对迁移学习中域适应的理解和3种技术的介绍
作者:Harsh Maheshwari
编译:ronghuaiyang
导读
我们的目标是在一个标签可用的数据集(源)上训练神经网络 , 并在另一个标签不可用的数据集(目标)上保证良好的性能 。
域适应是计算机视觉的一个领域 , 我们的目标是在源数据集上训练一个神经网络 , 并确保在显著不同于源数据集的目标数据集上也有良好的准确性 。 为了更好地理解域适应和它的应用 , 让我们先看看它的一些用例 。
- 我们有很多不同用途的标准数据集 , 比如GTSRB用于交通标志识别 , LISA和LARA dataset用于交通信号灯检测 , COCO用于目标检测和分割等 。 然而 , 如果你想让神经网络很好地完成你的任务 , 比如识别印度道路上的交通标志 , 那么你必须首先收集印度道路的所有类型的图像 , 然后为这些图像做标注 , 这是一项费时费力的任务 。 在这里我们可以使用域适应 , 因为我们可以在GTSRB(源数据集)上训练模型 , 并在我们的印度交通标志图像(目标数据集)上测试它 。
- 在很多情况下 , 很难收集数据集 , 这些数据集具有训练鲁棒神经网络所需的所有变化和多样性 。 在这种情况下 , 在不同的计算机视觉算法的帮助下 , 我们可以生成具有我们需要的所有变化的大型合成数据集 。 然后在合成数据集(源数据集)上训练神经网络 , 并在真实数据集(目标数据集)上测试它 。
因此在域适应方面 , 我们的目标是在一个标签可用的数据集(源)上训练神经网络 , 并在另一个标签不可用的数据集(目标)上保证良好的性能 。
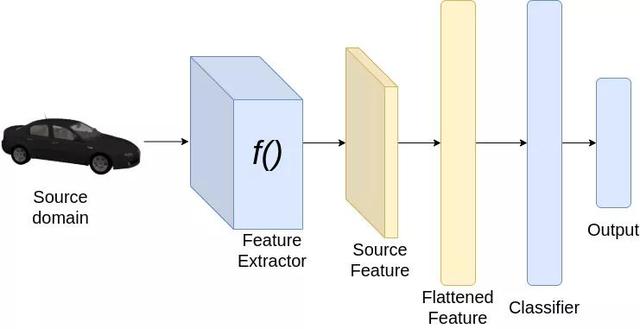 文章插图
文章插图分类pipeline
现在让我们看看如何实现我们的目标 。 考虑以上图像分类的例子 。 为了从一个域适应到另一个域 , 我们希望我们的分类器能够很好地从源数据集和目标数据集中提取特征 。 由于我们已经在源数据集上训练了神经网络 , 分类器必须在源数据集上表现良好 。 然而 , 为了使分类器在目标数据集上表现良好 , 我们希望从源数据集和目标数据集提取的特征是相似的 。 因此 , 在训练时 , 我们加强特征提取 , 为源和目标域图像提取相似的特征 。
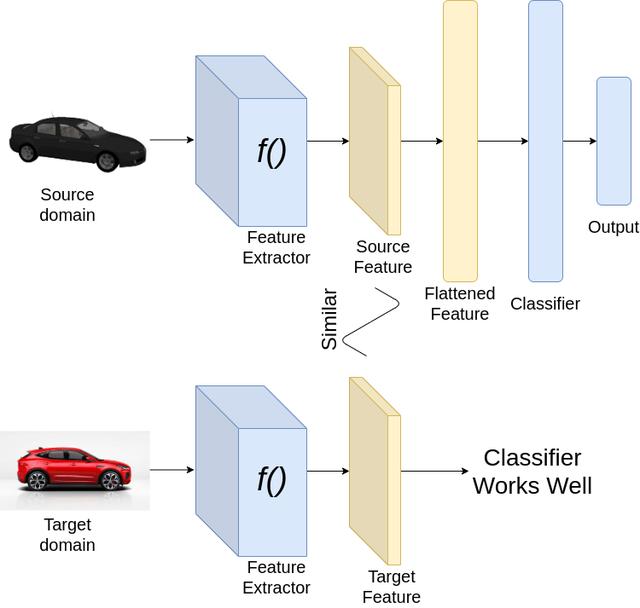 文章插图
文章插图成功的域适应
基于目标域的域自适应类型根据目标域提供的数据类型 , 域适应可分为以下几类:
- 监督 — 你已经标记了来自目标域的数据 , 目标域数据集的大小比源数据集小得多 。
- 半监督 — 你既有目标域的标记数据也有未标记数据 。
