MQ消息中间件,面试能问些什么?( 六 )
3)消费端弄丢了数据
rabbitmq如果丢失了数据 , 主要是因为你消费的时候 , 刚消费到 , 还没处理 , 结果进程挂了 , 比如重启了 , 那么就尴尬了 , rabbitmq认为你都消费了 , 这数据就丢了 。
这个时候得用rabbitmq提供的ack机制 , 简单来说 , 就是你关闭rabbitmq自动ack , 可以通过一个api来调用就行 , 然后每次你自己代码里确保处理完的时候 , 再程序里ack一把 。 这样的话 , 如果你还没处理完 , 不就没有ack?那rabbitmq就认为你还没处理完 , 这个时候rabbitmq会把这个消费分配给别的consumer去处理 , 消息是不会丢的 。
往期面试题汇总:001期~150期汇总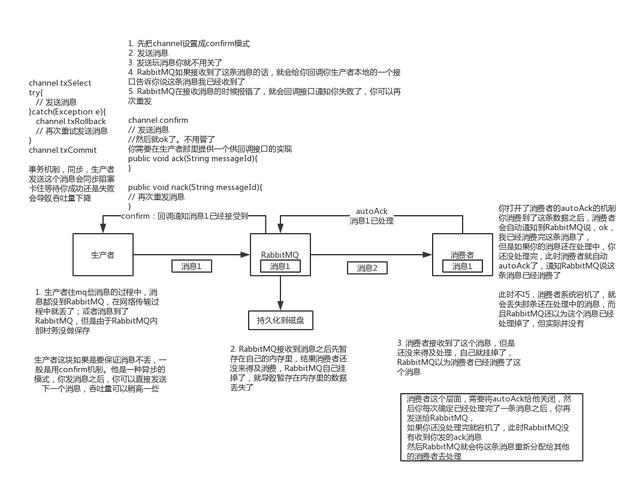 文章插图
文章插图
(2)kafka1)消费端弄丢了数据
唯一可能导致消费者弄丢数据的情况 , 就是说 , 你那个消费到了这个消息 , 然后消费者那边自动提交了offset , 让kafka以为你已经消费好了这个消息 , 其实你刚准备处理这个消息 , 你还没处理 , 你自己就挂了 , 此时这条消息就丢咯 。
这不是一样么 , 大家都知道kafka会自动提交offset , 那么只要关闭自动提交offset , 在处理完之后自己手动提交offset , 就可以保证数据不会丢 。 但是此时确实还是会重复消费 , 比如你刚处理完 , 还没提交offset , 结果自己挂了 , 此时肯定会重复消费一次 , 自己保证幂等性就好了 。
生产环境碰到的一个问题 , 就是说我们的kafka消费者消费到了数据之后是写到一个内存的queue里先缓冲一下 , 结果有的时候 , 你刚把消息写入内存queue , 然后消费者会自动提交offset 。
然后此时我们重启了系统 , 就会导致内存queue里还没来得及处理的数据就丢失了
2)kafka弄丢了数据
这块比较常见的一个场景 , 就是kafka某个broker宕机 , 然后重新选举partiton的leader时 。 大家想想 , 要是此时其他的follower刚好还有些数据没有同步 , 结果此时leader挂了 , 然后选举某个follower成leader之后 , 他不就少了一些数据?这就丢了一些数据啊 。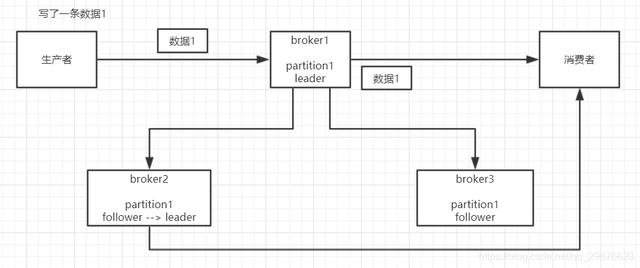 文章插图
文章插图
生产环境也遇到过 , 我们也是 , 之前kafka的leader机器宕机了 , 将follower切换为leader之后 , 就会发现说这个数据就丢了
所以此时一般是要求起码设置如下4个参数:
- 给这个topic设置replication.factor参数:这个值必须大于1 , 要求每个partition必须有至少2个副本
- 在kafka服务端设置min.insync.replicas参数:这个值必须大于1 , 这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系 , 没掉队 , 这样才能确保leader挂了还有一个follower吧
- 在producer端设置acks=all:这个是要求每条数据 , 必须是写入所有replica之后 , 才能认为是写成功了
- 在producer端设置retries=MAX(很大很大很大的一个值 , 无限次重试的意思):这个是要求一旦写入失败 , 就无限重试 , 卡在这里了
3)生产者会不会弄丢数据
如果按照上述的思路设置了ack=all , 一定不会丢 , 要求是 , 你的leader接收到消息 , 所有的follower都同步到了消息之后 , 才认为本次写成功了 。 如果没满足这个条件 , 生产者会自动不断的重试 , 重试无限次 。
1. 如何保证消息的顺序性?其实这个也是用MQ的时候必问的话题 , 第一看看你了解不了解顺序这个事儿?第二看看你有没有办法保证消息是有顺序的?这个生产系统中常见的问题 。
我举个例子 , 我们以前做过一个mysql binlog同步的系统 , 压力还是非常大的 , 日同步数据要达到上亿 。 mysql -> mysql , 常见的一点在于说大数据team , 就需要同步一个mysql库过来 , 对公司的业务系统的数据做各种复杂的操作 。
你在mysql里增删改一条数据 , 对应出来了增删改3条binlog , 接着这三条binlog发送到MQ里面 , 到消费出来依次执行 , 起码得保证人家是按照顺序来的吧?不然本来是:增加、修改、删除;你楞是换了顺序给执行成删除、修改、增加 , 不全错了么 。
本来这个数据同步过来 , 应该最后这个数据被删除了;结果你搞错了这个顺序 , 最后这个数据保留下来了 , 数据同步就出错了 。
先看看顺序会错乱的俩场景
(1)rabbitmq:一个queue , 多个consumer , 这不明显乱了
- 采用|消息称一加9系列将推出三款新机,新增一加9E
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 好消息|好消息!双十二实体店消费券已经开领
- 出炉|三星S11最新消息出炉,S10沦为百元机,星粉:服了
- 网络|最新消息!2020年后Flash Player搭载重橙网络继续运营
- 人工智能|最新消息,人工智能解决了长达50年的生物学难题,一个巨大的突破
- 深圳市智信|消息称华为员工进驻新荣耀没有 1.7 倍收入补偿
- 追踪|消息称三星正研发名为“Galaxy Smart Tag”的物体追踪器
- 玻璃|消息称三星Galaxy Z Fold3定价与三星Z Fold2相同,或将配备UTG超薄玻璃
- 三年Java开发,刚从美团、京东、阿里面试归来,分享个人面经