万字21图!手把手教你设计一个超级牛逼的 Feed 流系统( 二 )
虽然Feed流系统本身可以不需要搜索 , 但是一个Feed流产品必须要有搜索 , 否则信息发现难度会加大 , 用户留存率会大幅下降 。
双向关系时由于关系很紧密 , 一定是按时间排序 , 就算一个关系很紧密的人发了一条空消息或者低价值消息 , 那我们也会需要关注了解的 。
单向关系时 , 那么可能就会存在大V , 大V的粉丝数量理论极限就是整个系统的用户数 , 有一些产品会让所有用户都默认关注产品负责人 , 这种产品中 , 该负责人就是最大的大V , 粉丝数就是用户规模 。 接下来 , 我们看看整个Feed流系统如何设计 。
上一节 , 我们提前思考了Feed流系统的几个关键点 , 接下来 , 在这一节 , 我们自顶向下来设计一个Feed流系统 。
1. 产品定义
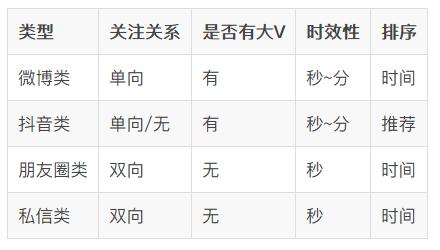
第一步 , 我们首先需要定义产品 , 我们要做的产品是哪一种类型 , 常见的类型有:
- 微博类
- 朋友圈类
- 抖音类
- 私信类
 文章插图
文章插图上述对比中 , 只对比各类产品最核心、或者最根本特点 , 其他次要的不考虑 。 比如微博中互相关注后就是双向关注了 , 但是这个不是微博的立命之本 , 只是补充 , 无法撼动根本 。
从上面表格可以看出来 , 主要分为两种区分:
- 关注关系是单向还是双向:
如果是单向 , 那么可能就会存在大V效应 , 同时时效性可以低一些 , 比如到分钟级别;
如果是双向 , 那就是好友 , 好友的数量有限 , 那么就不会有大V , 因为每个人的精力有限 , 他不可能主动加几千万的好友 , 这时候因为关系更精密 , 时效性要求会更高 , 需要到秒级别 。
- 排序是时间还是推荐:
用户对feed流最容易接受的就是时间 , 目前大部分都是时间 。
但是有一些场景 , 是从全网数据里面根据用户的喜好给用户推荐和用户喜好度最匹配的内容 , 这个时候就需要用推荐了 , 这种情况一般也会省略掉关注了 , 相对于关注了全网所有用户 , 比如抖音、头条等 。 确定了产品类型后 , 还需要继续确定的是系统设计目标:需要支持的最大用户数是多少?十万、百万、千万还是亿?
2. 存储
我们先来看看最重要的存储 , 不管是哪种同步模式 , 在存储上都是一样的 , 我们定义用户消息的存储为存储库 。 存储库主要满足三个需求:
- 可靠存储用户发送的消息 , 不能丢失 。 否则就找不到自己曾经发布到朋友圈状态了 。
- 读取某个人发布过的所有消息 , 比如个人主页等 。
- 数据永久保存 。
- 数据可靠、不丢失 。
- 由于数据要永久保存 , 数据会一直增长 , 所以要易于水平扩展 。
 文章插图
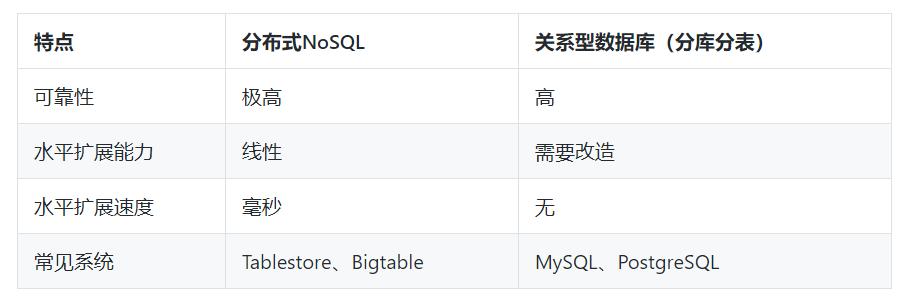
文章插图- 对于可靠性 , 分布式NoSQL的可靠性要高于关系型数据库 , 这个可能有违很多人的认知 。 主要是关系型数据库发展很长时间了 , 且很成熟了 , 数据放在上面大家放心 , 而分布式NoSQL数据库发展晚 , 使用的并不多 , 不太信任 。 但是 , 分布式NoSQL需要存储的数据量更多 , 对数据可靠性的要求也加严格 , 所以一般都是存储三份 , 可靠性会更高 。 目前在一些云厂商中的关系型数据库因为采用了和分布式NoSQL类似的方式 , 所以可靠性也得到了大幅提高 。
- 水平扩展能力:对于分布式NoSQL数据库 , 数据天然是分布在多台机器上 , 当一台机器上的数据量增大后 , 可以通过自动分裂两部分 , 然后将其中一半的数据迁移到另一台机器上去 , 这样就做到了线性扩展 。 而关系型数据库需要在扩容时再次分库分表 。
- 如果是自建系统 , 且不具备分布式NoSQL数据库运维能力 , 且数据规模不大 , 那么可以使用MySQL , 这样可以撑一段时间 。
- 占营收|华为值多少钱
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 公式|?有人把 5G 讲得这么简单明了
- 截长|手机截图怎么截长图
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- 长庚君|向小米公司致歉
- “天河优创”放榜
- 页面|流程图怎样画?老板要我帮他做个组织结构图