神经语言模型
作者:feiguyun
出处:
神经语言模型n-gram语言模型简单明了 , 解释性较好 , 但有几个较大缺陷:
1、维度灾难 , 随着n值越大 , 单词组合数指数级增长 , 由此带来相关联合或条件概率大量为0;
2、因n一般不能超过3或4 , 这影响模型利用单词更多邻居信息;
3、n-gram使用单词组合的频度作为计算基础 , 这需要提前计算 , 且无法泛化到相似语句或相似单词的情况 。
接下来将介绍的神经网络语言模型(NNLM) , 可有效避免n-gram的这些不足 , NNLM使用哪些方法或技术来解决这些问题的呢?请看下节内容 。
3.1 神经网络语言模型Yoshua Bengio团队在2003年在论文《A Neural Probabilistic Language Model》中提出神经网络语言模型(NNLM) , 可以说是后续神经网络语言模型的鼻祖 , 其创新点有以下几点 , 这些亮点也是它避免n-gram模型不足的重要方法 。
1、使用词嵌入(word Embedding)代替单词索引;
2、使用神经网络计算概率
当然 , 这个NNLM还有很多不足 , 其中整个模型因使用softmax , tanh等激活函数 , 在面对较大的语料库时(如词汇量在几万、几百万、甚至更多)计时效率很低 , 而且模型有点繁琐不够简练 , 后续我们将介绍一些改进模型 。
3.1.1 神经语言模型(NNLM)Yoshua Bengio团队提出的这个NNLM的架构图1-2所示 。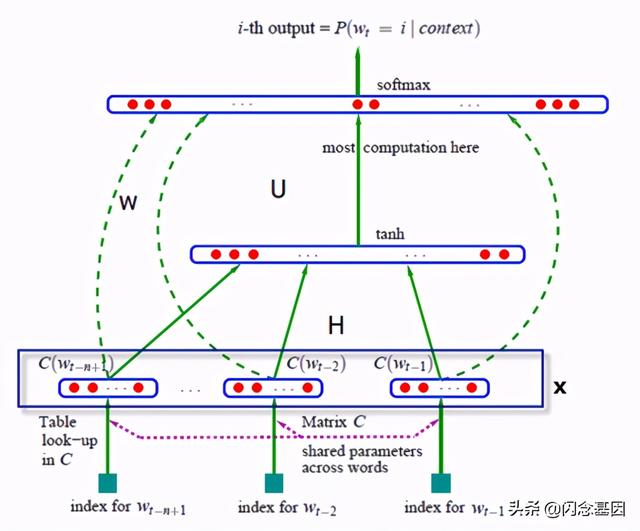 文章插图
文章插图
图1-2 神经网络架构
假设该模型训练的语料库的词汇量为|V| , 语料库中每个单词w_i转换成词向量的大小维度为m 。 把每个单词w_i转换为词嵌入的矩阵为C , 其形状为|V|xm 。 其过程如图1-3所示 。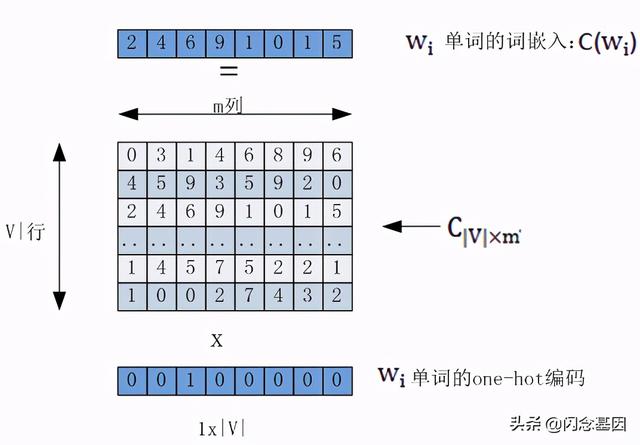 文章插图
文章插图
图1-3 通过矩阵C把词索引转换为词嵌入
整个网络架构用表达式表示:
y=b+Wx+U tanh(d+Hx)
其中Wx表示输入层与输出层有直接联系(图1-2中的虚线部分) , 如果不要这个链接 , 直接设置W为0即可 , b是输出层的偏置向量 , d是隐层的偏置向量 , 里面的x即是单词到特征向量的映射 , 计算如下:
x=(C(w_(t-1) ),C(w_(t-2) ),?,C(w_(t-n+1)))
其中C是一个矩阵 , 其形状为|V|xm
假设隐层的神经元个数为h , 那么整个模型的参数可以细化为θ = (b, d, W, U, H, C) 。 下面各参数含义及形状:
b是词向量x到输出层的偏移量 , 维度为|V|
W是词向量x到输出层的权重矩阵 , 维度为|V|x(n?1)m
d是隐含层的偏移量 , 维度为h
H是输入x到隐含层的权重矩阵 , 形状为hx(n-1)m
U是隐含层到输出层的权重矩阵 , 形状为|V|xh
网络的第一层(输入层)是将C(w_(t-1) ),C(w_(t-2) ),?,C(w_(t-n+1))这已知的n-1和单词的词向量首尾相连拼接起来 , 形成(n-1)m的向量x 。
网络的第二层(隐藏层)直接用d+Hx计算得到 , d是一个偏置项 。 之后 , 用tanh作为激活函数 。
网络的第三层(输出层)一共有|V|个节点 , 最后使用softmax函数将输出值y归一化成概率 。
最后 , 用随机梯度下降法把这个模型优化出来就可以了 。
3.1.2 NNLM的PyTorch实现这样用一个简单实例 , 实现3.1.1节的计算过程 。
1、导入需要的库或模块
import torchimport torch.nn as nnimport torch.optim as optimimport jieba2、定义语料库及预处理函数
#定义一个简单语料库sentences = [ "我喜欢苹果", "我爱运动", "我讨厌老鼠"] #预处理语料库 , 得到批量数据def make_batch(sentences):input_batch = []target_batch = []for sen in sentences:word = list(jieba.cut(sen)) #对每句话进行中文分词input = [word_dict[n] for n in word[:-1]] # 创建(1至n-1) 作为输入 , 这里实际上就是取前两个词 。target = word_dict[word[-1]] # 这里把每句的最后一个词作为目标,input_batch.append(input)target_batch.append(target)return input_batch, target_batch3、构建模型
