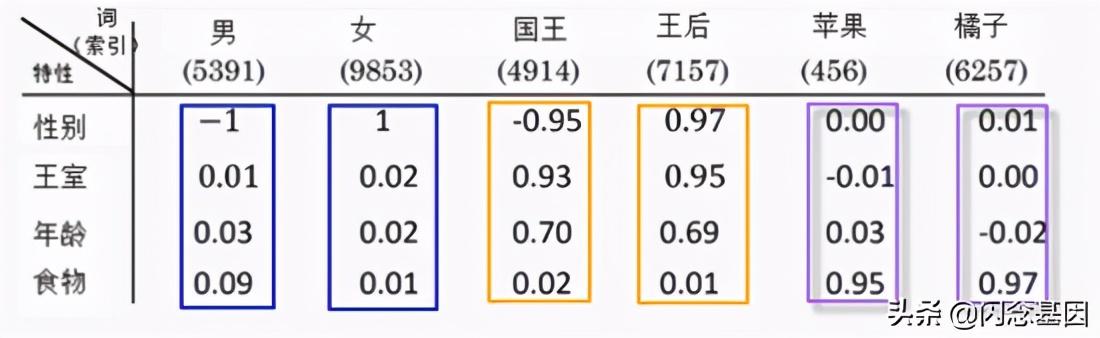 文章插图
文章插图
图1-4 词嵌入特征示意图
与从语料库中学习词嵌入类似 , 在视觉处理领域中 , 也是通过学习图像 , 把图像特征转换为编码 , 整个过程如下图1-5所示 。 只不过在视觉处理中我们一般不把学到的向量为词嵌入 , 而往往称之为编码 。 文章插图
文章插图
图1-5 把图像转换为编码示意图
3.1.4 word2vec简介词嵌入(word Embedding)最早由 Hinton 于 1986 年提出的 , 可以克服独热表示的缺点 。 解决词汇与位置无关问题 , 可以通过计算向量之间的距离(欧式距离、余弦距离等)来体现词与词的相似性 。 其基本想法是直接用一个普通的向量表示一个词 , 此向量为:
[0.792, -0.177, -0.107, 0.109, -0.542, ...] , 常见维度50或100 。 用这种方式表示的向量 , “麦克”和“话筒”的距离会远远小于“麦克”和“天气”的距离 。
词嵌入表示的优点是解决了词汇与位置无关问题 , 不足是学习过程相对复杂且受训练语料的影响很大 。 训练这种向量表示的方法较多 , 常见的有LSA、PLSA、LDA、Word2Vec等 , 其中Word2Vec是Google在2013年开源的一个工具 , Word2Vec是一款用于词向量计算的工具 , 同时也是一套生成词向量的算法方案 。 Word2Vec算法的背后是一个浅层神经网络 , 其网络深度仅为3层 , 所以 , 严格说Word2Vec并非深度学习范畴 。 但其生成的词向量在很多任务中都可以作为深度学习算法的输入 , 因此 , 在一定程度上可以说Word2Vec技术是深度学习在NLP领域的基础 。 训练Word2Vec主要有以下两种模型来训练得到:
1、CBOW模型
CBOW模型包含三层 , 输入层、映射层和输出层 。 其架构如图1-6 。 CBOW模型中的w(t)为目标词 , 在已知它的上下文w(t-2) , w(t-1) , w(t+1) , w(t+2)的前提下预测词w(t)出现的概率 , 即:p(w/context(w)) 。目标函数为: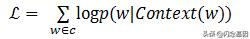 文章插图
文章插图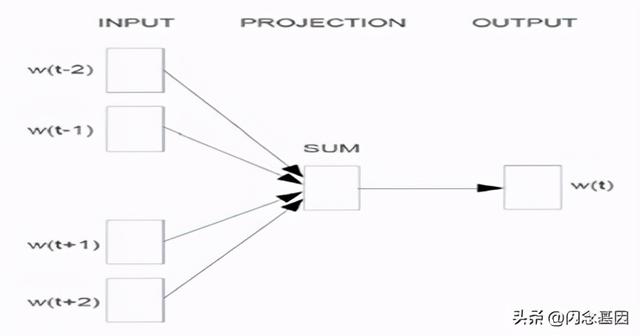 文章插图
文章插图
图1-6 CBOW模型
CBOW模型训练其实就是根据某个词前后若干词来预测该词 , 这其实可以看成是多分类 。 最朴素的想法就是直接使用softmax来分别计算每个词对应的归一化的概率 。 但对于动辄十几万词汇量的场景中使用softmax计算量太大 , 于是需要用一种二分类组合形式的hierarchical softmax , 即输出层为一棵二叉树 。
2、Skip-gram模型
Skip-gram模型同样包含三层 , 输入层 , 映射层和输出层 。 其架构如图1-7 。 Skip-Gram模型中的w(t)为输入词,在已知词w(t)的前提下预测词w(t)的上下文w(t-2) , w(t-1) , w(t+1) , w(t+2) , 条件概率写为:p(context(w)/w) 。 目标函数为: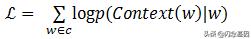 文章插图
文章插图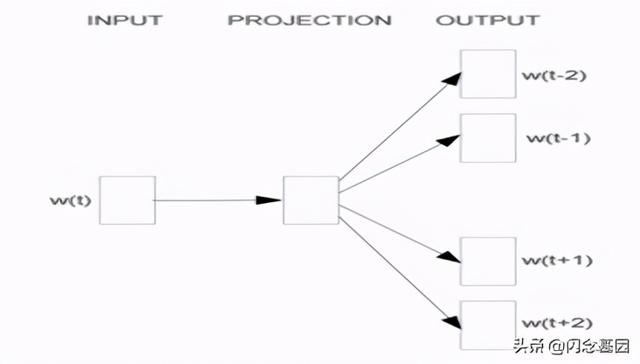 文章插图
文章插图
图1-7 Skip-gram模型
作者:feiguyun
出处:
- 设计语言|全新家族设计,三星Galaxy A32渲染图曝光
- 用于|用于半监督学习的图随机神经网络
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 建筑|国产第一台掘进机模型亮相“2020长江·三峡建筑产业博览会”
- 曝光|微软新专利曝光 可以与会者面部表情和肢体语言为会议打分
- 学习C语言的软件,就突然被我绿了?
- LeetCode第1 题:两数之和 Go语言精解
- 清华大学刘知远:知识指导的自然语言处理
- 「数据架构」TOGAF建模:概念数据模型图
- 盘点:2020年5种流行的 AI 编程语言,就业高薪不是梦