按关键词阅读:
编辑导语:在业务分析过程中,你应该选择实时数据还是离线数据?这需要依据业务场景来进行判断,不能盲目选择。那么,二者的优缺点是什么?各自适合应用于什么场景?本篇文章里,作者针对如何选择离线数据和实时数据这一问题做了解答,一起来看一下。

文章插图
做数据和用数据的人绕不开的问题是数据的时效性,离线数据、实时数据分别指的是什么,业务应用时,究竟该以什么标准选择呢?很多业务产品或运营搞不懂两者的区别。提数据分析需求,想着肯定越实时越好,数据团队怎样拒绝?
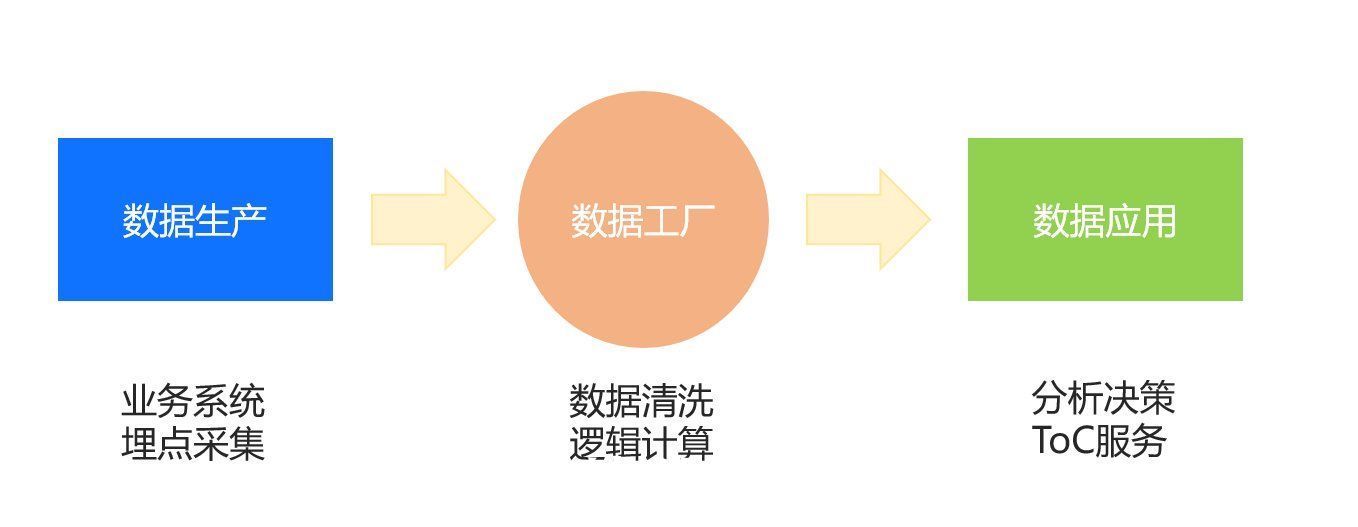
一、什么是离线数据、实时数据?数据从业务端产生,到分析或者反哺业务使用,需要经过一系列的清洗、处理过程,而这一过程带来时间窗口大小,就是数据的时效性。按照数据延迟的大小,可以将数据分为离线数据和以及实时数据(准实时)。
文章插图
1. 离线数据离线数据一般是指T-1的日期,例如今天的日期T=2021-11-12,那么数据结果中,能够体现的业务数据只包括前一天的(昨日数据)。有人也称之为T+1的数据,把数据日期当作T,叫法不同,但本质都是指的今天处理的数据最新日期是截止昨天。
2. 实时数据实时数据主要是指的数据延迟小,例如毫秒、秒、分钟级的延迟,小时级的延迟称之为“准实时数据“更为准确了。例如,你熬夜赶在双十一晚上的最后1分钟,成功付了尾款,在双十一实时统计大屏中,GMV的值又滚动了一下。

文章插图
二、处理技术有何差异1. 离线数据处理离线数据处理也称之为“批处理”,数据产生之后,不会立即进行清洗,而是在固定的周期进行ETL,例如每天在凌晨12:00之后,处理前一天产生的数据。上大学的时候,有的舍友喜欢将袜子攒起来,一个星期洗一次,这就是批处理的思想。
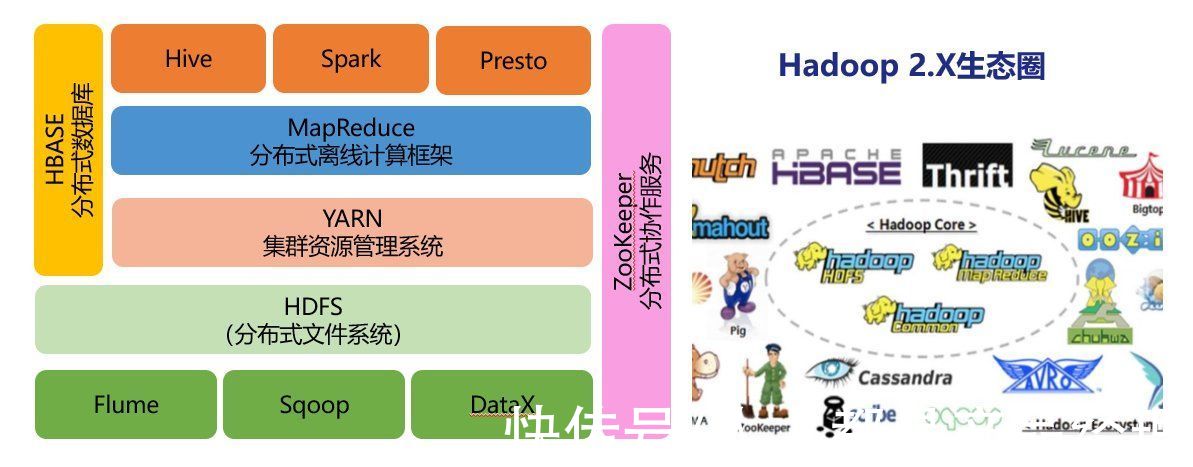
离线数据处理技术是大数据发展更早,目前已经非常成熟的一套体系,最常见是Hadoop,它是一个能够对大量数据进行分布式处理的软件框架。以一种可靠、高效、可伸缩的方式进行数据处理。核心组件是HDFS、MapReduce、Hive。以HDFS进行数据存储,Mapreduce计算,Hive进行数据仓库建设或者基于HiveSQL进行数据查询。
