按关键词阅读: CPU 安卓 GPU 飞利浦·斯塔克

文章图片
文章图片

文章图片

作为一款VR实时操作游戏App , 我们需要根据重力感应系统 , 实时监控手机的角度 , 并渲染出相应位置的VR图像 , 因此在不同 Android 设备之间 , 由于使用的芯片组和不同架构的GPU , 游戏性能会因此受到影响 。 举例来说:游戏在 Galaxy S20+ 上可能以 60fps 的速度渲染 , 但它在HUAWEI P50 Pro上的表现可能与前者大相径庭 。由于新版本的手机具有良好的配置 , 而游戏需要考虑基于底层硬件的运行情况 。
如果玩家遇到帧速率下降或加载时间变慢 , 他们很快就会对游戏失去兴趣 。 如果游戏耗尽电池电量或设备过热 , 我们也会流失处于长途旅行中的游戏玩家 。 如果提前预渲染不必要的游戏素材 , 会大大增加游戏的启动时间 , 导致玩家失去耐心 。 如果帧率和手机不能适配 , 在运行时会由于手机自我保护机制造成闪退 , 带来极差的游戏体验 。
基于此 , 我们需要对代码进行优化以适配市场上不同手机的不同帧率运行 。
所遇到的挑战 首先我们使用Streamline 获取在 Android 设备上运行的游戏的配置文件 , 在运行测试场景时将 CPU 和 GPU性能计数器活动可视化 , 以准确了解设备处理 CPU 和 GPU 工作负载 , 从而去定位帧速率下降的主要问题 。
以下的帧率分析图表显示了应用程序如何随时间运行 。
在下面的图中 , 我们可以看到执行引擎周期与 FPS 下降之间的相关性 。 显然GPU 正忙于算术运算 , 并且着色器可能过于复杂 。
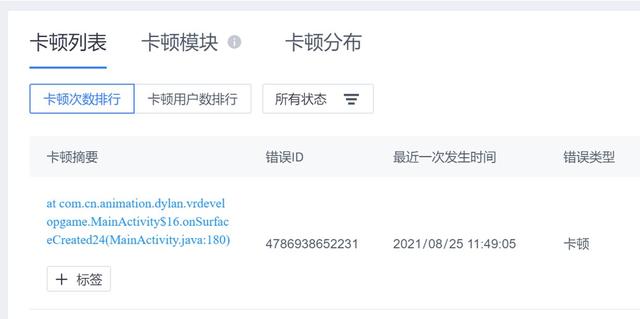
为了测试在不同设备中的帧率情况 , 使用友盟+U-APM测试不同机型上的卡顿状况 , 发现在onSurfaceCreated函数中进行渲染时出现卡顿 ,应证了前文的分析 , 可以确定GPU是在算数运算过程中发生了卡顿:
因为不同设备有不同的性能预期 , 所以需要为每个设备设置自己的性能预算 。 例如 , 已知设备中 GPU 的最高频率 , 并且提供目标帧速率 , 则可以计算每帧 GPU 成本的绝对限制 。
数学公式: $ 每帧 GPU 成本 = GPU 最高频率 / 目标帧率 $
CPU到 GPU 的调度存在一定的约束 , 由于调度上存在限制所以我们无法达到目标帧率 。 另外 , 由于 CPU-GPU 接口上的工作负载序列化 , 渲染过程是异步进行的 。 CPU 将新的渲染工作放入队列 , 稍后由 GPU 处理 。
数据资源问题 CPU控制渲染过程并且实时提供最新的数据 , 例如每一帧的变换和灯光位置 。 然而 , GPU 处理是异步的 。 这意味着数据资源会被排队的命令引用 , 并在命令流中停留一段时间 。 而程序中的OpenGL ES 需要渲染以反映进行绘制调用时资源的状态 , 因此在引用它们的 GPU 工作负载完成之前无法修改资源 。
调试过程 我们曾做出尝试 , 对引用资源进行代码上的编辑优化 , 然而当我们尝试修改这部分内容时 , 会触发该部分的新副本的创建 。 这将能够一定程度上实现我们的目标 , 但是会产生大量的 CPU 开销 。
于是我们使用Streamline查明高 CPU 负载的实例 。 在图形驱动程序内部libGLES_Mali.so路径函数 视图中看到极高的占用时间 。
由于我们希望在不同手机上适配不同帧率运行 , 所以需要查明libGLES_Mali.so是否在不同机型的设备上都产生了极高的占用时间 , 此处采用了友盟+U-APM来检测用户在不同机型上的函数占用比例 。
经友盟+ U-APM自定义异常测试 , 下列机型会产生高libGLES_Mali.so占用的问题 , 因此我们需要基于底层硬件的运行情况来解决流畅性问题 , 同时由于存在问题的机型不止一种 , 我们需要从内存层面着手 , 考虑如何调用较少的内存缓存区并及时释放内存 。
解决方案及优化 基于前文的分析 , 我们首先尝试从缓冲区入手进行优化 。 单缓冲区方案? 使用glMapBufferRange和GL_MAP_UNSYNCHRONIZED.然后使用单个缓冲区内的子区域构建旋转 。 这避免了对多个缓冲区的需求 , 但是这一方案仍然存在一些问题 , 我们仍需要处理管理子区域依赖项 , 这一部分的代码给我们带来了额外的工作量 。 多缓冲区方案? 我们尝试在系统中创建多个缓冲区 , 并以循环方式使用缓冲区 。 通过计算我们得到了适合的缓冲区的数目 , 在之后的帧中 , 代码可以去重新使用这些循环缓冲区 。 由于我们使用了大量的循环缓冲区 , 那么大量的日志记录和数据库写入是非常有必要的 。 但是有几个因素会导致此处的性能不佳:1. 产生了额外的内存使用和GC压力2. Android 操作系统实际上是将日志消息写入日志而并非文件 , 这需要额外的时间 。 3. 如果只有一次调用 , 那么这里的性能消耗微乎其微 。 但是由于使用了循环缓冲区 , 所以这里需要用到多次调用 。 我们会在基于c#中的 Mono 分析器中启用内存分配跟踪函数用于定位问题:![]()
稿源:(阿里云云栖号)
【傻大方】网址:http://www.shadafang.com/c/11159615462021.html
标题:GPU|如何用 GPU硬件层加速优化Android系统的游戏流畅度