编译器|解析卷积的高速计算中的细节,一步步代码带你飞( 三 )
缓存
RAM是一个大而慢的存储器 。 CPU缓存的速度要快几个数量级 , 但要小得多 , 因此正确使用它们至关重要 。 但是没有明确的指令说“加载数据以缓存” 。 它是一个由CPU自动管理的进程 。
每次从主存中获取数据时 , CPU都会自动将数据及其相邻的内存加载到缓存中 , 希望利用引用的局部性 。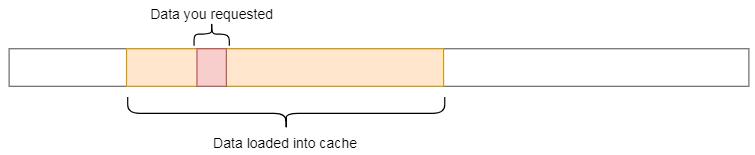 文章插图
文章插图
你应该注意的第一件事是我们访问数据的模式 。 我们在A上按行遍历 , 在B上按列遍历 。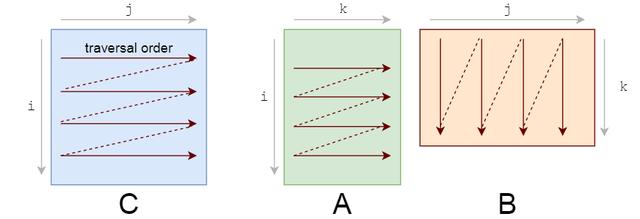 文章插图
文章插图
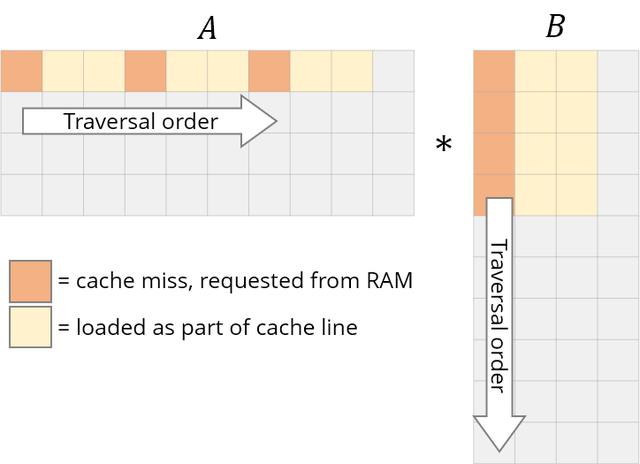
它们的存储也是行主序的 , 所以一旦找到A[i, k] , 行中的下一个元素A[i, k+1]就已经缓存了 。 酷 。 但看看B会发生什么:
- 该列的下一个元素没有出现在缓存中—在获取数据的时候 , 我们得到一个cache miss和CPU stalls 。
- 一旦数据被获取 , 缓存也被填充在同一行B的其他元素 。 我们实际上不会使用它们 , 所以它们很快就会被驱逐 。 经过几次迭代之后 , 当实际需要它们时 , 我们将再次获取它们 。 我们正在用不需要的值污染缓存 。
 文章插图
文章插图我们需要重新设计循环来利用这种缓存能力 。 如果正在读取数据 , 我们不妨利用它 。 这是我们要做的第一个更改:循环重新排序 。
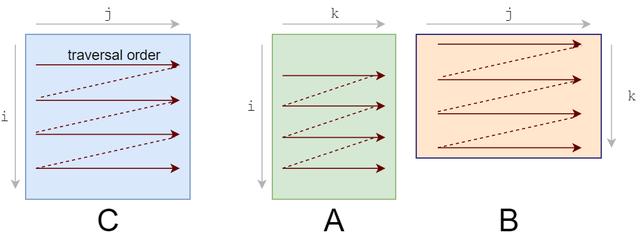
让我们重新排序循环 , 从i,j,k到i,k,j:
for i in 0..M: for k in 0..K: for j in 0..N:我们的答案仍然是正确的 , 因为乘法/加法的顺序无关紧要 。 遍历顺序现在看起来是这样的:
 文章插图
文章插图这个简单的改变 , 只是重新排序了一下循环 , 给了一个相当快的加速:
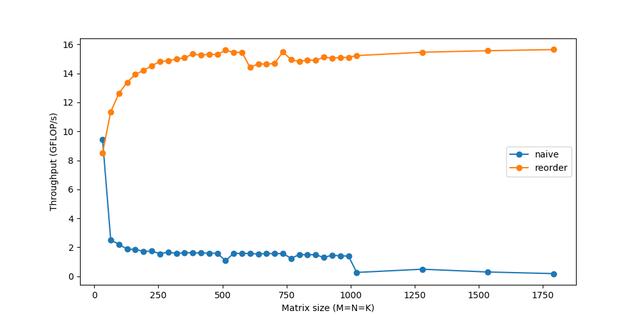 文章插图
文章插图Tiling
为了进一步改进重新排序 , 我们还需要考虑一个缓存问题 。
对于A的每一行 , 我们循环遍历整个B 。 在B中每进行一步 , 我们将加载它的一些新列并从缓存中删除一些旧列 。 当我们到达A的下一行时 , 我们从第一列开始重新开始 。 我们重复地从缓存中添加和删除相同的数据 , 这叫做抖动 。
如果我们所有的数据都能放入缓存 , 就不会发生抖动 。 如果我们使用更小的矩阵 , 他们就可以幸福地生活在一起 , 而不会被反复驱逐 。 谢天谢地 , 我们可以分解子矩阵上的矩阵乘法 。 计算一个C中的小的r×c块 , 只需要A中的r行和B中的C列 。 让我们把C分成6x16的小块 。
C(x, y) += A(k, y) * B(x, k);C.update() .tile(x, y, xo, yo, xi, yi, 6, 16)/* in pseudocode: for xo in 0..N/16: for yo in 0..M/6: for yi in 6: for xi in 0..16: for k in 0..K: C(...) = ... */我们已经把x,y的维度分解成外部的xo,yo和内部的xi,yi 。 我们将努力为较小的6x16块(标记为xi,yi)优化一个微内核 , 并在所有块上运行该微内核(由xo,yo迭代) 。
