低频少样本长验证周期场景下的算法设计
 文章插图
文章插图
▌业务背景介绍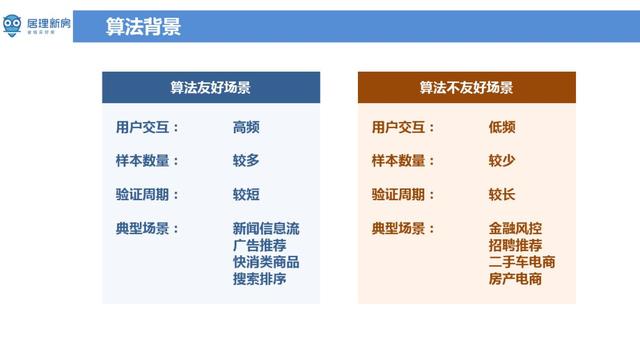 文章插图
文章插图
【低频少样本长验证周期场景下的算法设计】工业界中存在算法友好场景 , 也存在算法不友好的场景 。 算法友好场景中用户交互信息频繁 , 样本数量充足 , 模型验证周期短 , 常见的应用场景有新闻信息流、广告推荐、快消类商品 , 搜索排序等;算法不友好的场景中恰好相反 , 面临用户交互信息少 , 样本数量不足 , 模型验证周期长等多种问题 , 如金融风控、招聘推荐、二手车点电商、房产电商等场景 。 居理新房业务场景中属于后者 , 是在产业互联网中一种客单价极高 , 频率极低的典型算法不友好场景 。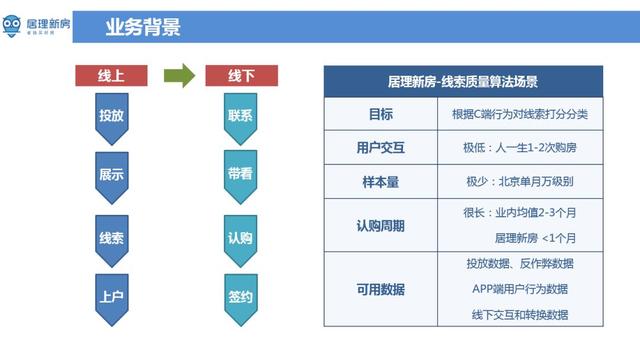 文章插图
文章插图
居理新房打造了独特的线上、线下的闭环生态系统 。 线上部分通过投放效果类、品牌类广告 ( 如 SEM ,信息流等 ) , 在广告落地页上进行产品展示 , App 下载等方式来引流客户 。 客户在使用相关产品线的产品时会产生一些线索信息 。 这里的线索可以理解为用户的相关信息(如手机号码等) 。 线索信息较为混乱 , 真假不一 , 因此需要在线客服人员对客户留下的线索进行筛选确认 , 将具有真实购房意愿的名单筛选出来给线下咨询师 。 由咨询师联系客户 , 带领客户预约看房 ,客户满意的话 , 带领客户继续认购、签约等后续环节 。 从上述环节中可以看到线上获客到线下签约数据量呈漏斗式层层过滤 , 最后签约量较少 。 在整个流程中 , 广告自动投放和线索质量质量评估都有相关算法 , 这里主要介绍线索质量相关的算法 。 不同线索的质量不同 , 对于线索质量高的用户 , 如果能在恰当的时间点为预测出客户的购房需求 , 可以提高用户的转化率 , 对于线索质量低的客户 , 例如暂时处于观望或者是虚假信息 , 如果能尽早的识别出来这一部分群体 , 可以降低线上客服审核成本 , 进而提高咨询师的工作效率 。 这样比较自然的引入用线索质量二分类的算法 , 将好的线索直接给咨询师 , 不太好的线索给客服进行审核 。 但是这种场景下的分类算法面临多种挑战 , 首先用户交互频次极低 , 一个人一生平均购买一到两次房 , 也就几乎不存在历史购买行为信息 , 其次是样本量少 , 举个例子 , 北京市2019年上半年新房成交量在 3w 套左右 , 其中居理新房的成交比例在2%左右 , 整体用于训练的样本不多 。 另外客户决策周期长 , 从平台首次接待客户到客户完成交易的周期业内均值在2-3个月 , 即使居理新房周期短一些 , 流程周期也要在20天到30天 , 换句话说是跟单周期长 , 算法上线后 , 至少跟单一个月才能观察算法效果 。 客户相关信息较少 , 目前主要有客户渠道来源 ( 头条创意 , 百度渠道 ) , 以及客户在 App 上的历史浏览 , 点击 , 搜索等行为信息 , 还有一些线下获取的大量非结构化信息 ( 如咨询师与客户的线下交互行为 ) , 但这部分数据线上获取不到 , 一般用来验证算法的有效性 。
