析取程序合成:一种通过示例编程的健壮方法
 文章插图
文章插图
摘要通过示例编程(PBE)系统允许终端用户提供一些输入输出示例来指定他们的任务 , 从而轻松地创建程序 。 该系统尝试使用满足给定示例的特定领域语言(DSL)生成程序 。 然而 , 现有 PBE 技术面临的主要挑战是确保从少量示例中合成的程序的鲁棒性 , 这些程序在面对新输入时经常会失效 。 这是因为可能存在许多满足少量示例的可能程序 , 并且 PBE 系统必须在无用户提供的任何其他信息的情况下 , 在这些候选项之间进行排名 , 并选择一个正确的选项 。 在这项工作中 , 我们提出了一种不同的 PBE 方法 , 这种方法使系统避免了在合成阶段做出排名决策 , 而是合成了包含排名最高的一些程序作为替代方案的析取程序 , 并在新的输入执行时对这些程序进行选择 。 这种延迟选择带来了重大好处 , 即在执行时比较给定输入上不同析取程序所产生的可能输出 。 我们提出了一种在任意 DSL 中合成这种析取程序的通用框架 , 并描述了从纯文本和 HTML 文档提取数据的实际领域中析取程序合成的两种具体实现 。 我们的评估显示我们的方法所实现的鲁棒性显著提高 , 例如可以从一个示例中学习到正确程序的任务从 59%增加到 93% 。
引言PBE 系统允许用户通过给出所需任务的一些输入输出示例来指定其意图 , 系统将尝试从中自动生成满足给定示例的领域特定语言(DSL)的程序 。 PBE 并非透明地自动执行一次性任务 , 而是以通用编程语言生成轻量级脚本 , 这些脚本可以由用户在不同环境中保存和重用 , 而与用于生成这些脚本的学习技术无关 。
近年来 , PBE 方法已引起人们极大的兴趣和进展 。 但是 , 当前系统面临的关键挑战是 , 从几个示例中推断出的程序通常鲁棒性不够好 , 并且在输入新内容时容易失效 。 这是因为候选的程序(由 DSL 定义)的状态空间很大 , 因为我们需要支持覆盖不同任务的表达性程序 , 因此可以有许多可能的程序满足用户提供的给定示例集 。 这种表达能力与正确性之间的权衡是 PBE 系统设计中的主要挑战 , 这就是为什么研究人员一直在努力改善 PBE 系统中使用的排名 , 以选择用户想要的最可能的程序 。
但是 , 无论排名技术多么出色 , 这种方法从定义上都限制了系统从许多可能性中选择一个选项 。 在这项工作中 , 我们基于在合成时不过早地选择单一程序的思想 , 探索了针对此鲁棒性问题的不同的方法 。 当我们有更多信息时 , 将这种排名决定推迟到程序的执行是有益的 。 我们通过来自文本提取和 Web 提取的两个实际应用领域中的方案来说明此想法 。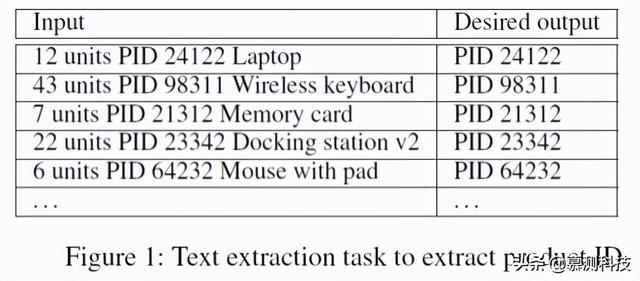 文章插图
文章插图
图 1 展示了一种数据处理场景 。 其中用户希望删除输入列中产品 ID 之后的任意描述 , 如输出列所示 。 在这个示例中 , 基于正则表达式(例如 Flash Fill)的 PBE 系统可以生成许多可能的令人满意的程序 , 这些程序采用不同的子字符串提取逻辑 。 检测提取的子字符串结尾的可能逻辑包括“最后一个数字的末尾”(P1),“第二个数字的末尾(P2)” , “在大写字母和空格后第一个数字的结尾”(P3)以及其他复杂的表达式 。 由于大多数 PBE 系统中的排名通常都倾向于简化性 , 因此在这种情况下 , 系统选择逻辑 P1 。 但是 , 此特定逻辑在第 4 行失败 , 在该行的输入末尾碰巧还有另一个数字 。 因此 , 程序 P2 或 P3 会更适合于此任务 , 但是只有在第 4 行遇到不合格的输入时 , 我们才意识到这一点 , 实际上 , 该输入可能在数据中的任何地方 , 甚至在不同的数据集之中 。
我们还注意到 , 选择一个更好的程序不仅仅是改善排名系统的问题 , 因为总的来说 , 没有一种适用于所有情况的排名策略 。根据数据集的可变性 , 可能没有一个逻辑可以满足所有行 , 但是有可能将不同的逻辑应用于不同的行以解决整个任务 。
因此 , 我们观察到脆弱性来自于在合成阶段限制提取逻辑的特定选择 。 在本文中 , 我们建议不要从排名靠前的程序 P1 的列表中过早地在合成算法中强制执行单一选择 P1,....Pn , 我们可以学习一个更健壮的包含所有选择项 P1,....Pn 的析取程序 , 执行新的输入并在这些不同选项之间进行选择 。 因此 , 通过这种分离方法 , 我们可以延迟使用哪种特定逻辑的选择 , 直到获得有关执行输入是什么的重要信息 , 并且可以比较不同逻辑产生的输出 。
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 联网时代|34岁转行做程序员是否还有成功的机会
- 内容|怎样才能让你的小程序留住更多用户
- 微信广告|小程序开发者看过来 流量变现倍增的秘籍来了!
- 每日|【每日idea 分享】12月1日:带朋友一起网上购物;线上笔记本应用程序
- 启信|人民数据与启信宝联合成立金融数据中心
- TOP100|2020年10月全网小程序TOP100榜单
- 二维码|扫了“清粉”程序二维码后,微信竟成“傀儡”