主要优点是:
- 能够处理的数据量巨大,从企业成立以来的历史数据,都可以存储、计算处理、分析应用。
- 数据更准确,对于一些交易类的业务,存在订单状态流转,例如酒店,用户早上下了订单,但是下午有突发情况行程有变,取消了。在离线数据处理时,取当天订单成功状态,就不会计算在内。但对于数据漂移,即12点前下单,12点后取消的情况,就也无法统计到了,这种情形,在数据清洗任务处理时,可以采用全量更新的方式,每日更新全部数据,取最终的订单状态。
离线数据的缺点也很明显,就是慢。今天的数据,要隔天(明天)才能看得到。
文章插图
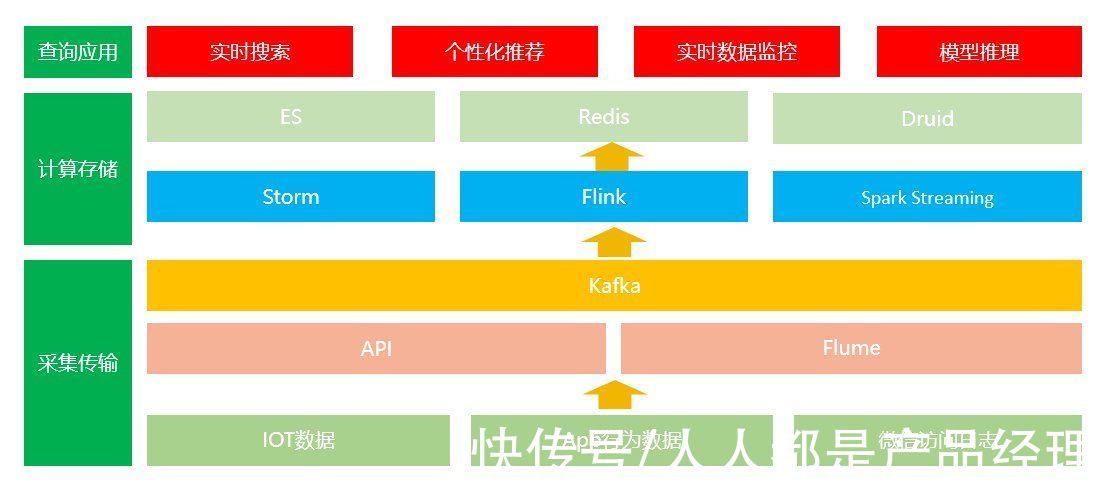
2. 实时数据处理技术实时数据处理,也称之为“流式”数据处理,数据像水流一样每时每刻源源不断地产生后,就立即被清洗处理。这就好比,穿的袜子脏了就洗,今日事今日毕,而不是都攒着。
实时数据一般是业务端即席产生(水源),通过Kafka等消息通道(水流管道)进行传输,利用Storm或flink等实时组件进行消费处理。例如,双十一统计每秒钟的订单数。
主要优点:
数据时效性强,可以做到秒级或者毫秒级时延,“所见即所得”。
缺点
- 需要不停地进行数据计算,即每秒钟或者每分钟进行数据清洗和计算,集群资源消耗大。离线数据处理,任务一天跑一次,一次1小时,实时数据处理每分钟跑一次,一天24小时都在跑。
- 数据周期短,由于是流式处理的方式,相应的组件在实时处理方面能力强,但是没办法存储太长时间的数据,如果容器只进不出,水终究会溢出。因此,一般数据计算的周期会限定在一周内居多。
文章插图
三、离线、实时各自适用的场景是什么,如何选择?【 时效性|一文搞懂:离线数据、实时数据究竟该如何选择】数据的应用场景总结下来其实就是两个,数据分析与数据应用。
1. 在分析方面,数据时效性的选择依据是什么呢?1)业务经营分析、财务分析准确性大于时效性
稿源:(人人都是产品经理)
【傻大方】网址:http://www.shadafang.com/c/11159614R2021.html
标题:时效性|一文搞懂:离线数据、实时数据究竟该如何选择