▌算法平台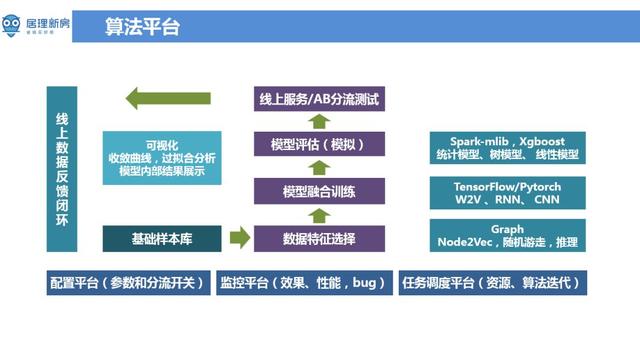 文章插图
文章插图
目前居理新房搭建了复用性和扩展性都比较好的算法平台 , 可以通过一些灵活的配置 , 实现相关监控 , 任务调度 , 模型校验 , 可视化页面以及 AB Test 。 算法平台底层支持多种算法引擎包括机器学习模型平台 ( Spark-MLlib , Xgboost ) , 深度学习平台 ( Tensorflow , Pytorch ) 以及图相关模型 。 可以通过 pipeline 的方法整合数据流和算法引擎 。
▌样本选择 文章插图
文章插图
如何选择正负样本?比较直观的做法将最终是否发生认购行为作为正负样本的评估依据 。 但在当前场景下 , 由于房屋交易业务转化率低 , 从线上访问 UV 到最终房屋认购 , 比例在万分之几左右 , 只从中间线索角度来看 , 这个比例也在2%-3%左右 。 为了解决样本稀疏问题 , 这里设置了一个代理目标 , 将是否发生带看行为作为正负样本的评估依据 。 带看行为发生在认购行为之前 , 发生认购行为占带看比例中的10分之一左右 , 周期也可从一到两个月缩减到两周左右 。 那么样本在一个周期 T 内 , 将是否被带看作为正负样本的评估依据 。 另外可以后续模型训练时 , 提高具有多次带看行为或者发生认购行为的权重 。 在一个时间周期 T 内 , 可能存在跟单不完全的情况 , 但这部分比例在10%以内 , 可以忽略 。 由于正负样本比例差异较大 , 在样本量较大的情况下 , 这种比例可以接受 , 但在样本量较少的情况下 , 正负样本比例差异导致模型学习困难 。 因此在训练模型前可以先对样本进行采样预处理 。 常见的样本采样方法有欠采样和过采样 。 欠采样是保持数据集正样本数量不变 , 根据一定比例去随机抽取负样本,过采样是通过已有正样本来构造虚拟正样本 , 来减小正负样本差异 。 常见的过采样方法有 SMOTE 等 。 但是采样方法会影响数据集中的正负样本分布 , 在关注概率值的分类等业务场景下 , 需要对模型输出的概率进行校准 。
- GB|备货充足要多少有多少,5000mAh+128GB,红米新机首销快速现货
- 整形美容|双十一医美不良事件高发 热玛吉风险高 业内:医美职业打假人太少
- 占营收|华为值多少钱
- 垫底|5G用户突破2亿:联通垫底,电信月增700万,中国移动有多少?
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 不坑|库克不讲“性价比”!一台iPhone12至少赚4千,网友:不坑穷人
- 跑腿|机器人“小北”上岗 让办事群众少跑腿
- 拼少少|又一电商火了,被称为“山寨版”拼多多,刚上线就被“群嘲”
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 新机|12月预告:至少11款新机,但可能要“失望”