索引|优化Python代码的4种方法( 二 )
(注:英文原文的代码可以直接运行 , 在文章末尾有英文原文的链接)
结果极大的节省了时间 , 这就是优化Python代码的重要性 。 我们不仅节省时间 , 而且还可以节省很多计算资源!
你可能想知道这些如何应用于数据科学项目 。 你可能已经注意到 , 很多时候我们必须对大量数据点执行相同的查询 。 在数据预处理阶段尤其如此 。
我们必须使用一些优化的技术而不是基本的编程来尽可能快速高效地完成工作 。 因此 , 这里我将分享一些我用来改进和优化Python代码的最佳技术
1. Pandas.apply() | 特征工程的钻石级函数
Pandas已经是一个高度优化的库 , 但是我们大多数人仍然没有充分利用它 。 现在你思考一下在数据科学中会使用它的常见地方 。
我能想到的一项是特征工程 , 我们使用现有特征创建新特征 。 最有效的方法之一是使用Pandas.apply() 。
在这里 , 我们可以传递用户定义的函数 , 并将其应用于Pandas序列化数据的每个数据点 。 它是Pandas库中最好的插件之一 , 因为此函数可以根据所需条件选择性隔离数据 。 所以 , 我们可以有效地将其用于数据处理任务 。
让我们使用Twitter情绪分析数据来计算每条推文的字数 。 我们将使用不同的方法 , 例如dataframe iterrows方法 , NumPy数组和apply方法 。 你可以从此处下载数据集(;utm_medium=4-methods-optimize-python-code-data-science) 。
'''优化方法:apply方法'''# 导入库import pandas as pd import numpy as npimport timeimport mathdata = http://kandian.youth.cn/index/pd.read_csv('train_E6oV3lV.csv')# 打印头部信息print(data.head())# 使用dataframe iterows计算字符数print('\n\nUsing Iterrows\n\n')start_time = time.time()data_1 = data.copy()n_words = []for i, row in data_1.iterrows(): n_words.append(len(row['tweet'].split()))data_1['n_words'] = n_words print(data_1[['id','n_words']].head())end_time = time.time()print('\nTime taken to calculate No. of Words by iterrows :',(end_time-start_time),'seconds')# 使用Numpy数组计算字符数print('\n\nUsing Numpy Arrays\n\n')start_time = time.time()data_2 = data.copy()n_words_2 = []for row in data_2.values: n_words_2.append(len(row[2].split()))data_2['n_words'] = n_words_2print(data_2[['id','n_words']].head())end_time = time.time()print('\nTime taken to calculate No. of Words by numpy array : ',(end_time-start_time),'seconds')# 使用apply方法计算字符数print('\n\nUsing Apply Method\n\n')start_time = time.time()data_3 = data.copy()data_3['n_words'] = data_3['tweet'].apply(lambda x : len(x.split()))print(data_3[['id','n_words']].head())end_time = time.time()print('\nTime taken to calculate No. of Words by Apply Method : ',(end_time-start_time),'seconds')(注:英文原文的代码可以直接运行 , 在文章末尾有英文原文的链接 , 同上)
你可能已经注意到apply方法比iterrows方法快得多 。 其性能可媲美与NumPy数组 , 但apply方法提供了更多的灵活性 。 你可以在此处阅读apply方法的文档 。 ()
2. Pandas.DataFrame.loc | Python数据处理的技巧
这是我最喜欢的Pandas库的技巧之一 。 我觉得对于处理数据任务的数据科学家来说 , 这是一个必须知道的方法(所以几乎每个人都是这样!)
大多数时候 , 我们只需要根据某些条件来更新数据集中特定列的某些值 。 Pandas.DataFrame.loc为我们提供了针对此类问题的最优化的解决方案 。
让我们使用loc函数解决一个问题 。 你可以在此处下载将要使用的数据集() 。
# 导入库import pandas as pddata = http://kandian.youth.cn/index/pd.read_csv('school.csv')data.head()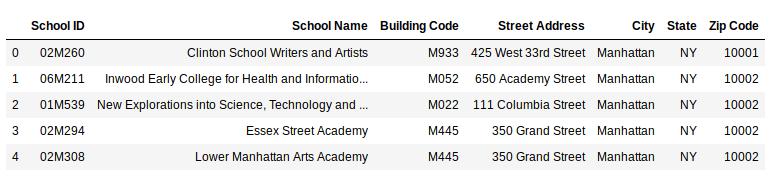 文章插图
文章插图
检查“City”变量的各个值的频数: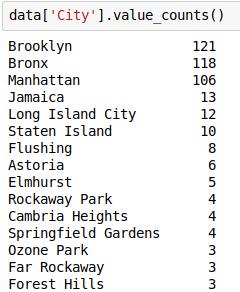 文章插图
文章插图
现在 , 假设我们只需要排名前5位的城市 , 并希望将其余城市替换为“Others”(其他)城市 。 因此 , 让我们这么写:
# 将热门城市保存在列表中top_cities = ['Brooklyn','Bronx','Manhattan','Jamaica','Long Island City']# 使用loc更新目标data.loc[(data.City.isin(top_cities) == False),'City'] = 'Others'# 各个城市的频数data.City.value_counts()文章插图
Pandas来更新数据的值是非常容易的!这是解决此类数据处理任务的最优化方法 。
3.在Python中向量化你的函数
摆脱慢循环的另一种方法是对函数进行向量化处理 。 这意味着新创建的函数将应用于输入列表 , 并将返回结果数组 。 Python中的向量化可以加速计算
让我们在相同的Twitter Sentiment Analysis数据集对此进行验证 。
'''优化方法:向量化函数'''# 导入库import pandas as pd import numpy as npimport timeimport mathdata = http://kandian.youth.cn/index/pd.read_csv('train_E6oV3lV.csv')# 输出头部信息print(data.head())def word_count(x) : return len(x.split())# 使用Dataframe iterrows 计算词的个数print('\n\nUsing Iterrows\n\n')start_time = time.time()data_1 = data.copy()n_words = []for i, row in data_1.iterrows(): n_words.append(word_count(row['tweet']))data_1['n_words'] = n_words print(data_1[['id','n_words']].head())end_time = time.time()print('\nTime taken to calculate No. of Words by iterrows :',(end_time-start_time),'seconds')# 使用向量化方法计算词的个数print('\n\nUsing Function Vectorization\n\n')start_time = time.time()data_2 = data.copy()# 向量化函数vec_word_count = np.vectorize(word_count)n_words_2 = vec_word_count(data_2['tweet'])data_2['n_words'] = n_words_2print(data_2[['id','n_words']].head())end_time = time.time()print('\nTime taken to calculate No. of Words by numpy array : ',(end_time-start_time),'seconds')
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 人工智能|人工智能只会“优化”,而人类可以“进化”
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- 极致优化 IDEA 启动速度(本文内容过于硬核)
- Python中文速查表-Pandas 基础