索引|优化Python代码的4种方法
介绍
我是一个程序员 。 从大学时代开始我就一直在进行编程 , 而我仍然对使用简单的Python代码所开辟的道路之多感到惊讶 。
但是我并不总是那么高效 。 我相信这是大多数程序员(尤其是刚起步的程序员)共有的一个特征 , 编写代码的快感始终优先于效率和简洁性 。 虽然这在我们的大学期间有效 , 但在专业环境中 , 尤其是在数据科学项目中 , 情况却大相径庭 。 文章插图
文章插图
作为数据科学家 , 编写优化的Python代码非常非常重要 。 杂乱 , 效率低下的代码即浪费你的时间甚至浪费你项目的钱 。 经验丰富的数据科学家和专业人员都知道 , 当我们与客户合作时 , 杂乱的代码是不可接受的 。
因此 , 在本文中 , 我将借鉴我多年的编程经验来列出并展示四种可用于优化数据科学项目中Python代码的方法 。
优化是什么?
首先定义什么是优化 。 我们将使用一个直观的示例进行此操作 。
这是我们的问题:
假设给定一个数组 , 其中每个索引代表一个城市 , 该索引的值代表该城市与下一个城市之间的距离 。 假设我们有两个索引 , 我们需要计算这两个索引之间的总距离 。 简单来说 , 我们需要找到两个给定索引之间距离的总和 。 文章插图
文章插图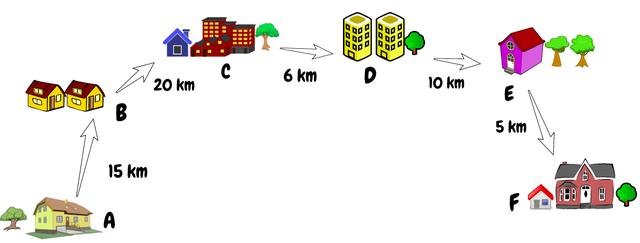 文章插图
文章插图
首先想到的是 , 一个简单的FOR循环在这里可以很好地工作 。 但是 , 如果有100,000多个城市 , 而我们每秒接收50,000多个查询 , 该怎么办?你是否仍然认为FOR循环可以为我们的问题提供足够好的解决方案?
FOR循环并不能提供足够好的方案 。 这时候优化就派上用场了
简单地说 , 代码优化意味着在生成正确结果的同时减少执行任何任务的操作数 。
让我们计算一下FOR循环执行此任务所需的操作数: 文章插图
文章插图
我们必须在上面的数组中找出索引1和索引3的城市之间的距离 。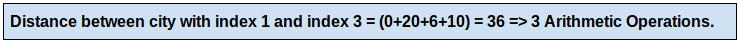 文章插图
文章插图
对于较小的数组大小 , 循环的性能良好
如果数组大小为100,000 , 查询数量为50,000 , 该怎么办? 文章插图
文章插图
这是一个很大的数字 。 如果数组的大小和查询数量进一步增加 , 我们的FOR循环将花费大量时间 。 你能想到一种优化的方法 , 使我们在使用较少数量的解决方案时可以产生正确的结果吗?
在这里 , 我将讨论一个更好的解决方案 , 通过使用前缀数组来计算距离来解决这个问题 。 让我们看看它是如何工作的: 文章插图
文章插图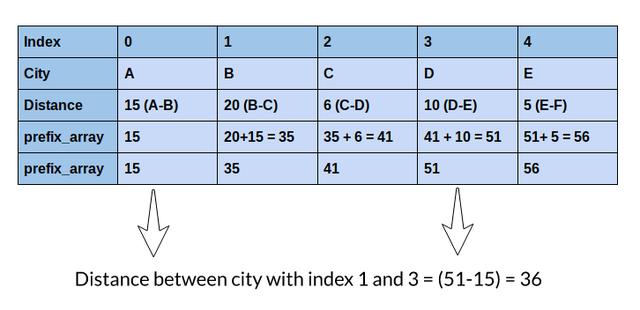 文章插图
文章插图 文章插图
文章插图
你能理解吗?我们只需一次操作就可以得到相同的距离!关于此方法的最好之处在于 , 无论索引之间的差是1还是100,000 , 都只需执行一个操作即可计算任意两个索引之间的距离 。
我创建了一个样本数据集 , 其数组大小为100,000和50,000个查询 。 你可以自己执行代码来比较两者所用的时间
注意:数据集总共有50,000个查询 , 你可以更改参数execute_queries以执行最多50,000个查询 , 并查看每种方法执行任务所花费的时间 。
import timefrom tqdm import tqdmdata_file = open('sample-data.txt', 'r')distance_between_city = data_file.readline().split()queries = data_file.readlines()print('SIZE OF ARRAY = ', len(distance_between_city))print('TOTAL NUMBER OF QUERIES = ', len(queries))data_file.close()# 分配要执行的查询数execute_queries = 2000print('\n\nExecuting',execute_queries,'Queries')# FOR循环方法# 读取文件并存储距离和查询start_time_for_loop = time.time()data_file = open('sample-data.txt', 'r')distance_between_city = data_file.readline().split()queries = data_file.readlines()# 存储距离的列表distances_for_loop = []# 计算开始索引和结束索引之间的距离的函数def calculateDistance(startIndex, endIndex): distance = 0 for number in range(startIndex, endIndex+1, 1): distance += int(distance_between_city[number]) return distancefor query in tqdm(queries[:execute_queries]): query = query.split() startIndex = int(query[0]) endIndex = int(query[1]) distances_for_loop.append(calculateDistance(startIndex,endIndex))data_file.close()# 获取结束时间end_time_for_loop = time.time()print('\n\nTime Taken to execute task by for loop :', (end_time_for_loop-start_time_for_loop),'seconds')# 前缀数组方法# 读取文件并存储距离和查询start_time_for_prefix = time.time()data_file = open('sample-data.txt', 'r')distance_between_city = data_file.readline().split()queries = data_file.readlines()# 存储距离列表distances_for_prefix_array = []# 创建前缀数组prefix_array = []prefix_array.append(int(distance_between_city[0]))for i in range(1, 100000, 1): prefix_array.append((int(distance_between_city[i]) + prefix_array[i-1]))for query in tqdm(queries[:execute_queries]): query = query.split() startIndex = int(query[0]) endIndex = int(query[1]) if startIndex == 0: distances_for_prefix_array.append(prefix_array[endIndex]) else: distances_for_prefix_array.append((prefix_array[endIndex]-prefix_array[startIndex-1]))data_file.close()end_time_for_prefix = time.time()print('\n\nTime Taken by Prefix Array to execute task is : ', (end_time_for_prefix-start_time_for_prefix), 'seconds')# 检查结果correct = Truefor result in range(0,execute_queries): if distances_for_loop[result] != distances_for_prefix_array[result] : correct = Falseif correct: print('\n\nDistance calculated by both the methods matched.')else: print('\n\nResults did not matched!!')
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 人工智能|人工智能只会“优化”,而人类可以“进化”
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- 极致优化 IDEA 启动速度(本文内容过于硬核)
- Python中文速查表-Pandas 基础