初识爬虫的那天,我选择了Java( 二 )
另外 , 在采集数据时 , 不同网站的时间使用格式可能不同 。 而不同的时间格式 , 会为数据存储以及数据处理带来一定的困难 。 例如 , 下图为某汽车论坛中时间使用的格式 , 即“yyyy-MM-dd”和“yyyy-MM-dd HH:mm”两种类型 。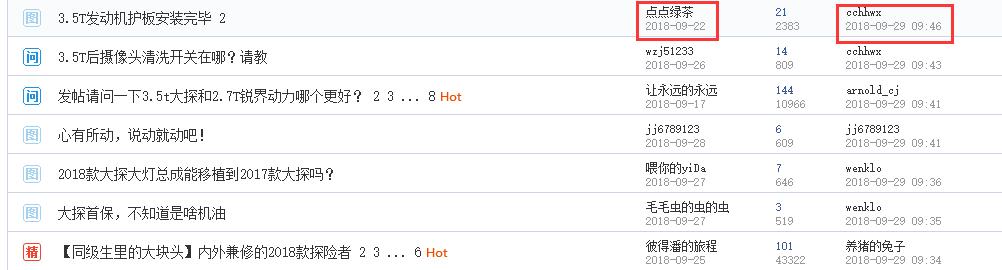 文章插图
文章插图
下图为某新闻网站中的时间使用格式“yyyy-MM-dd HH:mm:ss” 。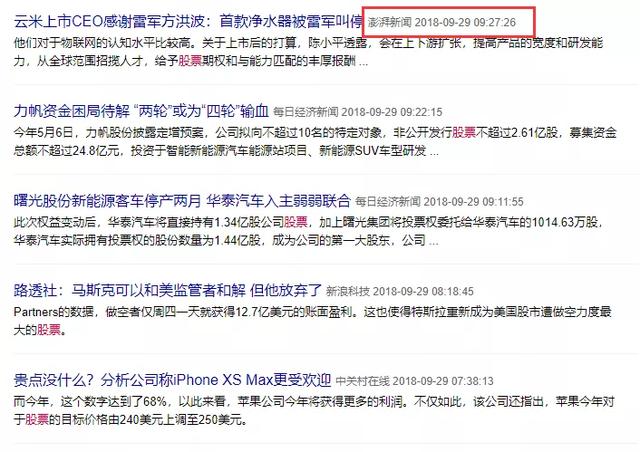 文章插图
文章插图
再如 , 艺术品网站deviantart的时间使用的是UNIX时间戳的形式 。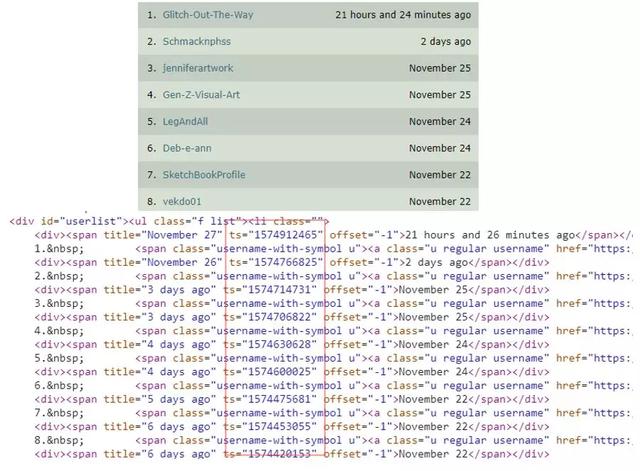 文章插图
文章插图
针对汽车论坛中的“yyyy-MM-dd”和“yyyy-MM-dd HH:mm”格式 , 可以统一转化成“yyyy-MM-dd HH:mm:ss”格式 , 以方便数据存储以及后期数据处理 。 此时 , 可以写个方法将将字符串类型的时间标准化成指定格式的时间 。 如下程序:
import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Date;public class TimeTest {public static void main(String[] args) {System.out.println(parseStringTime("2016-05-19 19:17","yyyy-MM-dd HH:mm","yyyy-MM-dd HH:mm:ss"));System.out.println(parseStringTime("2018-06-19","yyyy-MM-dd","yyyy-MM-dd HH:mm:ss"));}/*** 字符型时间格式标准化方法* @param inputTime(输入的字符串时间),inputTimeFormat(输入的格式),outTimeFormat(输出的格式).* @return 转化后的时间(字符串)*/public static String parseStringTime(String inputTime,String inputTimeFormat,String outTimeFormat){String outputDate = null;try {//日期格式化及解析时间Date inputDate = new SimpleDateFormat(inputTimeFormat).parse(inputTime);//转化成新的形式的字符串outputDate = new SimpleDateFormat(outTimeFormat).format(inputDate);} catch (ParseException e) {e.printStackTrace();}return outputDate;}}针对UNIX时间戳 , 可以通过如下方法处理:
//将unix时间戳转化成指定形式的时间public static String TimeStampToDate(String timestampString, String formats) {Long timestamp = Long.parseLong(timestampString) * 1000;String date = new SimpleDateFormat(formats,Locale.CHINA).format(new Date(timestamp));return date;}3 HTTP协议基础与网络抓包
做网络爬虫 , 还需要了解HTTP协议相关的内容 , 即要清楚数据是怎么在服务器和客户端传输的 。 文章插图
文章插图
具体需要了解的内容包括:
1. URL的组成:如协议、域名、端口、路径、参数等 。
2. 报文:分为请求报文和响应报文 。 其中 , 请求报文包括请求方法、请求的URL、版本协议以及请求头信息 。 响应报文包括请求协议、响应状态码、响应头信息和响应内容 。 响应报文包括请求协议、响应状态码、响应头信息和响应内容 。
3. HTTP请求方法:在客户端向服务器发送请求时 , 需要确定使用的请求方法(也称为动作) 。 请求方法表明了对URL指定资源的操作方式 , 服务器会根据不同的请求方法做不同的响应 。 网络爬虫中常用的两种请求方法为GET和POST 。
4. HTTP状态码:HTTP状态码由3位数字组成 , 描述了客户端向服务器请求过程中发生的状况 。 常使用200判断网络是否请求成功 。
5. HTTP信息头:HTTP信息头 , 也称头字段或首部 , 是构成HTTP报文的要素之一 , 起到传递额外重要信息的作用 。 在网络爬虫中 , 我们常使用多个User-Agent和多个referer等请求头来模拟人的行为 , 进而绕过一些网站的防爬措施 。
6. HTTP响应正文:HTTP响应正文(或HTTP响应实体主体) , 指服务器返回的一定格式的数据 。 网络爬虫中常遇到需要解析的几种数据包括:HTML/XML/JSON 。 文章插图
文章插图
在开发网络爬虫时 , 给定 URL , 开发者必须清楚客户端是怎么向服务器发送请求的 , 以及客户端请求后服务器返回的数据是什么 。 只有了解这些内容 , 开发者才能在程序中拼接URL , 针对服务返回的数据类型设计具体的解析策略 。 因此 , 网络抓包是实现网络爬虫必不可少的技能之一 , 也是网络爬虫开发的起点 。 文章插图
文章插图
本文作者钱洋博士所著新书《网络数据采集技术:Java网络爬虫实战》现已上市 。 系统地介绍了网络爬虫的理论知识和基础工具 , 并且选取典型网站 , 采用案例讲解的方式介绍网络爬虫中涉及的问题 , 以增强大家的动手实践能力 。  文章插图
文章插图
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面