大促场景系统稳定性保障实践经验总结
每到双11 , 如何保障系统高峰扛得住、长期平稳是每个大促人必须面对地问题 。 在今年双11之前 , 阿里云在上海举办了一场线下交流 , 阿里大促和稳定性保障负责人、中间件专家、解决方案专家等将历年总结的大促经验分享给参会嘉宾 , 我们选取了其中的精彩内容整理如下 。 文章插图
文章插图
一、互联网行业稳定性建设的观察与思考第一位分享嘉宾是阿里云华东互联网团队的高级解决方案架构师江煵 , 他拥有十余年的软件开发经验 , 近些年一直从事云计算方向的开发和架构工作 , 主导过多个云平台、PaaS平台的开发建设 , 对于云和互联网架构方面有比较深入的理解和实践 , 目前关注于容器、中间件、Serverless等云原生的技术方向 。 文章插图
文章插图
江煵在分享中提到 , 今年我们在新闻里听到了很多比较大的宕机事件 , 宕机的原因其实都很典型 , 删库跑路、被攻击、没有做好容量规划或者弹性能力不足、系统更改等 。 宕机后果还是比较严重 , 比如某SaaS服务商直接经济损失是两千多万 , 当天市值下跌10亿;某新能源车制造商网络中断事故当天市值下跌近数百亿美元 。 股价能涨回来 , 但对消费者的信心损害、对公司的品牌声誉的影响等这些很难在短时间内消除掉 。
关于行业的稳定性建设现状 , 不少企业稳定性建设上欠的账还是很多的 , 一些偏小且偏传统的公司 , 可能都还没有高可用方面的准备 。 即使是中大型公司 , 在稳定性建设上还是存在短板 。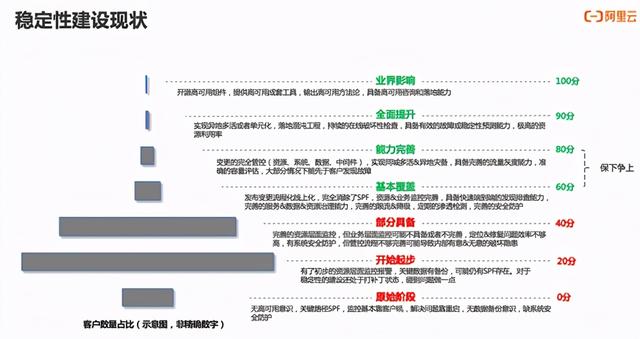 文章插图
文章插图
稳定性建设相关的工作很难被看到、被认可或客观评判 , 不出事故确实有可能是运气 , 而即使是发生事故 , 也有可能因为稳定性做的很好且已经避免了十起其他重大事故 。 所以需要一些办法来为稳定性建设工作做一些定性甚至定量的评估 , 让这方面的工作有目标、过程可跟进、结果能检验 , 所以这方面我们做了一些探索和尝试 。
这里我们提出了一个关于稳定性建设成熟度模型的设想 , 从11个维度 , 建议了两种稳定性建设成熟度评估方法:一种是雷达图模式 , 通过11个指标的打分 , 得出来一个整体分数;另一个是等级模式 , 每个指标维度根据建设的完善度给0~4分 , 我们希望所有的公司应该至少达到基础级以上 , 中大型公司能到发展级 , 行业头部公司能到成熟级水平 。
当然这个成熟度模型本身还不是特别完善 , 现在提出来给大家参考和探讨 , 未来我们会持续优化 , 不光希望给大家合理的评估参考办法 , 更希望能对行业整体水位进行分析 , 让各家对自己的稳定性建设在行业内的水位有所了解 , 便于制定合理的目标 。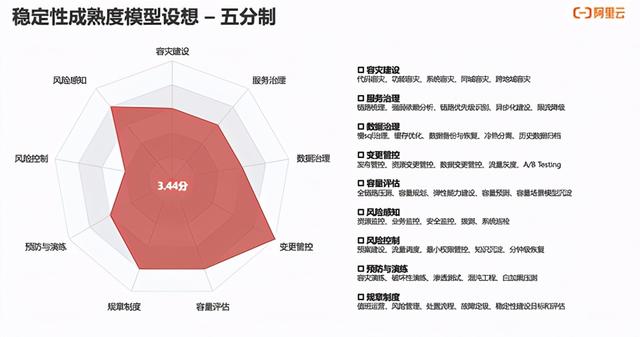 文章插图