【神经语言模型】# Modelclass NNLM(nn.Module):def __init__(self):super(NNLM, self).__init__()self.C = nn.Embedding(n_class, m)self.H = nn.Linear(n_step * m, n_hidden, bias=False)self.d = nn.Parameter(torch.ones(n_hidden))self.U = nn.Linear(n_hidden, n_class, bias=False)self.W = nn.Linear(n_step * m, n_class, bias=False)self.b = nn.Parameter(torch.ones(n_class))def forward(self, X):X = self.C(X) # X : [batch_size, n_step, n_class]X = X.view(-1, n_step * m) # [batch_size, n_step * n_class] , 对应xtanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class] , 对应yreturn output4、训练模型
if __name__ == '__main__':n_step = 2 # 对应n-gram中n-1值n_hidden = 2 #对应隐含层的节点数hm = 2 #对应于m的值words_list=[]for sen in sentences:a=list(jieba.cut(sen))words_list.extend(a)words_list=list(set(words_list))word_dict = {w: i for i, w in enumerate(words_list)}number_dict = {i: w for i, w in enumerate(words_list)}n_class = len(word_dict)# 语料库中词汇量 , 相当与|V|model = NNLM()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)input_batch, target_batch = make_batch(sentences)input_batch = torch.LongTensor(input_batch)target_batch = torch.LongTensor(target_batch)# Trainingfor epoch in range(5000):optimizer.zero_grad()output = model(input_batch)# output : [batch_size, n_class], target_batch : [batch_size]loss = criterion(output, target_batch)if (epoch + 1) % 1000 == 0:print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward()optimizer.step()#print(model.H.weight)#查看H训练后的权重# 预测predict = model(input_batch).data.max(1, keepdim=True)[1]# 测试print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
- 设计语言|全新家族设计,三星Galaxy A32渲染图曝光
- 用于|用于半监督学习的图随机神经网络
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 建筑|国产第一台掘进机模型亮相“2020长江·三峡建筑产业博览会”
- 曝光|微软新专利曝光 可以与会者面部表情和肢体语言为会议打分
- 学习C语言的软件,就突然被我绿了?
- LeetCode第1 题:两数之和 Go语言精解
- 清华大学刘知远:知识指导的自然语言处理
- 「数据架构」TOGAF建模:概念数据模型图
- 盘点:2020年5种流行的 AI 编程语言,就业高薪不是梦