析取程序合成:一种通过示例编程的健壮方法( 四 )
使用析取方法时 , 我们需要考虑更一般的条件作为防止过度拟合的析取 , 但是我们不能包括所有可能性 , 因为如引言中所述 , 在 Web DSL 中(图 3)过滤算子的可能析取条件 c 呈指数形式 。 取而代之的是 , 我们描述了一种用于析取的学习策略 , 其中考虑了满足规范的最大(最具体)以及一组最小(最小限制性)析取 。
评估:我们已经使用 Microsoft PROSE 程序合成框架为文本和 Web 提取域实现了用于析取程序合成的 DSL 和算法 。 在本节中 , 我们报告了从一组对 PBE 技术感兴趣的产品团队获得的结果 , 该团队对从电子邮件中提取信息的 PBE 技术感兴趣 。 用户通常会定期从同一提供商那里收到电子邮件 , 例如航班行程 , 酒店预订或购买收据 , 并且产品团队希望使用 PBE 功能 , 该功能允许用户创建工作流程以在收到新电子邮件时提取重要内容 。 用户可以通过突出显示现有电子邮件中的重要字段来为 PBE 系统提供示例 。 但是 , 在这种情况下 , 仅靠 Web 提取 DSL 是不够的 , 因为许多提供的基准都包括从 HTML 中的节点提取子字符串 。 因此 , 我们通过合并 Web 和文本 DSL 的析取 DSL 满足了这些基准 , 因此提取程序首先选择一个节点 , 然后对其文本内容执行子字符串提取 。
我们获得的基准涵盖了来自 8 个不同提供商的 47 个提取任务 。 34 个任务需要提取节点内容上的子字符串 , 而不仅仅是提取节点选择 。 对于每个提取任务 , 我们大约有 10 个输入和所需输出的测试实例 。 在每种情况下 , 输入都是电子邮件 , 输出是要提取的字段的文本字符串 , 例如航班确认电子邮件中的航班号 。
产品团队的重要考虑因素是系统学习功能强大的程序 , 这些程序不会轻易因新输入而失效 。 我们使用的鲁棒性度量是为给定任务学习正确的程序所需的最少示例数量 。 更确切地说 , 最少的示例数是作为示例要提供给系统的输入输出实例的最小数目 , 以使它合成的程序在所有其余实例上都可以成功 。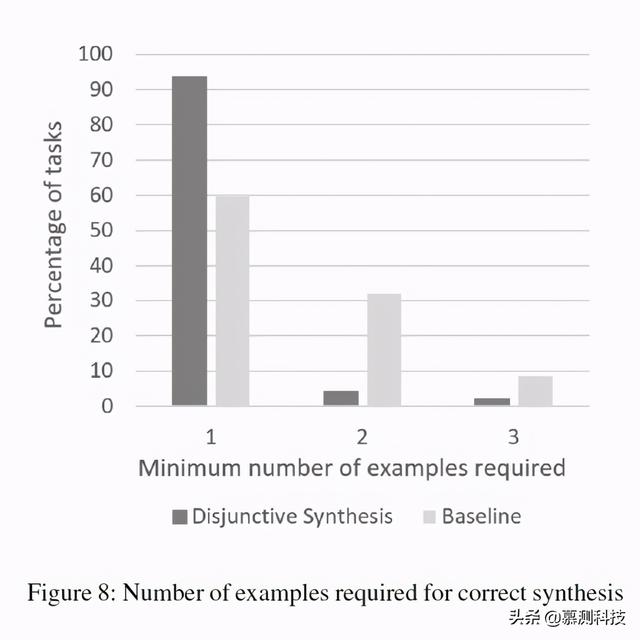 文章插图
文章插图
我们根据不包含在同一 DSL 中的任何析取运算符的基准评估了析取学习系统 。 图 8 显示了我们的析取方法和基准所需要的最少示例数的比较 。总而言之 , 使用我们的析取方法 , 从一个示例中学到正确程序的任务比例从 59.6%增加到 93.6% 。
我们注意到 , 这些结果显示了学习正确程序所需的最少示例数量 , 而不是用户实际上在实践中可能给出的示例数量 , 而实际数量可能更多 。 这是因为用户不知道哪些示例对系统有用 , 尽管他们可能会努力给出更多示例 , 但当系统无法处理将来的某些电子邮件时 , 他们可能只会遇到相关或有用的示例 。 不知道给出哪个示例的不确定性使得要求一个或多个示例对于用户体验和产品质量非常重要 。
在性能方面 , 析取程序的平均速度降低了 2.9 倍 , 这是可以预期的 , 因为析取程序在考虑多个替代分支时会执行更多的计算 。 但是 , 分离性案例中的大多数测试实例都在不到半秒的时间内完成 , 所有实例都在不到 2 秒的时间内完成 。
总结:在本文中 , 我们解决了在学习时可能无法提供代表性输入的情况下 , 通过示例系统进行编程的一次性学习问题 , 并提出了一种新的计算模型 , 用于从示例中进行程序合成 。 传统的基于示例的合成面临的主要挑战是应对用户提供的少量示例固有的歧义 , 因为这些示例可能无法代表输入域中的所有可能变化 。 现有的合成系统需要从有限的训练数据中学习程序 , 并且被迫做出过早的决定 , 以选择一个程序 , 而不是满足给定示例的其他程序 。相反 , 我们建议将该决定推迟到需要的时候:在程序执行时(当执行输入可用时) , 而不是训练或合成时 。 我们的计算模型是程序的析取模型 , 其中排序决策是在程序执行时做出的 , 作为不同析取函数之间的选择 , 评分函数由评分函数控制 , 评分函数根据它们在给定输入上生成的输出来挑选析取函数 。 基于功能的评分功能根据 DSL 中包含的一组功能 , 从程序中分离出一个程序 , 该程序产生的输出与训练输出最相似 。
致谢【析取程序合成:一种通过示例编程的健壮方法】本文由南京大学软件学院 2020 级硕士研究生刘智彪翻译转述
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 联网时代|34岁转行做程序员是否还有成功的机会
- 内容|怎样才能让你的小程序留住更多用户
- 微信广告|小程序开发者看过来 流量变现倍增的秘籍来了!
- 每日|【每日idea 分享】12月1日:带朋友一起网上购物;线上笔记本应用程序
- 启信|人民数据与启信宝联合成立金融数据中心
- TOP100|2020年10月全网小程序TOP100榜单
- 二维码|扫了“清粉”程序二维码后,微信竟成“傀儡”