文章插图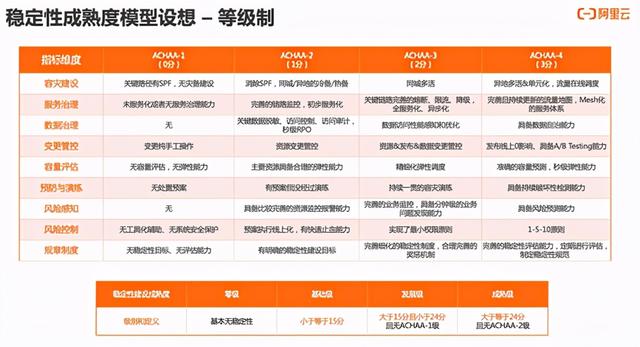 文章插图
文章插图
再给大家快速的介绍一些稳定性建设的一些思路 , 稳定性工作的本质无外乎是发现风险和消除风险的过程 , 风险来自于本身系统和产品遗留的潜在风险、长期使用导致的系统腐坏风险、新功能发布和系统升级引入的风险、大促之类的活动带来的风险等 , 我们的稳定性工作就是让这些风险可控 。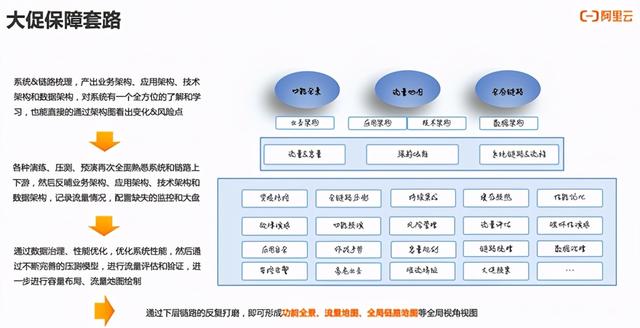 文章插图
文章插图
当然保障还有一大利器就是基于阿里云的稳定性建设体系 , 阿里云提供从资源到方法论全链路的稳定性产品和方案 , 我们有在行业内排名前列的客户 , 仅凭少量的SRE同学 , 就能基于阿里云的各种高可用能力 , 提供非常高效稳定完善的系统保障 。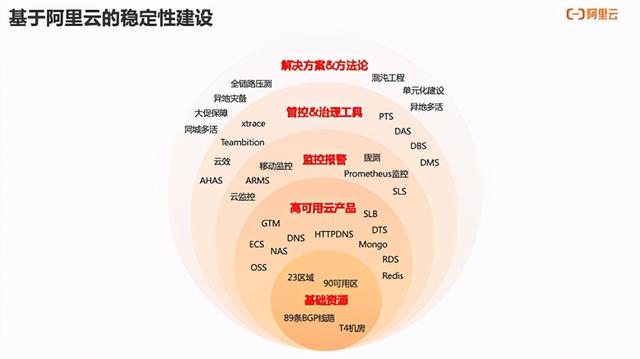 文章插图
文章插图
二、电商高可用架构演进和大促保障经验分享第二位分享嘉宾是阿里巴巴高可用架构团队的高级技术专家中亭 , 他是多活容灾&故障演练团队负责人 。 2011年加入阿里 , 2015年担任双11负责人 , 目前负责阿里巴巴经济体高可用领域的保障及商业化产品的输出工作 。 文章插图
文章插图
据中亭介绍 , 目前 , 高可用领域的技术产品通过两个云服务向外输出 , 分别是PTS(性能压测)和AHAS(应用高可用) 。 在阿里内部 , 准备一次双11是一个非常复杂的超级工程 , 如果业务特别复杂 , 可能涉及几十个甚至上百个横纵型项目 。 不过从围绕大促本身这个技术问题 , 需要解决的问题包括容量、架构、组织等 。 围绕这三个问题 , 中亭介绍了高可用技术的演进历史和技术选型 , 并给出了基于云的高可用解决方案:
- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- Win10系统桌面|手机桌面秒变Win10电脑系统,这波操作太给力了!
- 系统|电子邮箱系统哪家好?邮箱登陆入口是?
- 色卡|双人场景/多机位色彩匹配,色卡很重要
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 计算机学科|机器视觉系统是什么
- 系统|vivo系统迎来“大换血”,OriginOS体验报告来了
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 共建全场景智慧 释放智数广州新活力