低频少样本长验证周期场景下的算法设计( 三 )
另外就是 early stop 的调优方法 , 比如说这个模型在训练的时候 , 模型应该什么时候停止训练 。 一般来说会用到的方法是学习曲线 ( learning curve ) , 模型在训练的时候可能迭代一百次、迭代一千次的时候看模型的学习曲线有没有有很大的这种变化 , 如果在进行更多次迭代时发现测试集上效果在在下降 , 但是在训练集上其实在上升 , 这就是过拟合现象 。 从最好结果看 , 模型在 recall 为30%的时候 , 差不多有60%被带看或认购的比例 , 在 recall 的为70%时能达到91%的这样一个比例 , 从结果上来看还是能达到预期的结果 。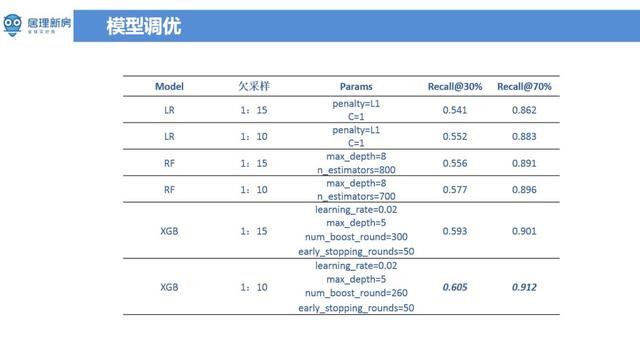 文章插图
文章插图
▌可解释性分析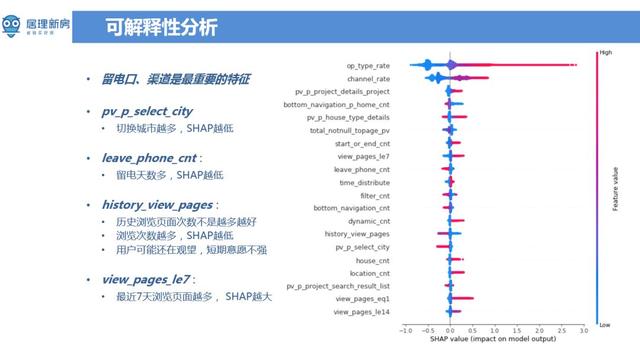 文章插图
文章插图
接下来主要讲一下可解释性的分析 , 因为整个房产行业的客单价都比较高 , 相当于说每个客户都特别的宝贵 。 以北京为例 , 平均每单利润在12万到15万 。 若将好线索误分为坏线索 , 没有为客户好好服务将会导致较大的损失 。 对于业务人员 ( 客服 , 咨询师 ) 而言 , 模型预估结果会与他们原有的一些工作模式和习惯矛盾 , 需要向业务人员解释模型预估结果 。 当算法去服务于业务团队的时候 , 这种可解释性显得尤为重要 。 通过 xgboost 计算得到的特征重要性 ( feature importance ) 不一定是完全可解释的 , 它和特征在决策森林中出现的次数相关 。 但特征在决策森林里面出现的次数越多并不能说明特征越重要 。 这里采用的是 SHAP 来进行可解释性分析 , SHAP 计算的是一个特征加入到模型时的边际贡献 , 考虑了该特征在所有的特征序列的情况下不同的边际贡献 。 在 SHAP 图中 , 纵坐标是特征列表 , 横坐标是从负数到正数的取值范围 , 表示对模型输出值的影响 。 留电口、渠道特征是从 SHAP 方法来看是最为重要的特征 。 一般来说通过搜索渠道来的用户 , 购房的意向比较强烈 , 这个也和基本认知符合 。 另一个比较显著的特征 pv_p_select_city , 表示切换城市的动作越多 , 用户质量越差 。 举个例子:假设有北京和天津的都有业务 , 客户可能一会看看北京的房子 , 一会又选择天津的房子 , 就中间各种摇摆 , 客户可能也没太想好到底在哪个城市要买 , 这种情况下需要花费很多精力去说服客户 , 用户转化成本计较高 。 留电天数越多 , 稍微比越低 , 就相当于一个月之前留的线索和昨天留的线索对比来看 , 明显是距离现在时间近的线索质量会高一点 。 如果客户上午留的电话 , 在下午的时候咨询师就能给客户提供服务 , 这种情况下转换概率会很大 。 但并不是所有的特征影响与我们对模型的预期是相同的 , 比如说特征 history_view_pages ( 用户在 APP 的上 PV 贡献度 ) , PV 贡献度越大 , 线索质量反而比较差 。 但如果从购房意愿来看也是可以理解的 , 对于购房意特别强的客户 , 浏览页面比较集中 , 更能体现用户的关注点 , 虽然只使用了不到 App 1% 的特征 , 但转化率比较好 。 反而是那些楼盘看的特别多的用户在行为上表现的流程和浏览广度都不错 , 但质量确实比较低 。 这种聚焦观点不仅适用于当前场景 , 也可以推广到产品上的其他场景 。
▌实际效果 文章插图
文章插图
从模型效果来看 , 客户认购量提升了十七个百分点 , 基本达到了算法预期目标 。 从认购到带看的目标变化 , 将周期从两个月缩减到了两周 , 后续希望能找到一个更好的指标来代替带看 , 进一步缩短模型周期 。 另外居理新房还做了很多线下数据的累积 。 比如说咨询师与客户的电话录音 , 微信记录 , 交通行为等 。 通过这些离线数据能大概分析出咨询师和客户的行为 , 比如说通话频率 , 通话时长 , 微信验证 , 聊天频率 , 客户需求响应时长等多种详细指标 。 目前不同的城市数据累积量不同 , 等数据量积累到一定程度 , 可以为不同的城市设置独立的模型 。 另外模型融合 ( stacking ) 是后续优化的方向 , 看能不能做出更有意思的效果 。 目前的模型是基于无线数据 , PC 数据相对无线来说 , 用户行为比较少 , 下一步是跨站整合 PC 和无线的数据 。
作者:张惟师
- GB|备货充足要多少有多少,5000mAh+128GB,红米新机首销快速现货
- 整形美容|双十一医美不良事件高发 热玛吉风险高 业内:医美职业打假人太少
- 占营收|华为值多少钱
- 垫底|5G用户突破2亿:联通垫底,电信月增700万,中国移动有多少?
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 不坑|库克不讲“性价比”!一台iPhone12至少赚4千,网友:不坑穷人
- 跑腿|机器人“小北”上岗 让办事群众少跑腿
- 拼少少|又一电商火了,被称为“山寨版”拼多多,刚上线就被“群嘲”
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 新机|12月预告:至少11款新机,但可能要“失望”