- 无监督的 — 你有很多目标域的未标记样本 。
- 基于分布的域适应
- 基于对抗性的域适应
- 基于重建的域适应
基于分布的域适应基于散度的域适应原理是最小化源与目标分布之间的散度准则 , 从而得到域不变性特征 。 常用的分布准则有对比域描述、相关对齐、最大平均差异(MMD) , Wasserstein等 。 为了更好地理解这个算法 , 让我们先看看一些不同的分布 。
在最大平均差异(MMD)中 , 我们试图找出给定的两个样本是否属于相同的分布 。 我们将两个分布之间的距离定义为平均嵌入特征之间的距离 。 如果我们有两个在集合X上的分布P和Q 。 MMD通过一个特征映射来定义 , : X→H , 这里H再生核希尔伯特空间 。 MMD的公式如下:
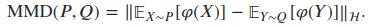 文章插图
文章插图为了更好地了解MMD , 请查看以下描述:如果两个分布的矩相似 , 则它们是相似的 。 通过使用kernel , 我可以对变量进行变换 , 从而计算出所有的矩(一阶 , 二阶 , 三阶等) 。 在潜在空间中 , 我可以计算出矩之间的差值并求其平均值 。
在相关对齐中 , 我们尝试对源和目标域之间的相关(二阶统计量)进行对齐 , 而不是使用MMD中的线性变换对均值进行对齐 。
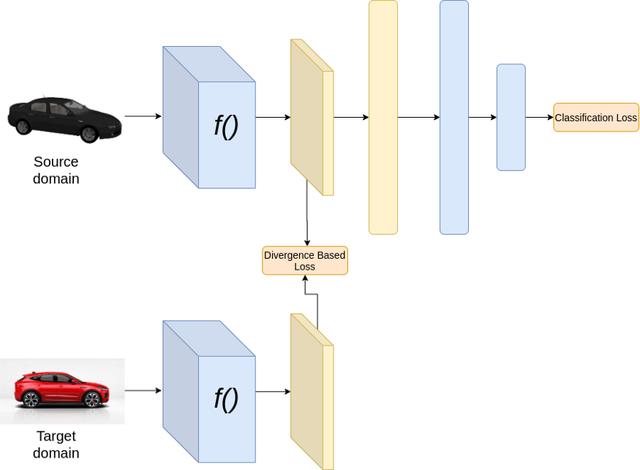 文章插图
文章插图训练时
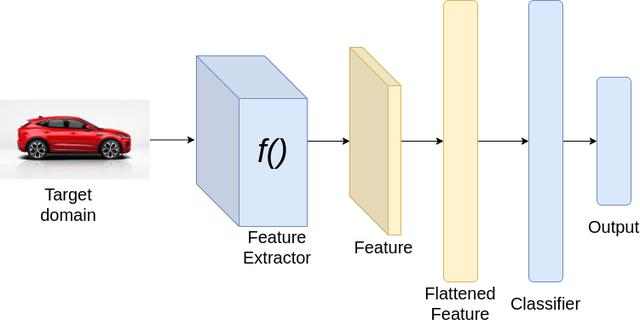 文章插图
文章插图【对迁移学习中域适应的理解和3种技术的介绍】推理时
上面的结构假设源域和目标域有相同的类别 。 在上述架构中 , 在训练过程中 , 我们最小化了两种损失 , 分类损失和基于散度的损失 。 分类损失通过对特征提取器和分类器的权值进行更新 , 确保获得良好的分类性能 。 而散度损失则通过更新特征提取器的权值来保证源域和目标域的特征相似 。 在推理过程中 , 我们只需将目标域图像通过神经网络 。
- 纠结|硬杠红米Note9Pro?iQOO Z1跌至1575,对比之后纠结了!
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 时尚先生|小米雷军成2020年最出圈企业家:获时尚双刊年度人物
- 电信|巴西电信协会及运营商发文 反对限制华为5G
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 区企联企协|谋求更高质量的转型发展!区企联企协与区科技局成功举办科技考察对接活动
- 中国|对越南新增投资18亿?把30%的生产线转移?富士康真要跑了?