Vectorizationout(x, y) = matrix_mul(x, y); out.tile(x, y, xi, yi, 24, 32) .fuse(x, y, xy).parallel(xy) .split(yi, yi, yii, 4) .vectorize(xi, 8) .unroll(xi) .unroll(yii); matrix_mul.compute_at(out, yi) .vectorize(x, 8).unroll(y); matrix_mul.update(0) .reorder(x, y, k) .vectorize(x, 8) .unroll(x) .unroll(y) .unroll(k, 2);总结一下 , 它是这样做的:
- 分裂成32x24的小块 。 进一步将每个tile分成8x24个子tile
- 在临时缓冲区(matrix_mul)中计算8x24的matmul , 使用类似的重新排序、向量化和展开
- 使用矢量化、展开等方法将临时的matrix_mul复制回out 。
- 在所有32x24块上并行化这个过程
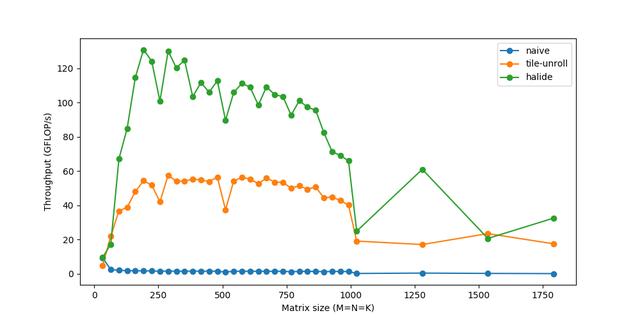 文章插图
文章插图最后 , 我们能够达到超过120GFLOPs的速度—相当接近160 GFLOPs的峰值性能 , 并且能够匹配OpenBLAS等生产级库 。 使用类似的im2col微调代码 , 然后是gemm , 相同的卷积现在运行时间为~20ms 。 如果你对这方面的研究感兴趣 , 可以尝试使用你自己的不同策略—作为一名工程师 , 我总是听到关于缓存、性能等方面的说法 , 看到它们的真实效果可能是有益的和有趣的 。
注意 , 这种im2col+gemm方法是大多数深度学习库中流行的通用方法 。 然而 , 定制化是关键——对于特定的常用大小、不同的体系结构(GPU)和不同的操作参数(如膨胀、分组等) , 这些库可能会再次使用针对这些情况的类似技巧或假设进行更定制化的实现 。 这些微内核是经过反复试验和错误的高度迭代过程构建的 。 程序员通常只对什么应该/不应该工作得很好有一种直觉 , 并且/或者必须基于结果考虑解释 。 听起来很适合深度学习研究 , 对吧?
- 工程师|AWS偏爱Rust,已将Rust编译器团队负责人收入囊中
- 高像素|加持高像素只为解析力?vivo S7丛林秘境展对样张细节的要求更严苛
- 用了就停不下来,解析全网视频,不仅免费还能下载
- 详解mysql执行计划
- 在美国当快递小哥赚钱吗?西瓜视频解析除了努力,运气也很重要
- 标识|食品行业工业互联网标识解析二级节点、“星火·链网”骨干节点在漯河上线
- Lock、Synchronized锁区别解析
- 人体|用于单目3D人体姿态估计的局部连接网络,克服图卷积网络限制
- 原图|怎么批量解析下载京东商品详情页的原图图片
- 头部产品|出版单位当下面临的问题及解析